




为什么要对“一致性”这个概念单独用一讲来专门进行深入分析呢?
因为这个概念用的实在是太普遍了,这个概念在各种角色的人群里面都反复被提出来,而且有时候大家的理解还都不近相同。比如系统使用者会经常讲:为什么我在你们的购物网站进行个人账户充值操作后,银行卡里的钱实际已经被扣款了,但是个人账户里面余额却没有增加呢,为啥会出现不一致呢,不是一个扣款金额成功之后,另外一个就实时增加相应的金额么?又比如该网站的研发人员在接到该用户的投诉之后也会进行解释到:我们的A地和B地的网络又出现了光缆被挖掘机挖断的情况,A地区的用户的个人账户查询获取到的个人账户信息可能不是最新的数据,这块我们已经采用了一致性算法来保证跨地区节点的数据复制,不用担心等光缆修复之后,用户的数据就能保证最终一致了。
粗看起来两个人说的“一致”可能是一个概念,但细琢磨起来却不太相同。后者说的一致性算法其实指的是英文中的“consensus”这个词,而前者说的则是通常我们数据库里面和CAP中的都用的“consistency”这个单词。
所以为了避免混淆,我们尽量在涉及到诸如Paxos、Raft、ZAB这些分布式协议时候一定要采用“共识”来表示以加以区分。
分布式系统中的一致性概念
假设上述所述场景中,用户的账户服务是一个分布式部署,也就是账户服务同一个jar包被分别部署在二个地区A地区和B地区,其中A地区为节点1,B地区有二个节点分别是节点2和节点3。
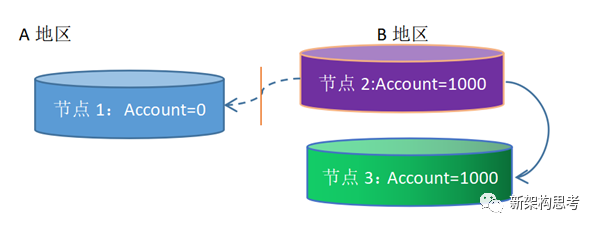
由于该用户恰好在B地区出差,在出差回A地区之前进行账户充值1000的操作,假设此时用户操作调用的账户服务是节点2执行的,转入账户Account中1000元操作成功,节点2成功后分别复制数据1000元到节点3和节点1,节点3也在B地区很快同步成功,而节点1由于挖掘机施工造成网络中断,使得A地区的节点1没有同步成功,还是原来初始的0元。
当该用户以很短的时间返回到A地区之后,此时AB地区的网络还没有恢复,用户在A地区查询账户余额又恰好是节点1的服务执行的查询,发现余额是0,出现了异常。这种情况反映的其实就是分布式节点的一致性问题。
CAP Theorem: Revisited一文中对一致性的概念有了清晰的概念描述:Consistency :A read is guaranteed to return the most recent write for a givenclient.就是说对于一个分布式系统,一个客户端的读操作一定能读取到最新的已经发生的写操作的最新数据。
论文Gilbert and Lynch. Brewer’sconjecture and the feasibility of consistent, available, partition-tolerant webservices.中Gilbert和Lynch对一致性的描述是这样的:“...any read operation that begins after a write operation completesmust return that value, or the result of a later write operation.This is the consistency guarantee that generally provides the easiest model for users to understand...”这段话的含义是指:在写操作完成之后开始的任何读操作都必须返回该值,或以后写操作的结果。这种一致性保证,通常对用户来说是最容易理解的一致性模型。
CAP定理的一致性简介
对于上图中的A地区和B地区网络不通的现象,其实就是CAP理论中的分区容忍性(Partition Tolerance)的概念,准确的说,分区容错性指“the system continues to operate despite arbitrary message lossor failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务,也就是说只能是二选一,不可能既提供可用性又提供一致性的服务。上面就是一个简化版的对CAP定理进行说明的例子,由于发生了网络分区,如果客户查询余额可用,那么他查询到的余额就可能是不一致的,当然如果要想满足一致性,就只能当网络故障修复之后,才可以看到最新的余额了。
CAP定理(CAP theorem)又被称作布鲁威尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),只能满足三项中的两项。
具体有关CAP的理论的详细介绍和CAP中可用性和一致性的关系的详细讨论,我们将在后续的章节中继续。
共识算法中的一致性问题
分布式系统中,由于要保证高可用和高扩展能力,因此就必须对一份数据在多个数据节点间进行数据复制存储,通过冗余备份数据来保证数据不会因为单个节点故障而发生数据安全问题,因为多个节点通信交换数据的需要,也就存在各个节点间可能的各种网络故障,消息乱序和消息延迟的情况,也需要将新的节点加入到现有节点集群中。针对这些不确定的情况,如何才能通过一种确定的协议来保证最终所有节点都能针对一项决议或者数值达成共识,这就是分布式共识协议研究的内容。当一个节点的数据发生更改的时候能够根据共识协议最终把这项修改数据同步到其他的大多数节点上并最终生效。共识算法有很多种,常见的主要有paxos,raft,ZAB等等,后续我们有专门的章节进行详细讨论。
数据库ACID中的一致性概念

数据库表在执行转账操作前,张三账户余额是2000,李四的账户余额是1000。如图所示:
Id | Username | Account |
1 | 张三 | 2000 |
2 | 李四 | 1000 |
执行完转账操作1000成功后,数据库表结果,张三余额变为1000,而李四余额变为2000,如图所示:
Id | Username | Account |
1 | 张三 | 1000 |
2 | 李四 | 2000 |
所以数据中一致性通常是跟事务概念一起提出来的,也就是事务就是一系列子操作的集合,这些子操作,只能以原子的方式整体成功提交或者整体失败回滚。一致性就是事务的四个特性ACID里面的C,也就是Consistency 。这里的一致性是指在执行完这个操作之后,不会出现数据的不正确的现象,也就是说张三和李四转账前账户总和是3000,转账之后账户总和还是3000,不能出现张三转账1000之后余额减少了而李四账户余额没有增加的异常情况。
一致性分类
事务一致性
事务一致性其实是数据库的目标,要达到这个确保事务执行结束后,数据库从一个一致状态转变为另一个一致状态的目标,隐藏的含义是事务在执行过程中的中间状态不能被其他事务和应用程序观察到,因为一旦观察到数据就可能会被更改,就可能会出现多个事务之间并发操作,因此可能会出现各种奇怪的不一致的问题,具体事务的并发操作所带来的各种数据异常,如脏读、幻读、不可重复读、写偏序、读偏序等异常。
数据库中也专门采用了各种方法来避免种种不一致的异常,当然如果做到完全的不一致、数据的完全正确无误,这其实还是挺困难的。这就需要事务的其他的几个特性的配合来完成,通过原子性、隔离性以及持久性来保证。后面章节会详细介绍这些异常和避免异常具体采取的一些方法,比如基于锁的事务的并发控制和基于MVCC的快照隔离的并发控制等。
以MySQL 举例,MySQL通过MVCC(MultiVersion Concurrency Control,多版本并发控制)技术,为每个一致性状态生成快照(Snapshot),每个事务看到的都是快照版本对应的一致性状态,从而也就保证了本地事务的中间状态不会被观察到,所以多版本并发控制实际是快照隔离的一种实现技术,Mysql数据库通过这种快照隔离来保证一致性。
目前使用很普遍的Nosql数据库,无论是基于键值对的redis,还是基于文档型的Mongodb,还是基于列式存储的Hbase,都对事务支持有限,所以也就不满足事务一致性了。
分布式一致性
在分布式系统中,无论是分布式文件系统,还是分布式数据库系统,都需要遵循CAP定理这个基本的约束,CAP 里面的C,也就是分布式系统节点间的“一致性”,如上面图所示的,这个一致性其实是指针对分布式节点的操作,进行读取数据的一致性。
分布式系统各节点虽然各自独立,但是又组成一个整体,该整体对外提供统一服务,各个节点之间的协调和同步数据等机制对使用者来说是透明的,也就是使用者不关系具体节点是如何协作的,但是不能出现使用者对数据的读取出现不一致的情况。
在较大规模的分布式系统中,网络分区(network partitions)是一个不可回避的事实。因此CAP就主要成为了AP还是CP的选择问题。如果CAP的C不被满足,则会出现Steal read、Immortal write、Causal reverse等一致性异常。
所谓的一致性都是有附加条件的,而一致性模型主要讨论在满足什么样的条件下即可认为达到一致性。不同的应用场景对一致性要求不一样,因此也就有了不同的一致性模型.
内存一致性
在基于共享内存的系统中的通常我们会遇到两个概念:memory consistency 和 cache coherence。这两个概念要注意英文单词的搭配,但是这两者中文中又分别被翻译为“内存一致性”和“缓存一致性”,其实缓存一致性协议(Cache Coherence Protocol)中,大家耳熟能详的主要就是Intel 的MESI协议,MESI协议保证了CPU多级高速缓存中使用的共享变量的多个副本是一致的。这部分我们不做重点,后续章节后有所介绍,我们主要能看到这些概念能跟分布式一致性和事务一致性加以区分即可。
分布式一致性模型的分类
从通俗的角度理解主要有三种一致性:强一致性、弱一致性和最终一致性。
强一致性(Strong consistency). 一个写操作完成后,后续任何时刻的读操作都将返回写操作更新后的值。理解强一致性可以同jvm中的java关键字volatile对比起来理解。
但是对于用户经常提及的“强一致性”概念并不严谨,在文献《Consistency in Non-Transactional Distributed Storage Systems》中对该概念进行了澄清。该文章指出:
“Hybrid consistency isdefined as a model requiring a concerted adoption of weak and strong consistency semantics. In a hybrid consistent system strong operations are guaranteed to be seen in some sequential order by all processes (as in sequential consistency), while weak operations are designed to be fast, and they eventually become visible by all processes
(much like in eventual consistency).
Weak operations are only guaranteed to be ordered according to their interleaving with strong operations: if two operations belong to the same session and one of them is strong, then their relative order of invocation is respected and visible by all processes.”
可以看出来,是否被“所有进程”可看见,是判断强一致性的标准,而在分布式一致性中,只有线性一致性和顺序一致性满足强一致性的含义。一般将线性一致性又称做严格一致性(Strict consistency)或叫原子一致性(Atomic consistency)。
弱一致性(Weak consistency). 系统不保证后续操作会返回更新的值,后续的读操作可能立刻会返回最新的值,也可能在若干条件满足之后才获取到新的值。从更新发生后到所有使用者保证总能读取到更新后的值的这段时间,称为不一致时间窗口。当然这个不一致时间窗口可长可短,尽管我们希望尽量缩短时间窗口,针对不同的用户使用场景,只要用户对时间不太敏感不影响用户的使用,这个时间窗口即使有些长也是可以接受的。
最终一致性(Eventual consistency). 最终一致性本质上也是一种弱一致性,只是提供最终一致性的系统能够有这样的保证:如果没有新的更改操作发生在数据对象上,最终在某个时刻,也就是超过不一致的时间窗口之后,所有的操作读取访问都将返回最后一次更新后的值。如果没有失败发生,不一致窗口的最大长度取决于通信延时、系统负载、冗余备份数等因素。
在《分布式系统原理与泛型》一书中,主要提出来了基于观察的视角的不同,可以分为基于客户为中心的一致性模型和以数据为中心的的一致性模型。
基于客户为中心的一致性模型划分的方法,是以分布式系统的访问者用户,从用户的视角来看到所存储数据是否一致的。分为单调写一致性(Monotonic write consistency)、单调读一致性(Monotonic read consistency)、读你所写一致性(Read-your-writes consistency)、写跟随读一致性(Writes-follow-reads Consistency)。
单调写一致性(Monotonic write consistency). 系统保证写操作由同一个进程执行。编写不提供这种一致性级别保证的系统是众所周知的困难(Systems that do not guaranteethis level of consistency are notoriously hard to program)。
单调读一致性(Monotonic read consistency). 如果进程已经看到了数据对象特定的值(猜想不一定是最新的值),那么任何后续的访问将不会返回任何先前更新的值。
读你所写一致性(Read-your-writes consistency). 这是一种重要的模型。进程A更新一个数据项之后,再去访问它,总能得到更新后的值,并且不再会看到这个数据项更新之前的值。这是causal consistency模型的特殊形式。
写跟随读一致性(Writes-follow-reads Consistency)。
以数据为中心的一致性模型主要分为因果一致性(Causal consistency)、线性一致性(Linearizability)、顺序一致性(Sequential Consistency)、PRAM一致性(Pipeline Random AccessMemory) 。PRAM一致性又称为FIFO Consistency。
因果一致性(Causal consistency). 如果进程A已经把数据项被更新的消息告诉给了进程B,那么进程B后续的访问将返回更新后的结果,且新的写操作将确保替换掉先前的写操作结果。进程C与进程A之间并没有因果关系(估计作者是指没有进行更新消息的通信),那么进程C对数据的访问结果将取决于一般的最终一致性规则。
一致性汇总地图
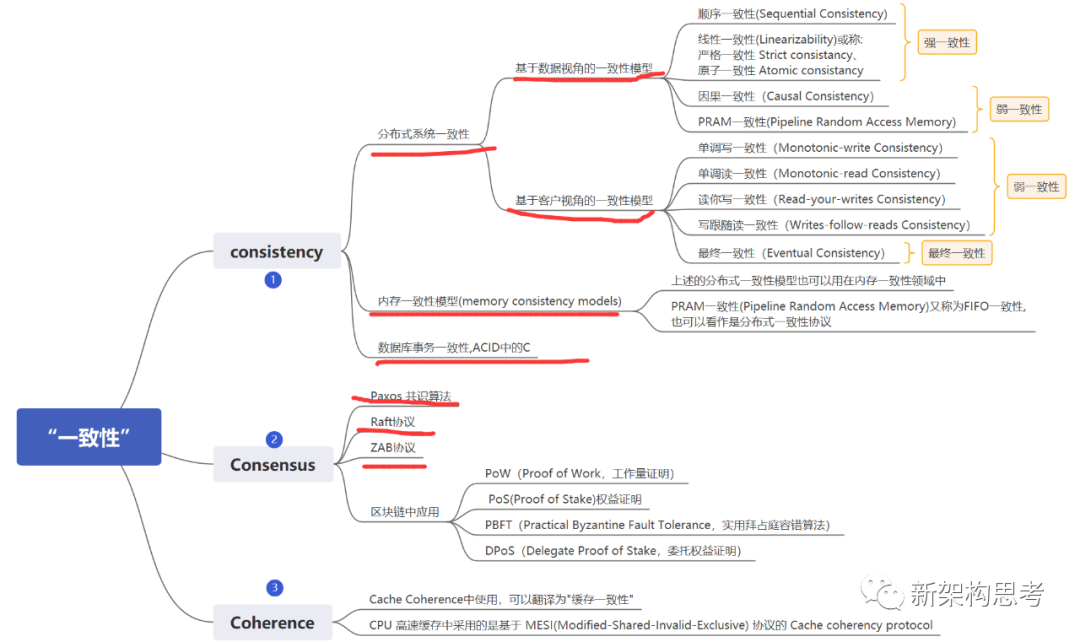
所以当我们听到别人在说一致性这个词的时候,我们需要先判断一下对方说这个词的语境是什么情况,是在说内存的一致性问题,还是在说分布式系统CAP中的一致性问题,还是在说分布式共识协议的一致性问题。如果是说分布式系统的CAP中的一致性问题,那么继续判断是在以用户的角度笼统的来说呢,还是以数据为中心来谈呢,如果是以客户的角度来讲那么我们就可以不必纠结说的准确不准确了,如果是以数据为中心的角度,则需要搞明白是哪种一致性模型,另外如果是讨论事务的一致性问题,则需要判断是说的哪个隔离级别下的数据的一致性,也大概清楚了是在讨论关于数据库的一致性的问题,事务的隔离级别这部分本章节不做讨论,后续有专门章节讨论。

相关文章推荐:
01 | 如何实现自我基础设施新重建-从掌握一致性与分布式事务开始
03 | 分布式事务的产生原因及常见的解决方案(NewSQL、Distributed SQL等)
09 | 概念辨析:分布式系统中的一致性和ACID中一致性概念异同
10 | 从乐观的思路(OCC、MVCC)来看并发控制的技术实现
