




上一讲中,我们首先介绍了数据库事务的隔离级别以及 Spring 框架中的隔离级别,接着介绍了不同的隔离级别可以解决的异常类型。这节课我们聚焦不同隔离级别下事务的一致性和隔离性是如何通过并发控制来实现的,包括并发控制的定义、目的,以及并发控制的内部技术实现。
什么是并发控制?
首先我们需要给并发控制下一个比较合适的定义。所谓并发控制,就是数据库管理系统的并发控制管理器,对并发执行的事务所涉及的基本读写操作,以及其他的加锁、解锁等操作,进行执行顺序的控制,以达到在某个隔离级别下,并发执行事务的正确性,保证不会产生该隔离级别所不允许的数据读写异常。更多内容可参考 What is Concurrency Control?
并发控制的目的什么?
我们知道数据读写异常之所以产生,是因为不同事务的读写操作顺序被打乱后交叉执行。所以并发控制的目的就是,保证多个事务的多个读写操作要按照一个合适的顺序来执行,使得在该顺序下执行所有操作的结果,跟按照事务整体一个个先后顺序执行的结果一样。
所以,并发控制的最终目标还是要保证事务的一致性和隔离性。
并发控制是如何保证事务的一致性和隔离性的?
并发控制是通过数据库的并发控制管理器实现的,其中数据库的并发控制管理器又称为调度器。
并发控制就是借助于调度器,产生冲突可串行化的调度,来保证并发事务执行操作的正确性,从而实现了事务的一致性和隔离性。
下面我们详细解释什么是调度,以及怎么判断一个调度是否是冲突可串行的。
什么是调度?
多个事务的读写基本操作,加上加锁、解锁等其他的控制操作,可能有多种执行顺序,其中的某一个执行顺序,就叫作并发事务的一个调度(Schedule)。调度这个词翻译的不是很通俗易懂,Schedule 这个词的字面含义就是“按照时间列出的计划表”。在这里可以理解为按照时间顺序先后执行的总的操作序列。
我们来举个例子:假设 A 和 B 数据的初始值都是 20,有两个事务 T1 和 T2,分别对这两个数据进行增加 100 和乘以 100 的操作。
其中,事务 T1 的操作顺序为:begin → read(A) → A+100 → write(A) → read(B) → B+100 → write(B) → commit。
事务 T2 的操作顺序为:begin → read(A) → A*100 → write(A) → read(B) → B*100 → write(B) → commit。
如果按照 T1 的操作都在 T2 操作之前执行,两事务串行执行,产生的一个调度为 T1 → T2。
详细如图所示:
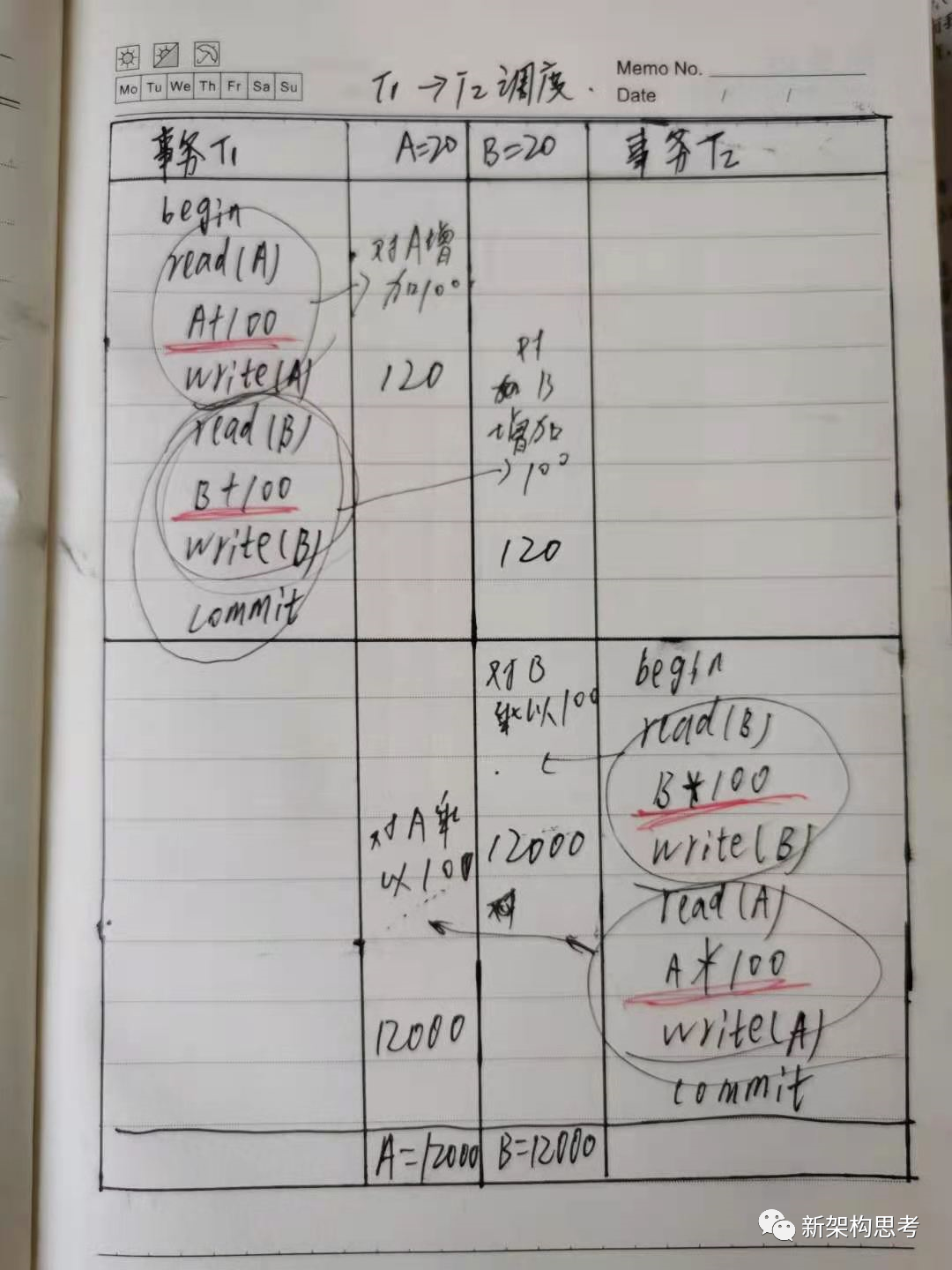
执行后的最终结果是 A=12000,B=12000。
相反,如果 T2 的所有操作都在 T1 之前完成,产生的调度为 T2 → T1,执行后的最终的结果是A=2100,B=2100。
无论 T1 → T2,还是 T2 → T1,都是按照事务的先后顺序来执行的,都属于串行调度。串行调度是所有可能的调度中的一个特例。在实际情况中,两事务内的操作都是交叉并行执行的,这样的调度属于并发调度。对于并发调度的执行结果,可能正确,也可能不正确。
怎样判断一个并发调度是正确的呢?
只有当一个并发调度执行的结果跟串行调度执行的结果完全相同,我们才称这个并发调度是正确的。
在实际中,调度器的目标就是要保证并发调度的正确性。借用管理学大师彼得德鲁克在管理学领域的一句名言:
If you can't measure it,you can't manage it.
对应到并发控制领域,如果不能对事务内部有精确的微观度量,就不可能有宏观的正确结果。如果调度器想判断不同事务的多个操作,按照某一个顺序执行后,是否可以产生正确的结果,就需要对各个读写操作进行精确的评估,判断是否可能在后续的执行过程中产生冲突,如果可能有冲突就避免打乱原先的依赖顺序。
什么是冲突?
在调度中有先后顺序的两个操作,如果这两个操作的顺序调换后的执行结果跟调换前的相同,那么这两个操作就是没有冲突的;反之,如果调换两个操作之后,会影响事务的执行结果,那么这两个操作就是有冲突的,有冲突的操作是不能调换顺序的。
还是以上面的事务 T1 和事务 T2 为例,通过观察我们可以得出以下结论:
事务 T1 的 read(A) 和事务 T2 的 read(A)是没有冲突的;
事务 T1 的 read(A) 和事务 T2 的 write(A) 是有冲突的,因为调换后事务 T1 读取的 A 的值发生了改变,导致最终结果改变。
同理,事务 T1 的 write(A) 和事务 T2 的 write(A) 也是冲突的。
扩展到一般结论,产生冲突的情况如下。
(1)同一个事务的任何两个操作都是冲突的。因为同一个事务的顺序是用户事先确定好的,不能随意改变这个顺序,更改之后就会改变原来的业务逻辑。
(2)不同事务至少有一个写操作,并且操作的是同一个数据元素,肯定是冲突的。
不同事务对同一个元素执行写 - 写操作。因为写 - 写操作会导致后一个操作的结果覆盖前一个操作的结果,会发生丢失更新的异常。
不同事务对同一个元素执行读 - 写操作。当事务 T1 先对 A 执行 read(A) 操作后,事务 T2 对 A 执行 write(A) 操作,会导致不可重复读的异常发生。
不同事务对同一个元素执行写 - 读操作,这种情况可能会导致脏读的异常发生。
当然也存在不冲突的情况,结论如下。
(1)两个事务都是读操作。
(2)两个事务操作的是不同的元素,分别对这两个元素执行读 - 写操作或者写 - 读操作。
(3)两个事务操作的是不同的元素,分别对这两个元素执行写 - 写操作。
区分出来了哪些操作是冲突的,哪些操作是不冲突的之后,就可以对不冲突的操作任意交换次序,而有冲突的操作则避免交换次序。
什么是冲突可串行化的调度?
如果一个调度(记为 S)在保证有冲突的操作次序固定不变的情况下,经过不断交换相邻两个不冲突的操作,最终得到一个串行的调度,则称该调度 S 是冲突可串行化的调度。冲突可串行化的调度等价于串行调度,并且一定是正确的调度。
怎么判断一个调度是否是冲突可串行化的呢?
答案就是优先图法。
解释一下优先图,其实就是一个有向图。关于有向图,学过数据结构的都应该了解,分为顶点和边。对于优先图,顶点是代表一个调度中的事务,边代表事务之间是否有冲突存在。
那怎么构造优先图的边呢?如果事务 T1 和事务 T2 存在依赖关系,并且这两个事务的操作存在冲突,事务 T1 的操作先于事务 T2 的操作,那么就存在一条由事务 T1 指向事务 T2 的边。
针对一个调度 S,我们构造这个调度的优先图,如果该图是无环的,那么调度 S 就是冲突可串行化的;如果有环存在,那么调度 S 就不是冲突可串行化的。
我们再来举个例子:对于一个涉及三个事务 T1、T2、T3 的并发调度 S,假设该调度的顺序如下:
r2(A) → r1(B) → w2(A) → r3(A) → w1(B) → w3(A) → r2(B) → w2(B)。
备注:
ri(A) 表示第 i 个事务对 A 的读操作 read(A);
wi(A) 表示第 i 个事务对 A 的写操作 write(A);
ri(B) 表示第 i 个事务对 B 的读操作 read(B);
wi(B) 表示第 i 个事务对 B 的写操作 write(B)。
观察这个调度会发现有两个写 - 读依赖关系。
先执行“事务 T2 对 A 元素的写操作”,后执行“事务 T3 对 A 元素的读操作”。
先执行“事务 T1 对 B 元素的写操作”,后执行“事务 T2 对 B 元素的读操作”。
如下图所示:
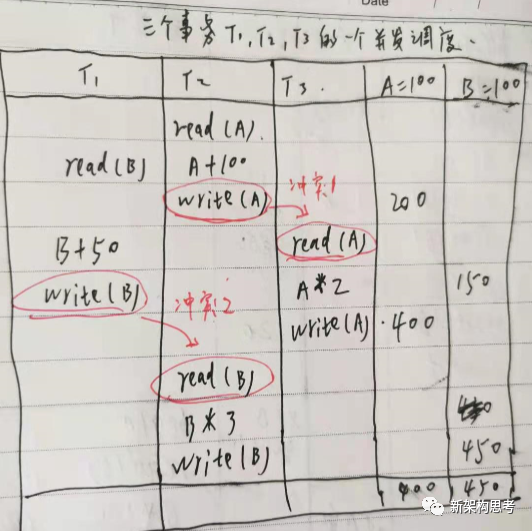
最终,我们也只能发现其中仅存在两对冲突。
w2(A) 和 r3(A),不同事务(T2 和 T3)对同一个元素 A 的写 - 读操作是冲突的。
w1(B) 和 r2(B),不同事务( T1 和 T2)对同一个元素 B 的写 - 读操作也是冲突的。
事务 T1 和事务 T3 分别操作的是 B 和 A 两个不同元素,因此任何操作都是不存在冲突的。
绘制成优先图,如下所示:
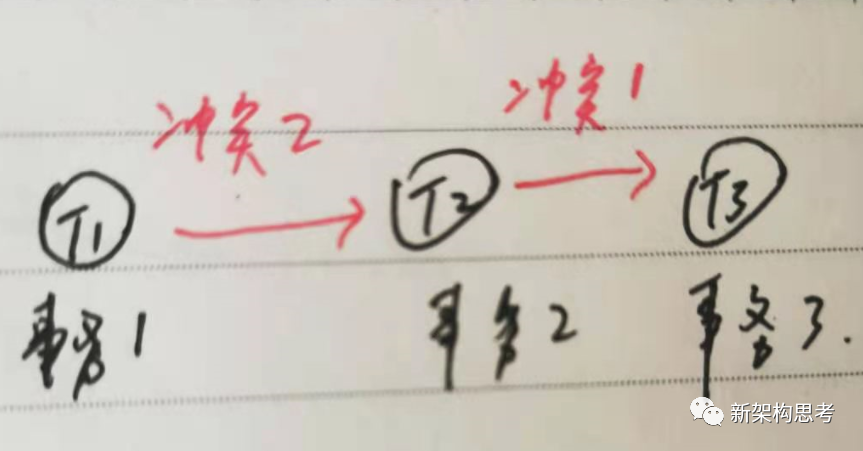
通过观察优先图,我们发现这个调度是冲突可串行化的,也就是按照这个调度执行,可以和串行事务 T1 → T2 → T3 得到相同的正确的结果。
更多内容参考:Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions
调度器是接收来自事务的请求,可以允许事务的操作在数据库上执行,也可以推迟操作的执行,目的就是为了控制操作的执行顺序,直到可以产生一个冲突可串行化的调度,保证数据执行的正确性。
怎么产生一个冲突可串行化的调度?
目前有三种可串行化的实现策略,可以保证产生一个冲突可串行化的调度。
(1)基于封锁的并发控制
锁是并发控制的很有效的一种手段,目前大多数关系型数据库也都采用了锁机制。
基于锁的并发控制,是一种悲观的方式。悲观的方式是,假设只要两个事务访问同一个数据元素,就一定会发生冲突,因此需要采用加锁来尽早预防,避免后续出现冲突。
基于锁的并发控制,我们将在后续章节中详细介绍。
(2)基于时间戳的并发控制
(3)基于有效性确认的并发控制
基于时间戳的并发控制和基于有效性确认的并发控制,都是基于乐观的方式。乐观的方式,认为发生冲突的概率比较小,因此可以延后等到发生冲突后再处理也不迟,这样就提高了事务的并发度和效率。
基于时间戳的并发控制和基于有效性确认的并发控制的具体内容,我们将在后续章节中详细介绍。
总结
在本讲中,我们重点分析了并发控制的概念和目的,以及是如何保证事务的一致性和隔离性的。本讲中概念比较多,原理比较多。这些概念和原理都是前人总结出来的规律,都是经过时间的检验和实践的验证的正确的结论。
并发控制有点像江湖中的武学秘籍,掌握好的人,可以成为武林高手,打遍天下;没有深刻的理解其中奥秘的人,就只能浅尝辄止,学个一招半式了。所以,希望你一定要认真体会,并加以记忆。如果有任何问题,欢迎在留言区评论。
下一讲我会为你讲解基于锁的思路来看并发控制的技术实现,到时见。

相关文章推荐:
01 | 如何实现自我基础设施新重建-从掌握一致性与分布式事务开始
03 | 分布式事务的产生原因及常见的解决方案(NewSQL、Distributed SQL等)
