




Hadoop之HDFS(一)基本概念及操作
Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
总结:
HDFS—解决大数据存储问题 MapReduce—解决大数据计算问题
架构分析
需求:如何存储一个2.5TB的日志数据文件?
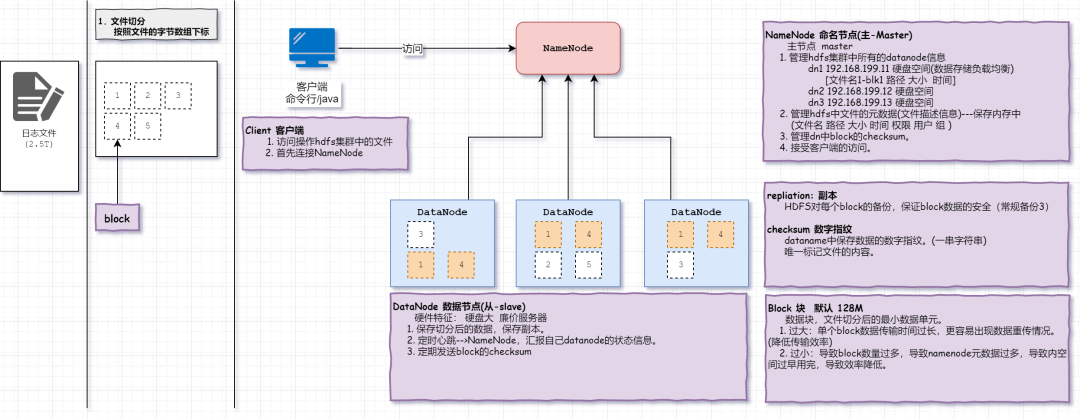
核心及重要概念
DataNode
:Slave节点,专门用来存储数据块(Block)的廉价服务器。NameNode
:Master节点,管理从节点,并接受客户端访问
主节点(master):
1. 管理hdfs集群中所有的datanode信息
dn1 192.168.199.11 硬盘空间(数据存储负载均衡)
[文件名1-blk1 路径 大小 时间]
dn2 192.168.199.12 硬盘空间
dn3 192.168.199.13 硬盘空间
2. 管理hdfs中文件的元数据(文件描述信息)---保存内存中(文件名 路径 大小 时间 权限 用户 组)
3. 管理dn中block的checksum
4. 接受客户端的访问
Block
:数据块,完整数据的最小组成部分,大小为128MB注意:拆分太少,导致单体文件过大,无法并行io操作文件,效率低。拆分太多,导致io次数过多,降低效率。 Client
:java或者命令行工具,用来访问HDFS中的数据的。replication
数据块block的副本,备份block,防止单体datanode宕机损坏导致数据丢失
checksum
校验和类似指纹数字签名 确保数据的可靠性,hadoop内部在判断文件是否一致或者变化,就对比文件的签名即可
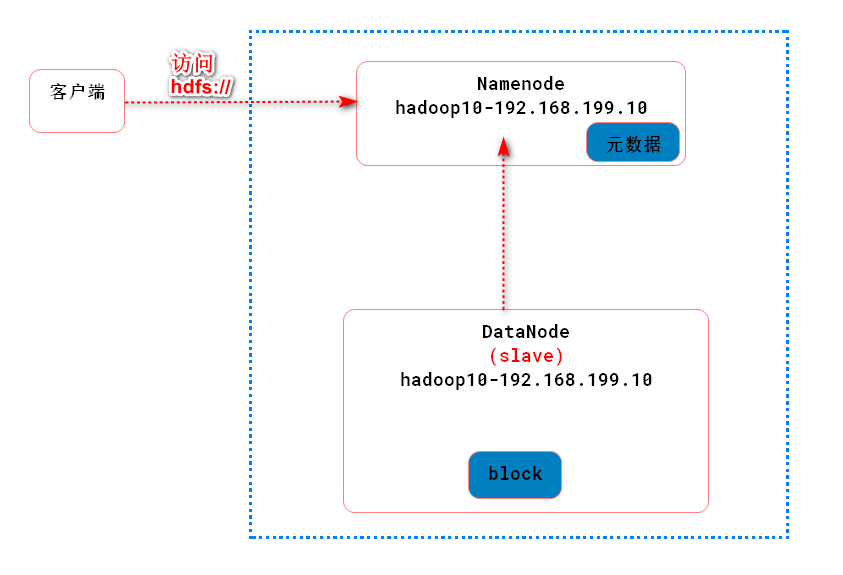
搭建HDFS单体架构
架构模型:
软件准备
Hadoop: http://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
官方文档:http://hadoop.apache.org/docs/r2.9.2/
安装步骤
# 1.准备虚拟机
1. 设置hostname
hostnamectl set-hostname hadoop10
2. 设置ip地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
---------网卡信息-----------------
IPADDR=x.x.x.10
重启网卡服务
systemctl restart network
3. 配置hosts(linux+windows)
vim /etc/hosts
----------以下是文件信息------------
x.x.x.10 hadoop10
4. 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
4. 安装jdk1.8
a.解压
tar -zxvf jdk1.8.tar.gz -C /opt/installs
b.配置环境变量
export JAVA_HOME=/opt/installs/jdk1.8
export PATH=$PATH:/opt/installs/jdk1.8/bin
export CLASSPATH=.
c.重新加载环境变量
source /etc/profile
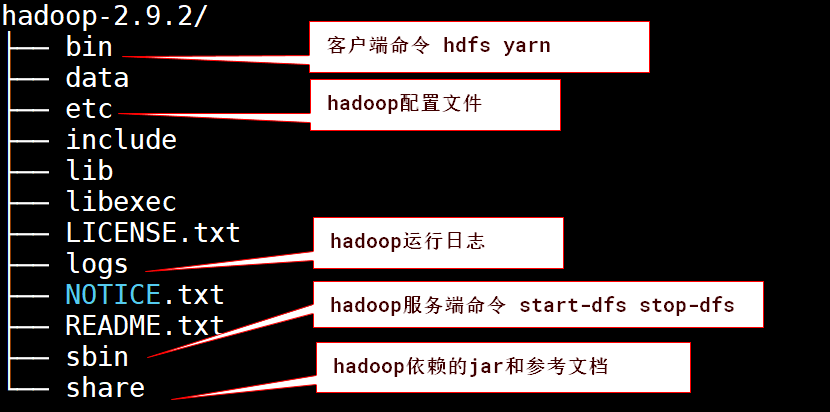
# 2. 安装hadoop
# 解压
[root@hadoop10 module]# tar zxvf hadoop-2.9.2.tar.gz -C /opt/install/
# 配置环境变量
vim /etc/profile
-------------以下是环境变量-------------
# 配置HADOOP_HOME
export HADOOP_HOME=/opt/installs/hadoop2.8.3
# 配置PATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 生效配置信息(重新执行profile中的指令,加载配置信息)
source /etc/profile
# 3. 初始化配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
# hadoop-env.sh
#
JAVA_HOME=/opt/installs/jdk1.8
# core-site.xml
# 配置hdfs入口
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop10:9000</value>
</property>
# 配置 数据保存位置
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/install/hadoop-2.9.2/data</value>
</property>
# hdfs-site.xml
# 配置副本个数
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
# mapred-site.xml
# 配置资源调度器yarn
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# yarn-site.xml
# 配置yarn的服务
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
# slaves
# 配置从机datanode的ip
hadoop10
# 4. 格式化HDFS数据库
# 一旦hadoop配置启动失败,删除data下的文件,再重新格式化。
# 初始化namenode和datanode存放数据的目录
hdfs namenode -format
# 5. 启动HDFS
# 启动hdfs
start-dfs.sh
# 关闭hdfs
stop-dfs.sh
# 6. 测试验证
# 查看hdfs进程
[root@hadoop10 install]# jps
2225 NameNode # master namenode主机
4245 Jps
2509 SecondaryNameNode
2350 DataNode # slave datanode从机
# 查看hdfs Web服务
1. 查看namenode的web服务
http://hadoop10:50070
2. 查看datanode的Web服务
http://hadoop10:50075
# 7. 日志监控
`namenode启动日志`
hadoop-用户名-namenode-主机名.log
`datanode启动日志`
hadoop-用户名-datanode-主机名.log
其他知识
# 启动失败如何处理
场景: 格式化或者启动hadoop失败。
说明:
hadoop/data文件夹
作用: 保存datanode和namenode持久化的数据。
时机:
1. 格式化hdfs namenode -format 会初始化该目录下的文件。
2. hdfs运行期间产生的数据,会操作该目录中的数据。
必要操作:删除格式化或者启动数据保存的文件目录。
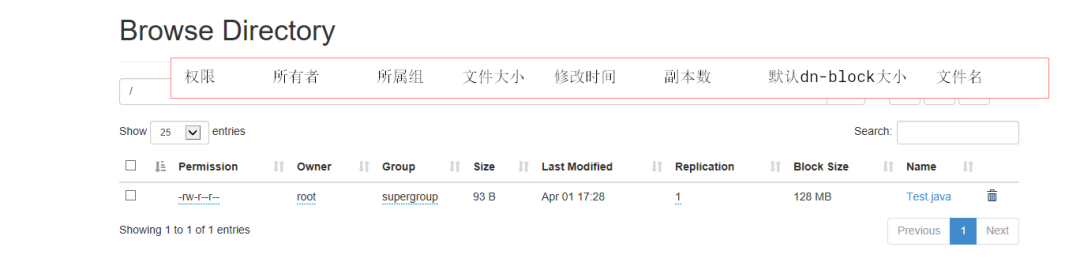
# namenode 的 web界面讲解
http://ip:50070.
1. 查看namenode中管理的datanode的信息
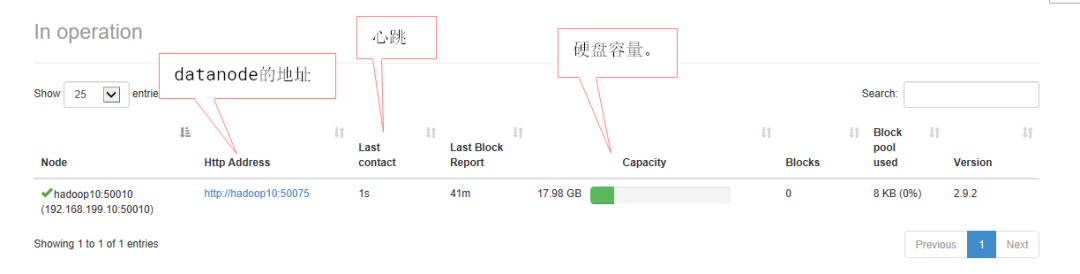
2. 管理文件block的元数据。
文件名 用户 用户组 类型 权限 时间 ....
# 启动过程日志监控(查看错误)
# 监控namenode启动日志
/hadoop2.9.2/logs/hadoop-用户名-namenode-主机名.log
# 监控datanode启动日志
/hadoop2.9.2/logs/hadoop-用户名-datanode-主机名.log
HDFS客户端
命令客户端
命令所在目录
${hadoop}/bin之下/hdfs
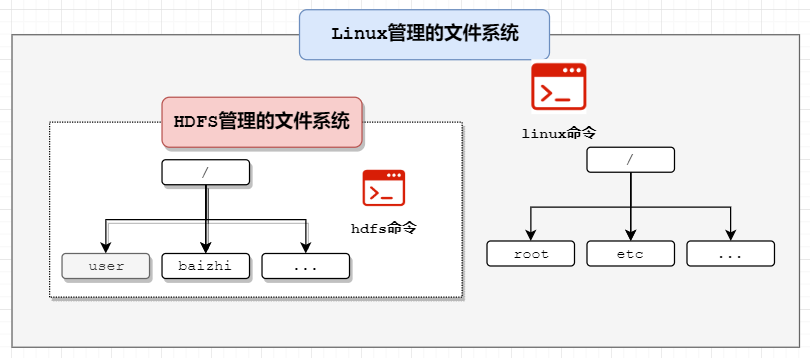
HDFS的文件系统结构
常用命令
HDFS类比linux命令
hdfs dfs -命令 参数
语法:
hdfs dfs -参数 值
命令语法 含义 示例代码 hdfs dfs -ls [-R] hdfs文件路径 查看文件元数据信息 hdfs dfs -ls / hdfs dfs -mkdir -p /目录a/目录b 新建文件夹,如果父目录不存在则添加-p参数 hdfs dfs -mkdir -p /baizhi/file hdfs dfs -put
linux文件路径 hdfs文件路径从linux向hdfs上传文件 hdfs dfs -put /opt/models/jdk /baizhi hdfs dfs -text
hdfs文档路径查看文件内容,可以查看压缩文件内的文档信息 hdfs dfs -text /baizhi/Test.java hdfs dfs -cat hdfs文档路径 查看文件内容 hdfs dfs -cat /baizhi/Test.java hdfs dfs -rm hdfs文件路径 删除文件 hdfs dfs -rm /baizhi/Test.java hdfs dfs -rm -r hdfs文件夹 删除文件夹,非空使用-rmr hdfs dfs -rm -r /baizhi hdfs dfs -get
hdfs文件 linux路径从hdfs下载文件到linux hdfs dfs -get /baizhi/jdk1.8 /opt hdfs dfs -chmod [-R] 权限运算值 hdfs文件 修改hdfs文件权限 hdfs dfs -chmod o+w /baizhi hdfs dfs -cp hdfs文件路径 hdfs文件路径 文件拷贝 hdfs dfs -cp /demo1 /demo2 hdfs dfs -find hdfs文件夹 -name "关键词" 文件查找 hdfs dfs -find / -name "a.txt" hdfs dfs -mv /hdfs/demo1/wordcount1.log /hdfs/demo2 文件移动 hdfs dfs -mv /hdfs/demo1/wordcount1.log /hdfs/demo2 hdfs dfs -checksum
hdfs文件获取文件的checksum hdfs dfs -checksum /hdfs/demo2/wordcount1.log hdfs dfs -du
[-s] hdfs目录查看文件大小,-s是统计该目录总空间大小 hdfs dfs -du [-s] /hdfs hdfs dfs -df
/查看文件系统的磁盘占用情况 hdfs dfs -df /


文章转载自第二范式,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
