




分布式计算领域,所有的操作几乎都围绕shuffle进行,掌握shuffle的架构设计,有助于分析计算的性能,把握算子执行的脉络。本文主要是分析Spark的Shuffle架构设计过程。Spark 以shuffle为分界线划分stage,然后逐步提交stage。其中代表的有reduceByKey和groupByKey算子。两者的最大区别就是前者具备局部聚合功能,后者不具备局部聚合功能,容易导致Execute上OOM的发生。Spark在对两者的实现上进行了接口抽象,使两者在最后的实现层面得到了统一,就是combineByKeyWithClassTag算子。
一:先跑一个reduce ByKey的demo :
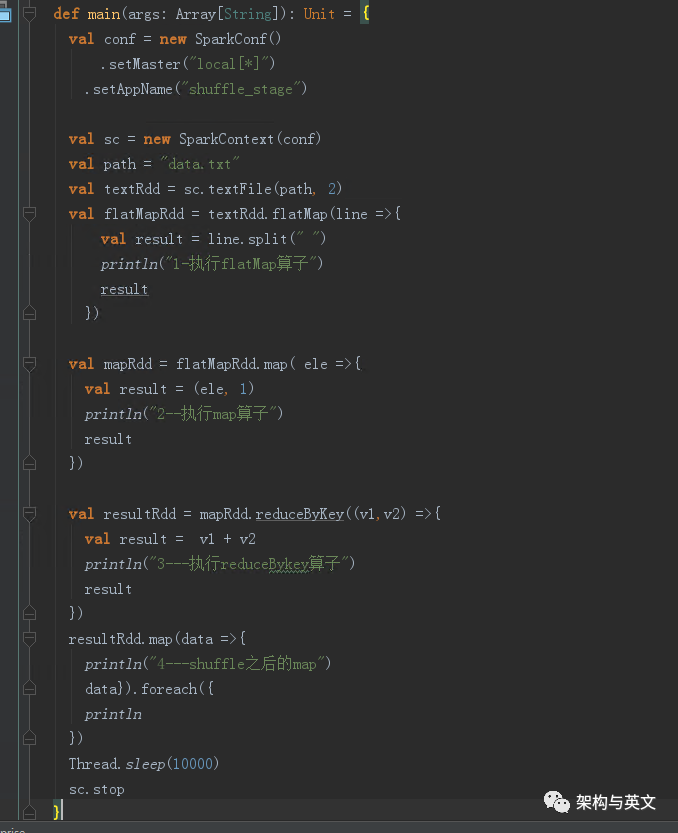
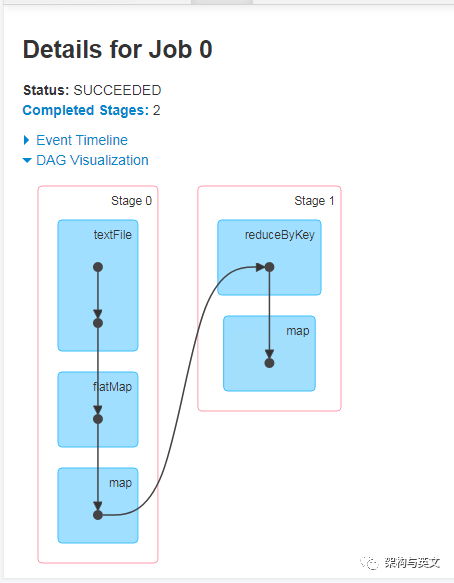
该demo主要是把数据分为2个分区,然后进行stage划分,运行后的DAG图如下:
执行代码会发现奇怪的现象,使用两个分区,当数据不同时,打印的结果不一样。
案例1:当数据只有一条,使用两个分区时,打印的结果似乎只把reduceBykey 放到shuffle前面调用了,很是奇怪:
输入数据:

执行结果:
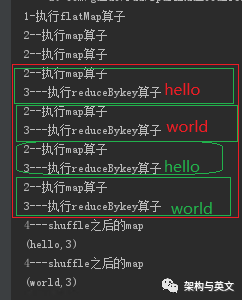
从分析可以判断首先执行flatmap把改行数据转为6条数据,然后分别进入map和reduceByKey函数的局部聚合函数,没有进入到shuffle后的reduceByKey 。
案列2:当数据输入三行两个分区时,输出是按照我们预想的输出:
输入数据:
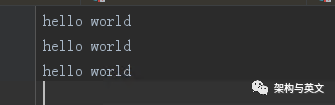
输出结果
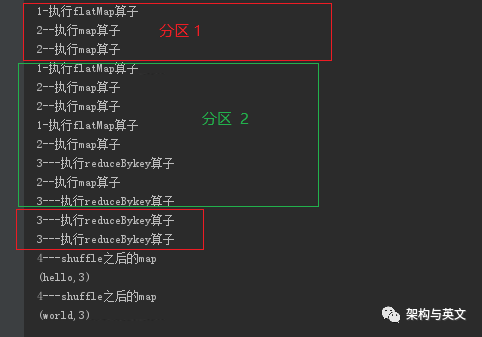
看到这两个不同的结果,我们会感到疑问,为啥 案例一的reduceByKey在shuffle之前执行,shuffle之后没执行呢?
带着疑问,我们进入到源码分析:
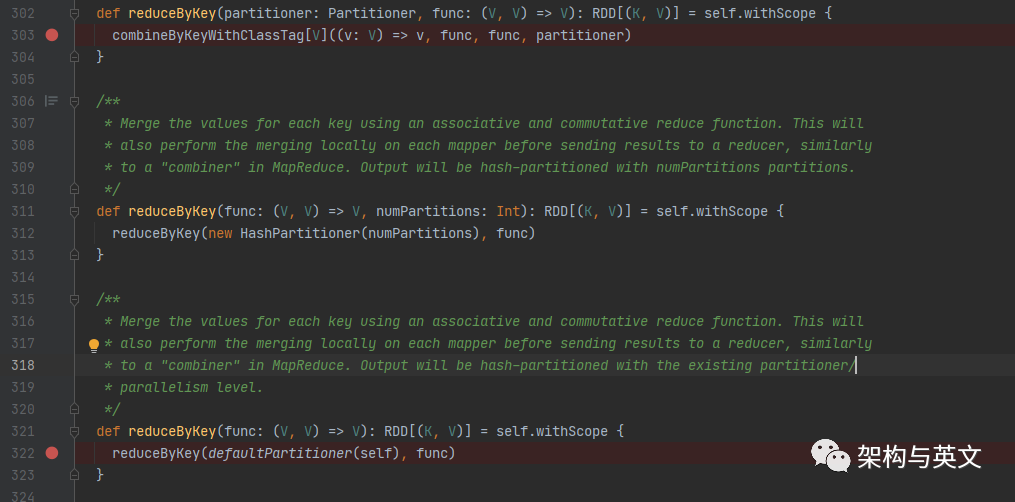
根据我们写的代码,首先调用322行的reduceByKey,使用默认的hash分区器,该分区器的作用,主要是让shuffle之前的stage输出数据到对应的分区。然后再跳转到303行的combineBykeyWithClassTag函数:
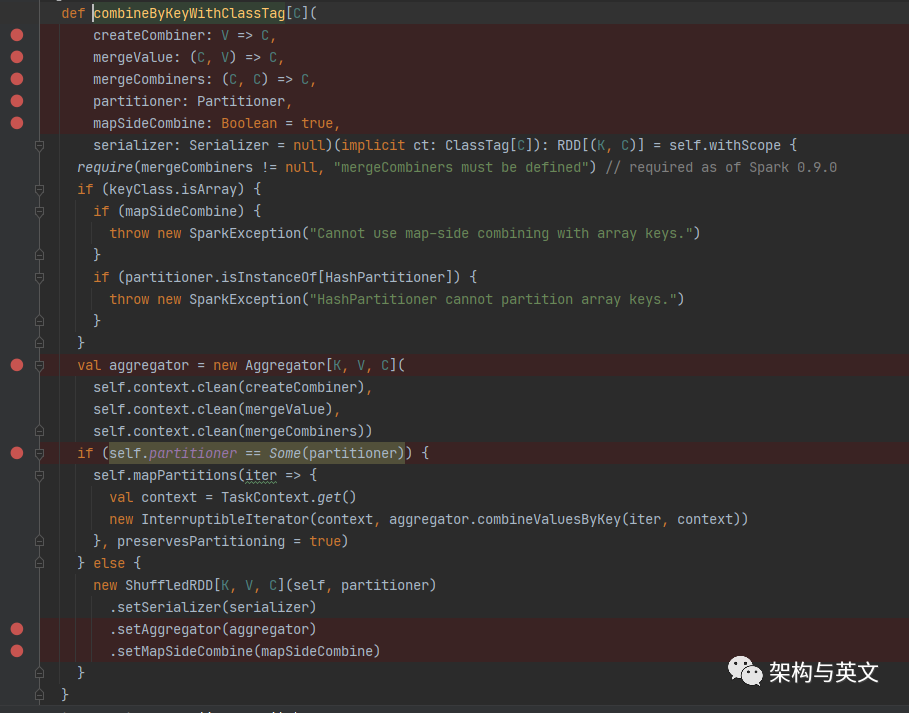
我们主要看红点的信息。
createcombine是第一个元素Key到达时创建;
mergeValue是对同一个combine内相同的值进行合并;
mergeCombine是对来自不同combine内的相同的key值进行合并
patitioner 用于对数据划分分区。
mapSideCombine 是否在map端进行combine操作
再看上面303行reduceBykey 传入的参数combineBykeyWithClassTag
createcombine = (v:V)=>V
mergeValue = demo代码里定义的fun
mergeCombine = demo代码里定义的fun
partitioner = HashPartitioner
mapSideCombine =true
然后再阅读源码实现逻辑,逻辑很简单,首先使用传入的3个函数定义一个aggregator,然后根据patitioner 创建对应的RDD。由于demo中当前reduceBykey使用的是HashPartitioner,其上一个算子Map的分区器是None,所以创建的是ShuffleRDD,并设置对应的参数aggregator。
我们可以得出结论
1、reduceByKey具备mapSideCombine 功能,解释了为什么shuffle之前的stage会打印“--执行reduceByKey算子”的输出。
2、案例一之所以在shuffle后的stage没有执行我们定义的函数,是因为只有一个分区的数据到达shuffle的stage时,只调用了createcombine 函数,由于该分区的数据已经执行了局部聚合,没有重复的key,所以就没有后续的打印执行。
下一步:
走到这里我们似乎了解了combineBykeyWithClassTag的实现逻辑,它是为shuffle服务的,shuffle的宏观依赖流程如下图:
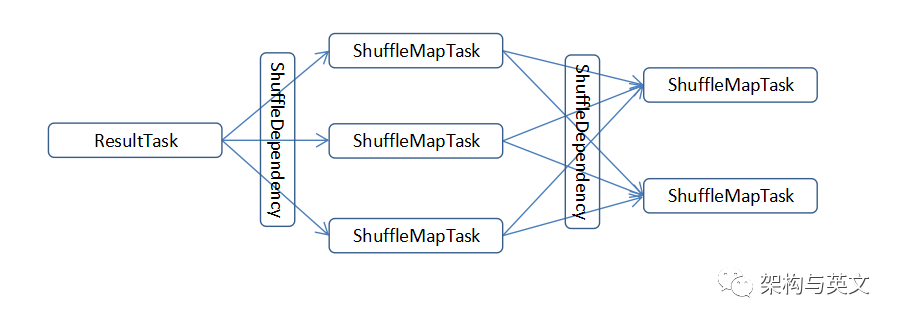
1、整个job的stage依赖过程是
ResultTask -> ShuffleMapTask->ShuffleMapTask->...->ShuffleMapTask ;
2、ShuffleRDD - >shuffleReader 实现读 ;
唯一实现类是BlockStoreShuffleReader
3、ShuffleMapTask ->write 实现写 ;
有3种shuffleWriter可供选择,BypassMergeSortShuffleHandle、SerializedShuffleHandler和BaseShuffleHandle
4、ShuffleDependency 、 ShuffleHandle在两个stage之间实现shuffle信息的传递 ;
由于shuffle的架构实现的太过巧妙,且内容较多,后续我会陆续介绍shuffle的读和写,以及partitioner传递、如何执行局部聚合的。
