




Hive是大数据生态必不可少的数据仓库服务,我们能使用很简单的sql命令执行分布式查询任务,后端可以对接MR、TEZ、SPARK分布式查询引擎。高性能是衡量分布式的指标,为了对hive能更高效的使用,我们有必要研究其线程模型是如何支持高并发的。我们以Beeline和HiveServer为入口分析下客户端和服务端执行流程。
一、HiveServer执行解析。
首先看下service接口及其继承类
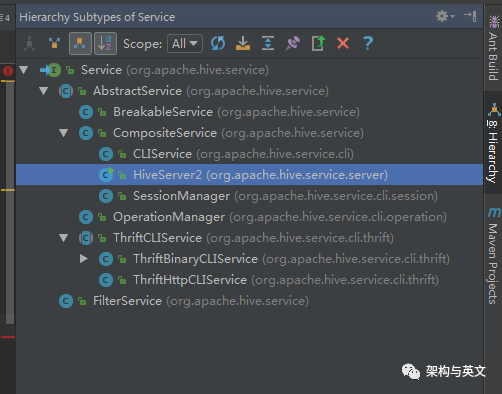
其中Hive Server2->Composite Service->AbstractService->Service是我们分析的主线。CLiService用于对客户端收到的sql命令进行异步提交到后端集群(MR、SPARK、TEZ),Session Manager是用于客户端会话管理,并在初始化中创建一个backgroupthreadPool。ThriftBinaryCLIService用于创建线程接收并处理客户端连接。
看下HiveServer2的初始化定义。
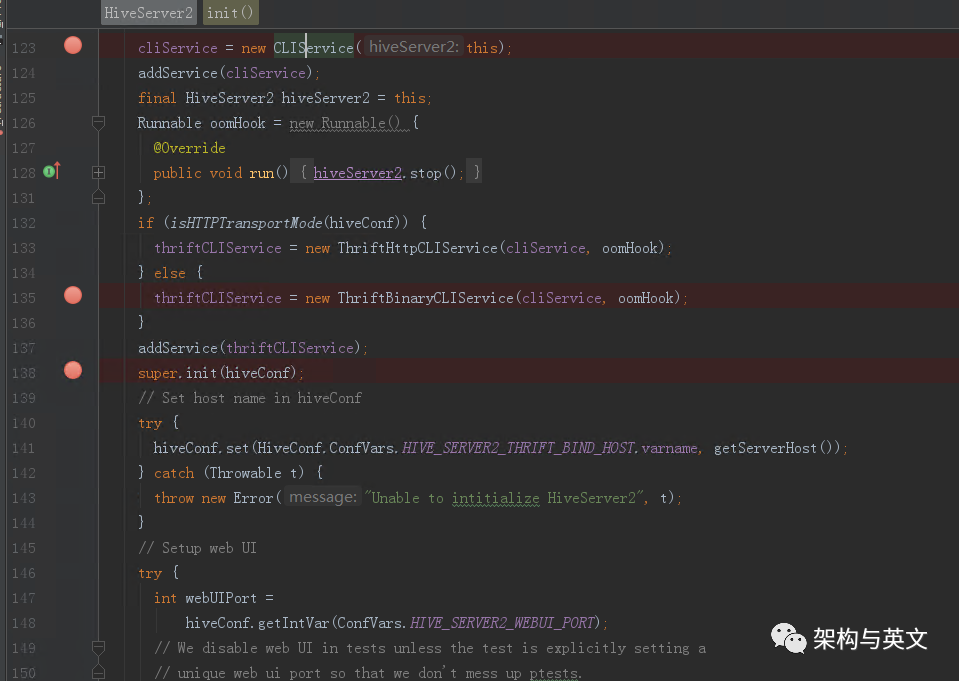
此函数内部定义了ThriftBinaryCLIService和CLiService。直接看下ThriftBinaryCLIService的run函数代码:
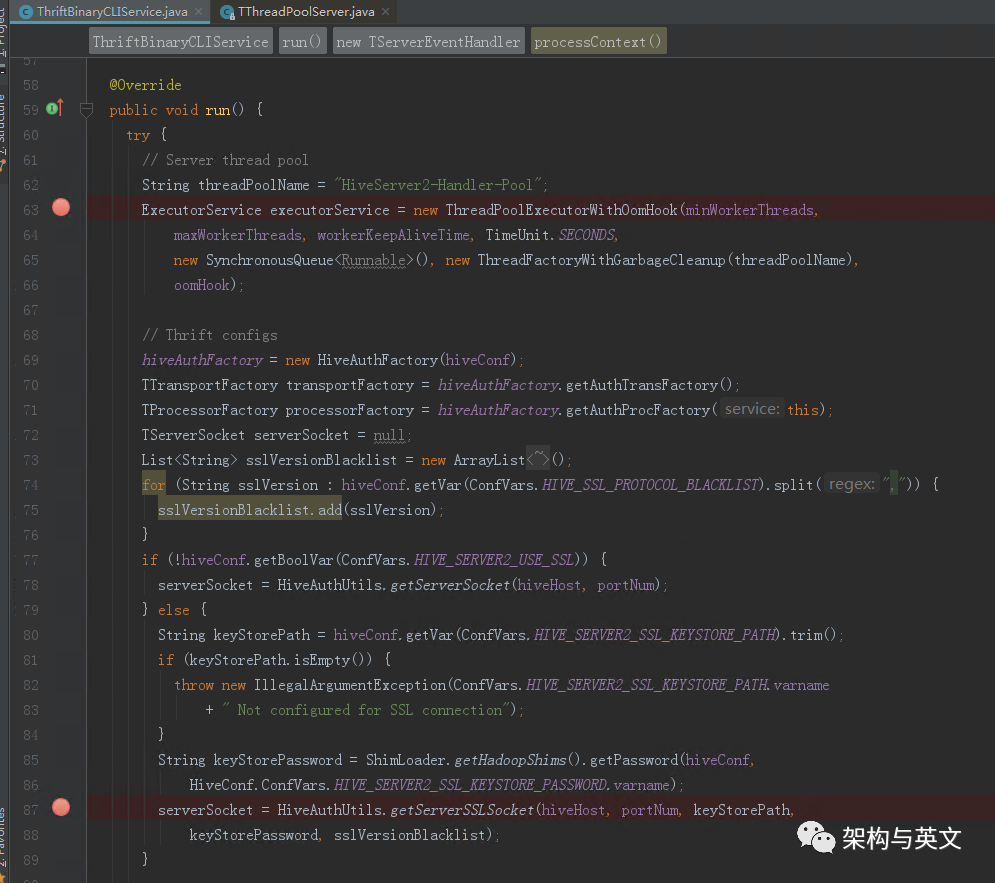
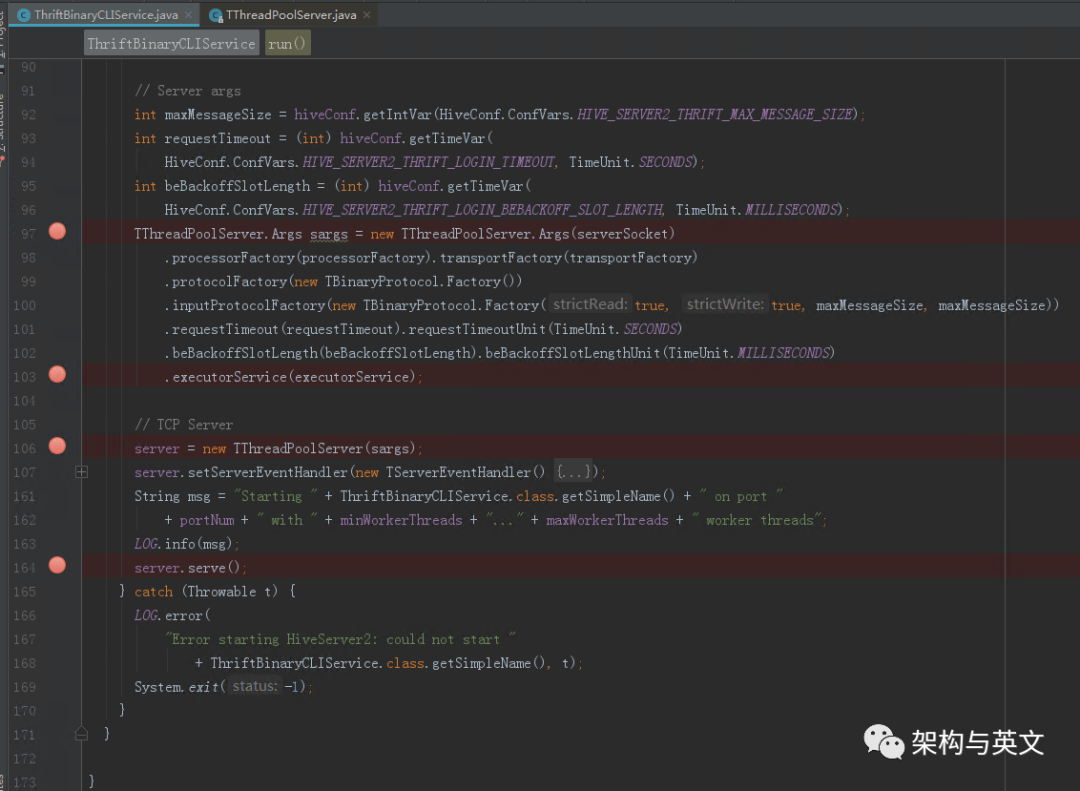
该函数定义了Executor Service线程池和服务端server Socket,并把它包装到TThreadPoolServer里面,该线程池用于接收客户端发的连接请求,然后调用TThreadPoolServer的serve启动监听任务。
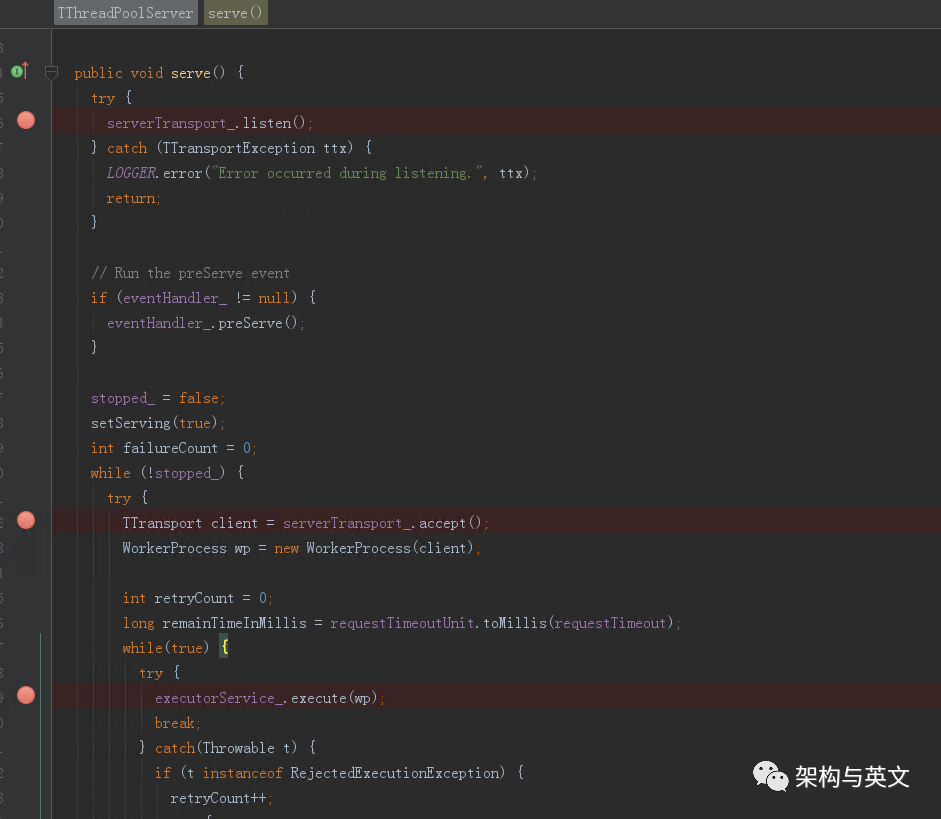
serve函数启动监听任务,开始accept客户端连接,每一个连接被包装为一个WorkerProcess,然后丢到TThreadPoolServer的线程池里执行,转到WorkerProcess的run函数。
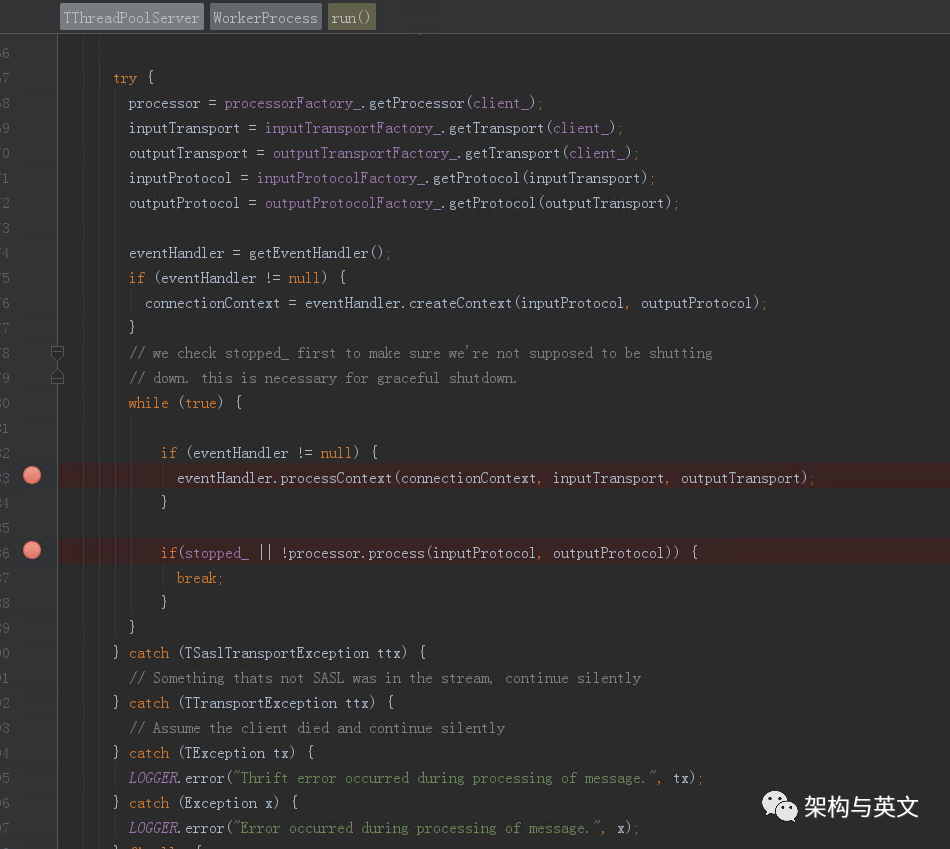
该函数会从client_对象读取Processor、Transport、Protocol,然后根据这些信息创建context,最后触发Process处理,最终调用会落到operator.runInternal函数里面。本文主要以SqlOperator为例子就行分析。
接收客户端的线程池创建已经分析,再看下sql执行任务的线程池创建,其在CliService的初始化函数中。这里会创建Session Manager,并加入到service List里面,最终会回调到sessionManager 的createBackgroundOperationPool函数中。
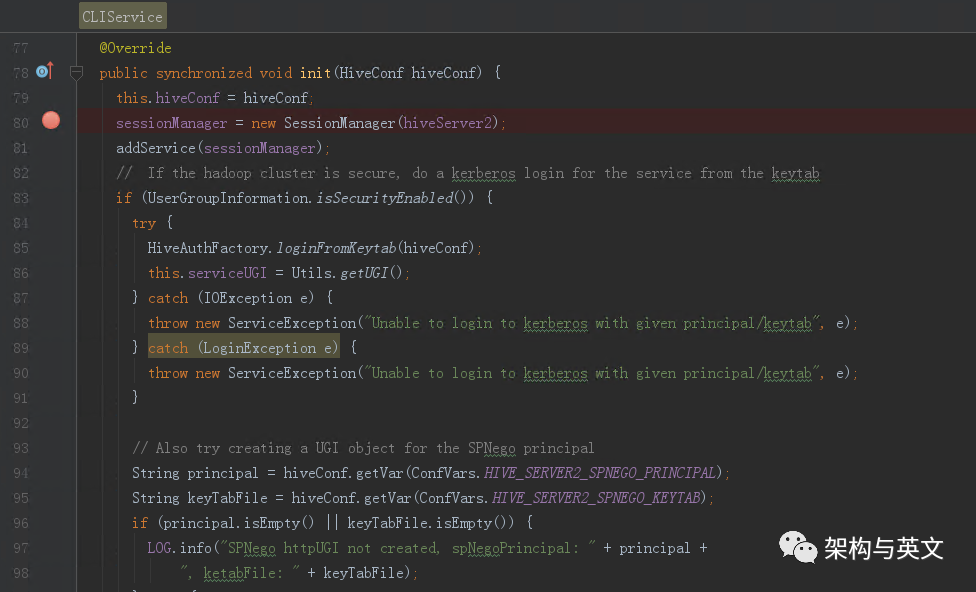
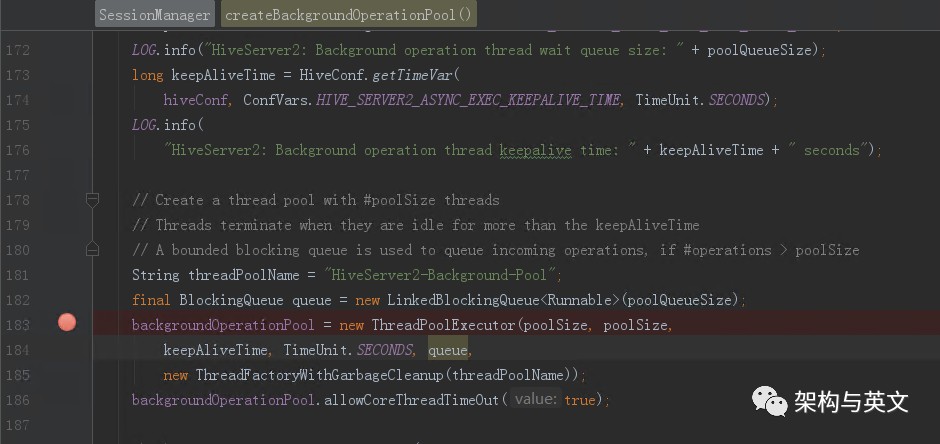
该线程池主要是接收SQLOperation提交的任务,在后端分布式引擎执行任务。ThriftCliService接收到sql后,会调用executeStatement,最终触发SQLOperation执行submitBackgroundOperation提交。
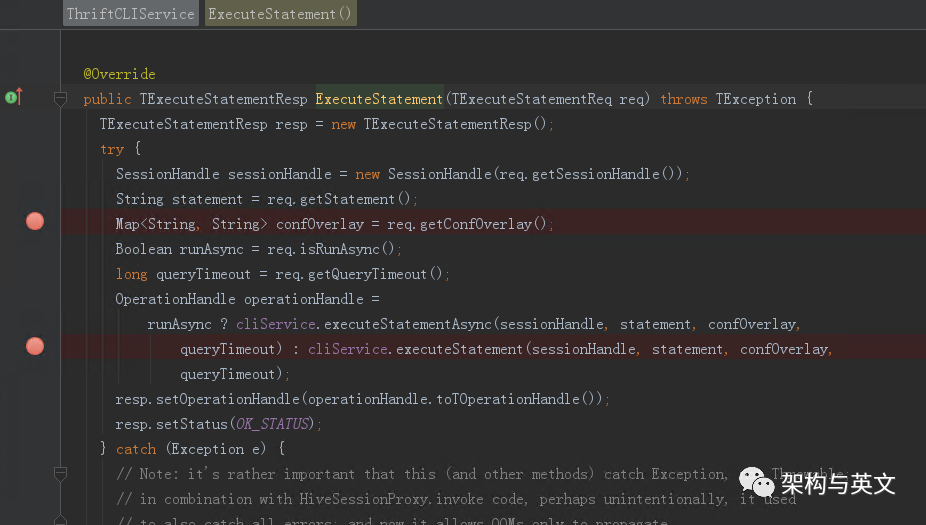
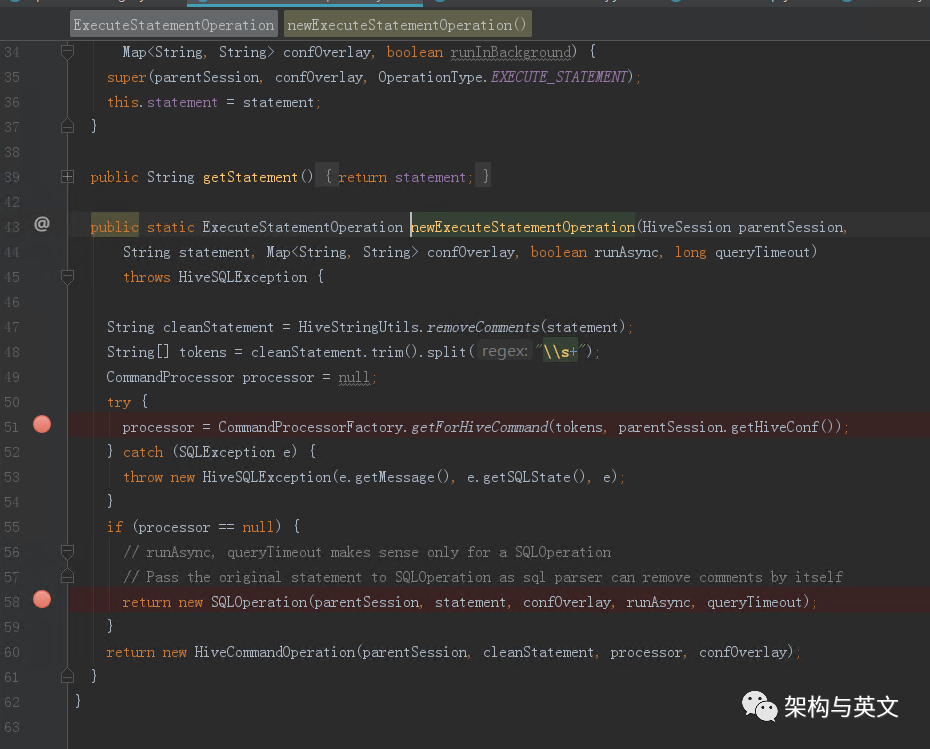
在newExecuteStatementzOperation内部会根据是否是HiveCommand生成HiveCommandOperation和SQLOperation。其中HiveCommand的类型主要有以下几类:
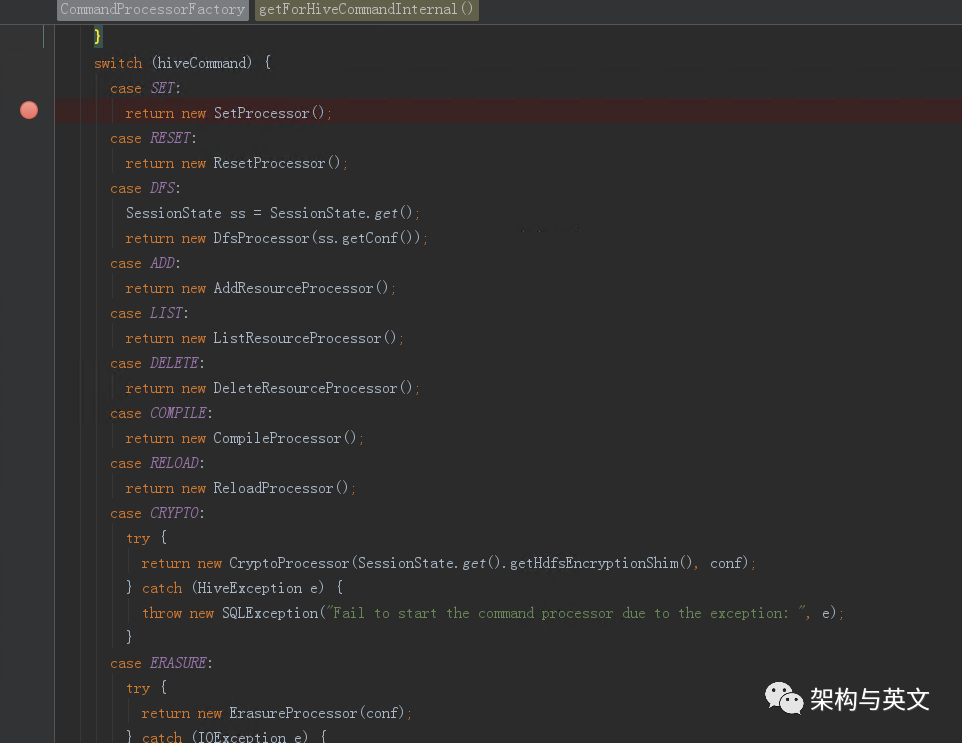
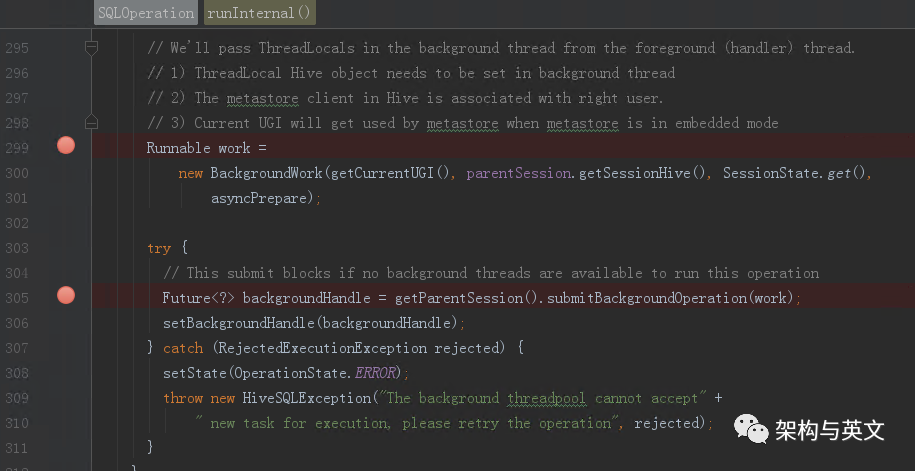
如果不属于这几类,比如查询select ,则会生成SQLOperation,并在其runInternal()方法内部提交。
二、客户端执行流程
通过beeline提交的sql最终会通过beeline.dispath函数触发到command.sql
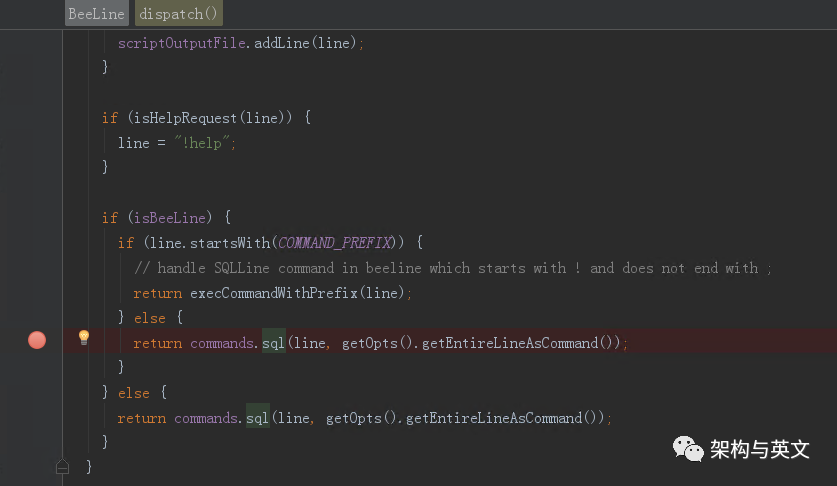
command.sql会调用到executeInternal()
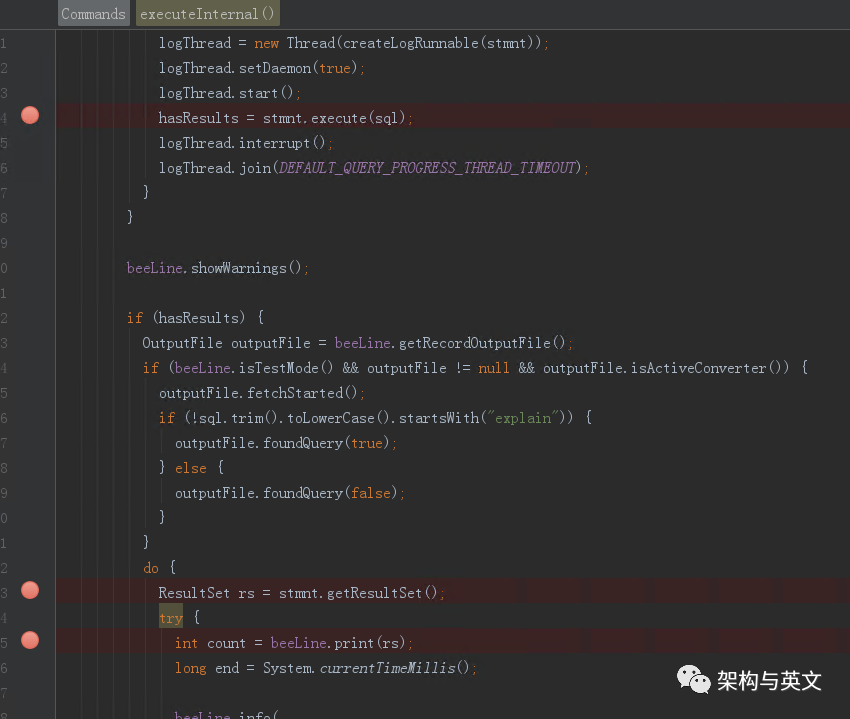
该函数内部分2步,
第1步是stmn.execute(sql)发生请求执行sql;
第2步是beeline.print发生请求获取数据;
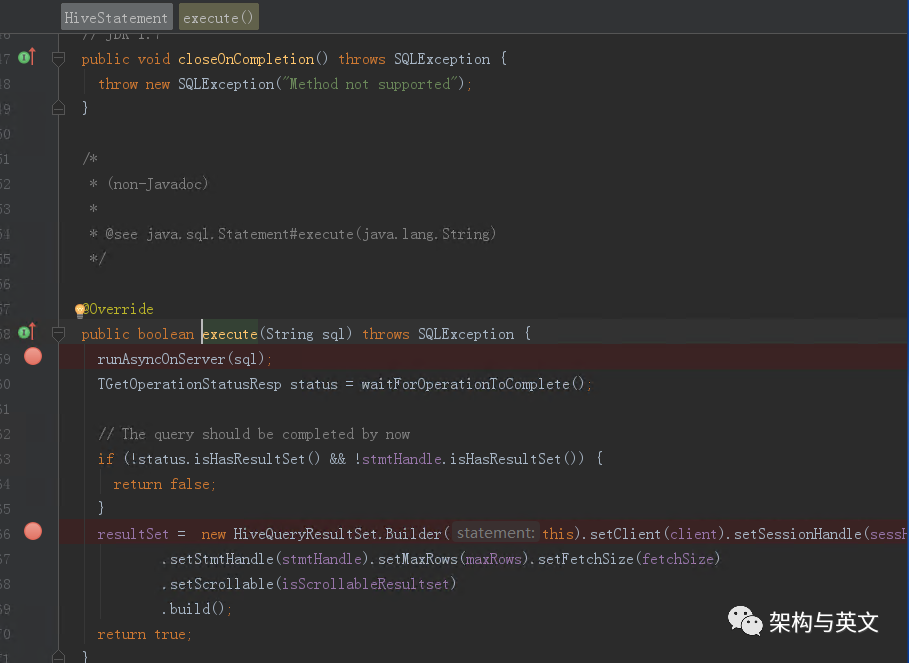
第一步execute内部也是分2步:
执行runAsyncOnserver(sql)异步提交;
根据SQL执行结果构造HiveQueryResultSet,该对象用于发送获取结果请求。
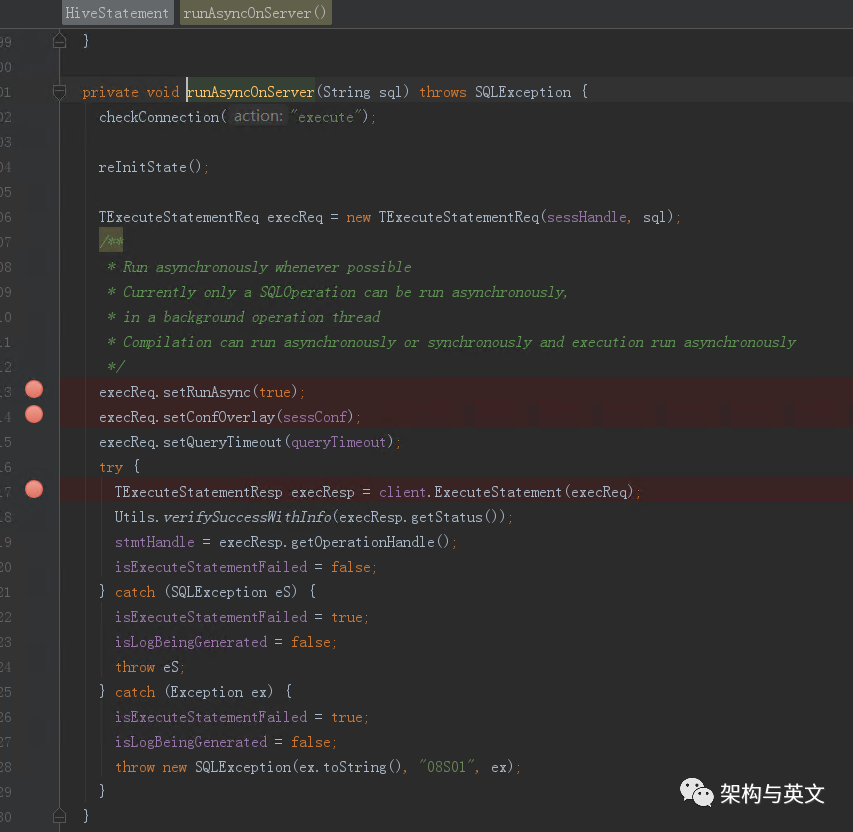
在runAsyncOnserver函数内触发客户端发送thrift请求,执行executeStatement方法,最终被服务端ThriftCliService接收到sql后,内部会触executeStatement接口执行,对应上面分析的sqlOperation。
第二步 print函数内根据fetchsize逐步发送获取结果请求。
print最后触发了TableOutputFormat的print函数。
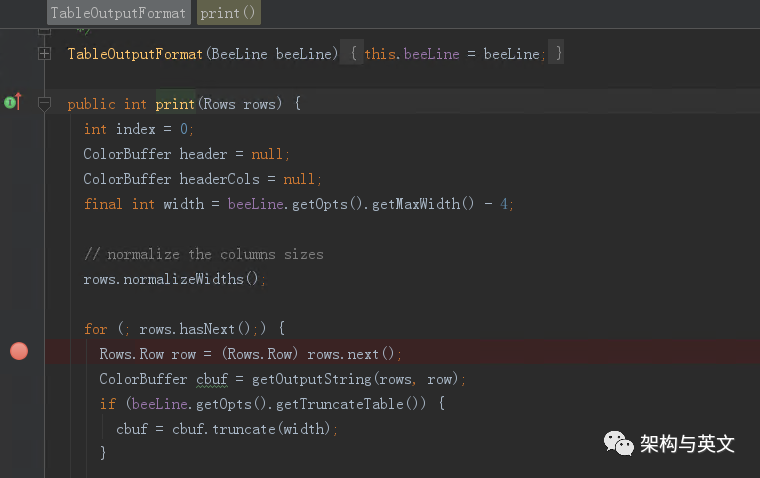
上文提到SQL执行结果会包装为一个HiveQueryResultSet对象,该对象会被封装到Row的一个实现类中,Hive内部共定义了3个实现类(BufferdRows、IncrementalRows、IncrementalRowsWithNormalization)。
因此调用row.next触发的是HiveQueryResultSet.next()
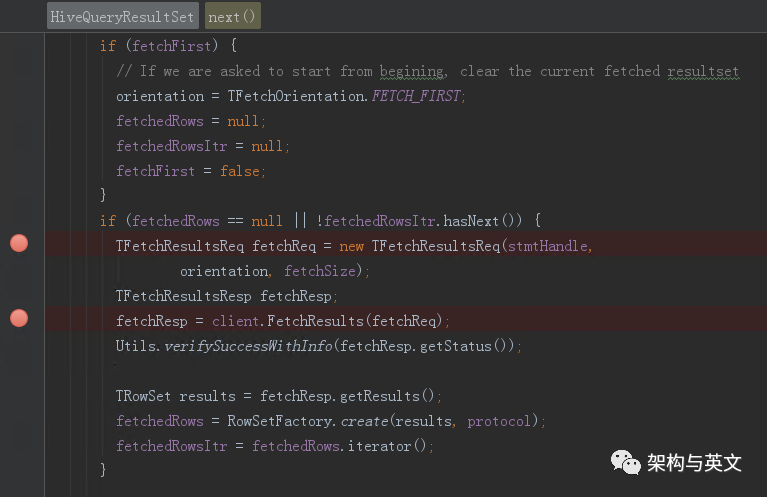
可以看到其内部触发了一个client.FetchResults,并包装了一个fetchsize也就是每一个next会请求一个行数为fetchsize的结果。
服务端接收后调用FetchResults,其req.getMaxRows对应的是fetchsize。
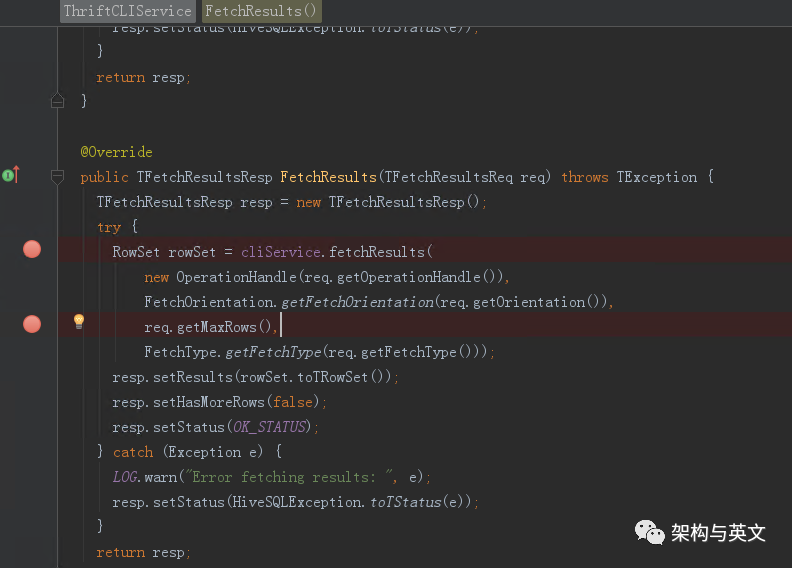
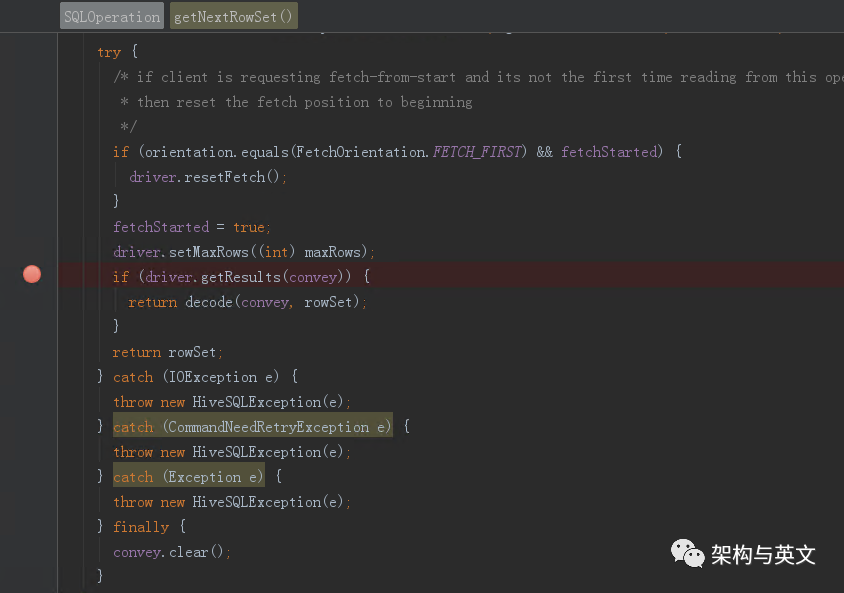
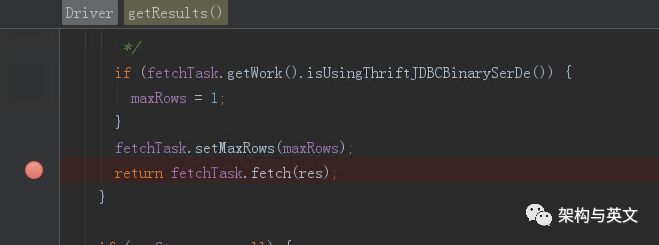
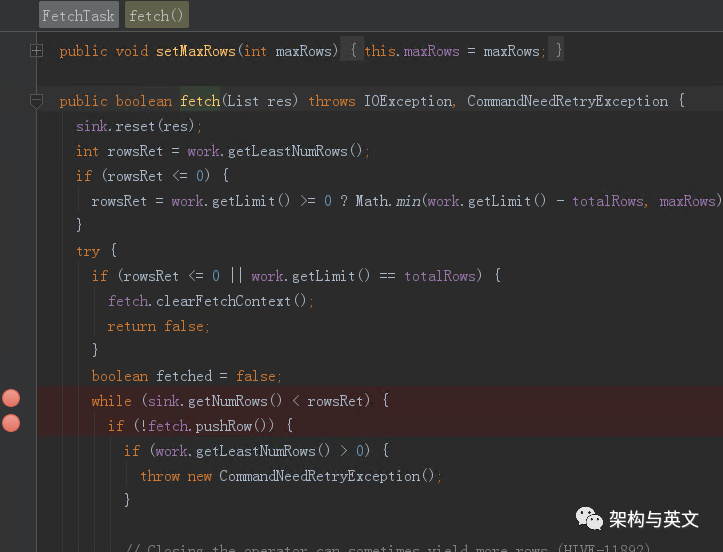
跟踪函数调用链路,最终到了FetchTask.fetch函数,注意到最后的while里面,发现其是一行一行从结果文件内获取数据的,获取到fetchsize大小时,会退出while并返回。
