




一、背景
HDFS是构建在普通机器上的分布式文件系统,这类系统需要考虑的一个首要问题就是容错,即允许部分节点失效。为解决节点失效后数据的可靠性,HDFS采用了副本策略。默认为所有的Block存放三个副本,理论上三个副本能保证不丢数据。虽然副本机制能够有效解决部分节点失效导致数据丢失的问题,但对于大规模HDFS集群,副本机制造成大量存储资源消耗,在默认情况下存储空间冗余高达200%。如果考虑数据规模和存储成本,按照1GB存储空间成本为1¥,定义成本系数ratio=1¥/(1GB*1Rep)表示在HDFS中1GB数据量副本数每变化1成本相应变化1¥。若数据规模是5TB,每副本数的成本为5,000¥;而如果数据规模到了5PB,每副本数的成本差距就有5,000,000¥。考虑20PB数据,如果副本数从3降到1.4,大概节约成本20PB×1000T/P×1000G/T×1¥/(GB×Rep)×(3-1.4)Rep = 32,000,000¥,成本非常可观。直接降低副本数会增加数据丢失的风险,所以有必要在成本和可靠性之间找到一个平衡点。Facebook提出用RAID思想降低副本数利用Erasured Code确保数据可靠性并将其开源,早前Google已成功将其应用在Colossus (GFS2)上证明其有效性。
二、基础概念
独立冗余磁盘阵列(Redundant Array of Independent Disks,RAID)是由多个小容量、独立硬盘组成的阵列,综合性能可以超过单一昂贵的大容量硬盘性能。由于是对多个磁盘并行操作,所以RAID磁盘系统与单一磁盘相比输入输出性能得到了提高。服务器把RAID阵列看成单一存储单元,并对几个磁盘同时访问,所以提高了输入输出速率。RAID具有单磁盘不具有的优点,它可以通过数据校验,提供容错功能。按照数据校验方式不同RAID分成不同类型,不同的RAID级别能容忍磁盘阵列中的一个磁盘奔溃,如果一个以上的磁盘同时奔溃,数据就无法恢复。利用这项技术,将数据切割成许多区段,分别存放在各个磁盘上,应用同位检查(Parity Check)的思想,当磁盘数组中任一磁盘出现故障通过数据重构仍然可读出数据,同时将数据经计算后重新置入新磁盘提高存储系统的可靠性。
XOR算法是一种简单的数据编码校验算法,通过在数据传输和存储中增加数据块之间的抑或运算结果即奇偶校验码实现检测和校正数据错误。XOR编码校验算法相对简单,可以最多校验一个数据块的错误。RAID5就是应用XOR编码实现的一种简单独立冗余磁盘阵列。
Reed-Solomon算法是一种前向错误校正算法,通常用于数据传输和存储应用,通过在数据传输和存储之前增加冗余实现检测和校验数据错误。Reed-Solomon算法是在伽罗华域(Galois Field,GF)上的运算,Reed-Solomon编码/解码器可以检测和校正数据块的错误。RS码不但可以纠正随机错误,突发错误,以及二者的组合,而且可以构造其它码类,如级联码。同时它具有极低的未探测差错率,这意味着与它配合使用的译码器能可靠地指出是否正确的校正码字,因此RS码成为一种很重要的纠错码。
例如,(255,223)RS码表示码块长度共255个符号,其中信息代码的长度为223,检验码有32个检验符号。在这个由255个符号组成的码块中,可以纠正在这个码块中出现的最多l6个分散的或者l6个连续的符号错误。RS码属于循环码的一种,它的编码过程是用它的信息多项式除以校验码生成多项式求出校验位的过程。也就是计算信息码符多项式除以校验码生成多项式之后的余数。
更多关于RAID和XOR/RS的信息请参考http://wikipedia.org。
三、HDFS RAID架构
HDFS RAID是Facebook在现有HDFS代码基础上包装的contrib,于2013年开源,本文主要基于https://github.com/facebookarchive/hadoop-20/tree/master/src/contrib/raid进行分析。
HDFS RAID结合了HDFS分块和RAID思想,在文件分块基础上再对连续Block组合成stripe,针对stripe通过Erasure Code算法生成新Block。为区分原始数据与生成数据,记原始文件Block为src Block,编码生成数据为parity Block。当然,副本策略对src/parity依然可以有效。当有限数量的Block数据出现问题,不论src还是parity,都应该能从其他数据中恢复出来。下图示RAID的基本原理。
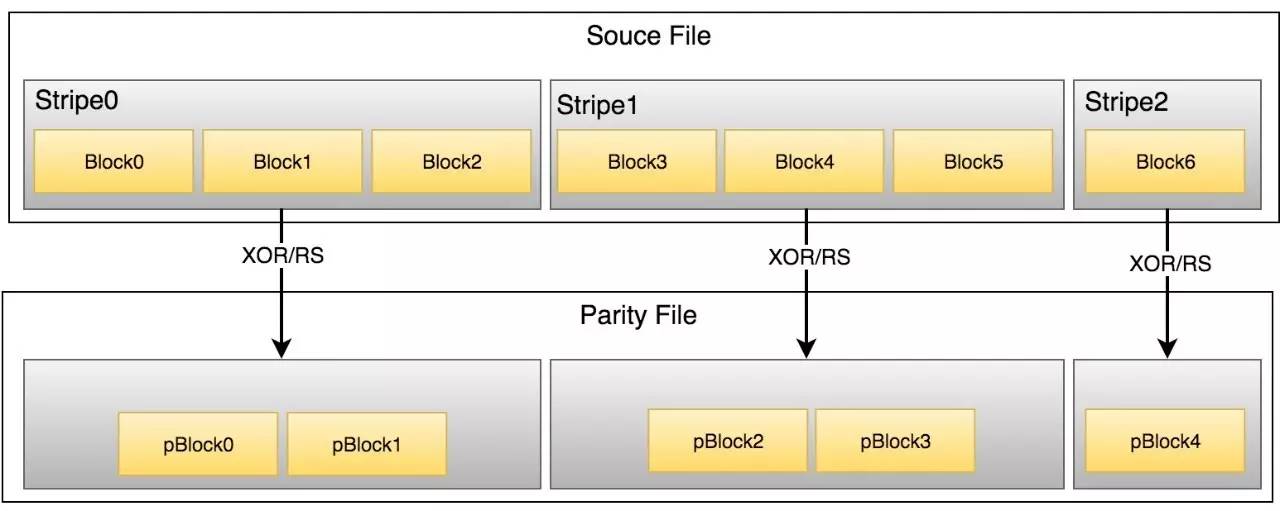
图1 RAID基本原理图
HDFS RAID的核心分成两个模块:RaidNode和DRFS(Distributed Raid File System)。HDFS RAID的架构如图2。
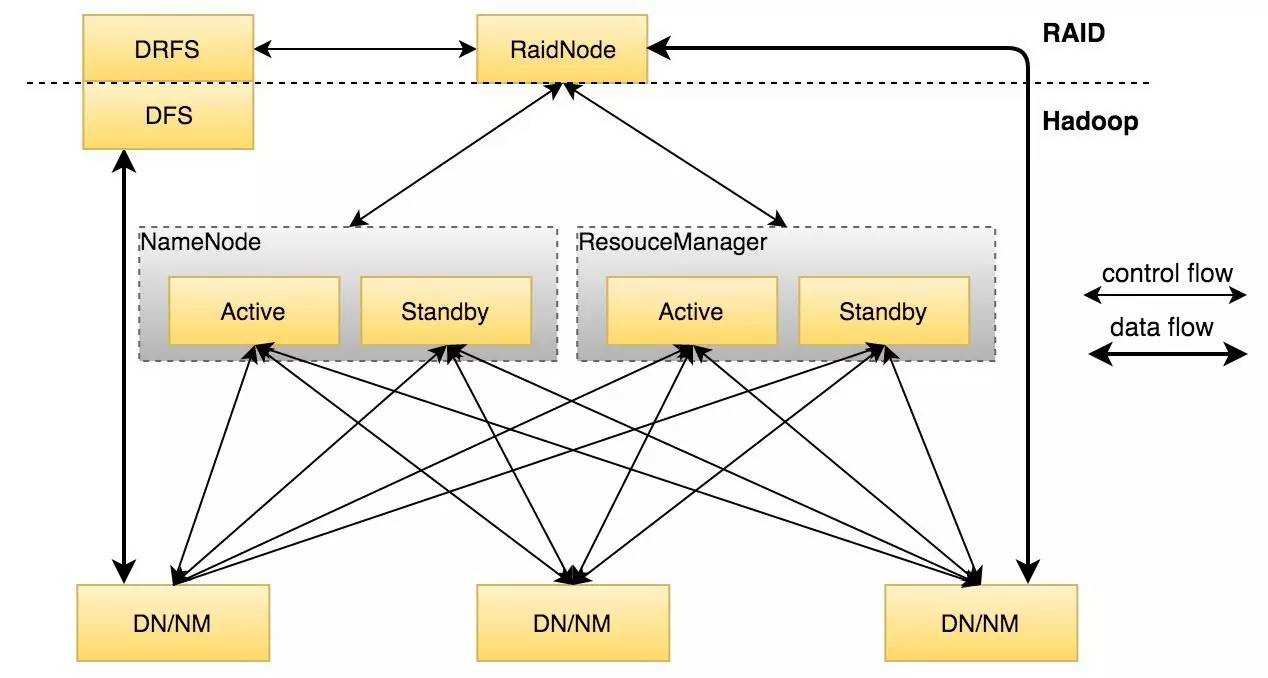
图2 HDFS RAID架构图示
HDFS RAID主要由两部分组成:RaidNode和Client。
RaidNode:
(1)RPC Server,接受RPC请求执行相应命令,对应协议RaidProtocol。主要提供集群管理员通过RaidShell给RaidNode发送命令。
(2)ConfigManager,通过读取raid.xml配置文件,获取用户指定的Policy(RAID策略),通常配置文件会指定多个Policy。一般一个Policy对应一个目录,包括这个目录下那些文件会触发RAIDing操作(例如srcReplication是3的文件,modTimePeriod为3600000表示最后一次修改时间在1个小时之前的文件会被作为RAIDing的备选);这些文件采用何种编码方式(XOR或Reed Solomon);编码后parity file和meta file的备份数(targetReplication和metaReplication)等等。
(3)启动多个线程,BlockFixer线程用于定期扫描看是否有数据块corruption然后执行修复;TriggerMonitor线程按照raid.xml配置的各种策略定期检查相应的文件,然后执行encoding操作生成parity file;PurgeMonitor线程用于删除已经废弃的parity file;HarMonitor线程定期把parity file小文件按照Har的形式合并,减少NameNode元数据存储的压力。
目前RaidNode对encoding和decoding的过程有两种方法:
(1)LocalRaidNode:所有的计算任务都在RaidNode本地。因为计算parity块是一个计算密集型任务,所以这种方法的扩展性受到限制。
(2)DistributedRaidNode:通过MapReduce把Job分布到不同的节点上计算parity块。
同样对于BlockFixed也有两种对应的方法:
(1)LocalBlockFixer: 在RaidNode本地decoding修复corrupted数据块。
(2)DistBlockFixer: 通过分布式MR任务的形式decoding数据块。
Erasure Code是用来encoding和decoding的算法。当前RAID中有两种实现:XOR和Reed Solomon。XOR只能允许丢失一块数据,而RS可以容忍丢失多块。RS默认采用(10,4)策略实现,即10个数据块生成4个parity file,那么可以容忍丢失4块数据。
DRFS(Distributed Raid File System):
(1)DRFS是包装在HDFS Client之上的全新客户端,截获应用对HDFS Cient的调用。例如用户访问某块数据,DRFS会调用HDFS Client去NameNode/DataNode获取数据,如果返回数据正常那么OK;如果读取的过程中遇到corrupted data,那么DRFS Client截获HDFS Client返回的BlockMissingException,然后接管这个文件的读取流,通过parity file恢复丢失的数据块返回给应用程序。整个数据块恢复的过程对应用程序是透明的。而且DRFS Client读取到corrupted data block恢复之后只是传给了应用程序,不会把数据恢复到HDFS中,与其不同BlockFixer和通过RaidShell触发的recoverFile操作会把修复后的块数据回写HDFS。
(2)RaidShell允许管理员手动触发丢失或损坏的块的重新计算或检查已遭受不可恢复损坏的文件。RaidShell为RAID主要提供了包括recoverBlocks,raidFile,fsck等功能的CLI。这几个功能直接调用了RaidNode或DistributedRaidFileSystem的对应函数不再详述。
四、RaidNode
(1)BlockIntegrityMonitor
HDFS通过副本数实现数据可靠性,HDFS RAID通过降低原始数据Source File的副本数同时增加编码数据Parity File达到可靠性目标。HDFS RAID同样存在因为节点宕机或者下线、数据校验失败等情况造成数据失效问题。出现上述情况检测和重建失效数据即为BlockIntegrityMonitor的主要任务。
为对失效数据检测,HDFS RAID增加NN接口listCorruptFileBlocks,RaidNode经过DFSck调用NN的接口listCorruptFileBlocks获取CorruptFile集合。NN端直接query neededReplications获得结果。由于RAID后Source File和Parity File之间相互提供可靠性保证,所以不管Source File或者Parity File中的部分内容失效均可以通过剩下的数据重建,当然最大可容忍失效的Block数与Erasure Code算法和副本数相关。
BlockIntegrityMonitor有两种工作模式:LocalBlockIntegrityMonitor和DistBlockIntegrityMonitor。
LocalBlockIntegrityMonitor在本地完成数据完整性检测和重建模式,简称本地模式。本地模式只检测和修复Corruption数据,另外它的检测和计算任务均有本地节点完成。本地模式在扩展性上存在很大的弊端。
DistBlockIntegrityMonitor分布式数据完整性检测和重建模式,简称分布式模式。分布式模式检测和修复Corruption数据和Decommissioning数据,它的修复计算任务通过MR Job完成。相应的分布式模式提供了CorruptionWorker、CorruptFileCounter和DecommissioningWorker三个工作线程,其中CorruptFileCounter监控CorruptFile数量,默认10min扫描一次;CorruptionWorker监控和重建CorruptFile数据,默认1min扫描一次;DecommissioningWorker针对Decommissioning数据,默认1min扫描一次。(这三个工作线程默认全路径扫描。)
1、CorruptFileCounter(counter)
2、CorruptionWorker/DecommissioningWorker(fixer/copier)
CorruptionWorker/DecommissioningWorker执行相同的MR作业,区别是处理的文件(getLostFiles)及优先级算法(computePriorities)不同。
Worker | getLostFiles | computePriorities |
| CorruptionWorker | dfsck-list-corruptfileblocks-limitreturn:filename及corrupt blk数 | 结果:HIGH | LOW数据损坏如果不及时恢复一旦积累到一定数量可能完全不能恢复,所以corruptfile的优先级较高。 |
| DecommissioningWorker | dfsck-list-corruptfileblocks-list-decommissioningblocks-limitreturn:filename及decommission blk数 | 结果:LOW | LOWEST数据下线可以由原生HDFS的Repllication策略解决,不会带来严重后果,所以优先级较低。(?) |
(2)PurgeMonitor
PurgeMonitor监控线程:默认10s扫描一次,主要针对DirectoryFilter (ParityPath无对应SourcePath)、PurgeParityFileFilter和PurgeHarFilter结果的删除功能。
前面多次出现DirectoryTraversal,它的注释很好说明了其功能:
Traverses the directory tree and gets the desired FileStatus specified by a given {@link DirectoryTraversal.Filter}. This class is not thread safe.
遍历指定目录获取符合DirectoryTraversal.Filter的文件集合。DirectoryTraversal的主要处理逻辑通过其内部类Processor实现。Processor主要思想是从给定目录为起点深度优先遍历目录树。
下列是五类不同功能的DirectoryTraversal.Filter:
FileFilter所有文件
DirectoryFilter所有目录
RaidFileFilter需RAID还未RAID的文件集合
PurgeParityFileFilter与Source文件不对应的Parity文件集合
PurgeHarFilter无用HAR目录集合
(3)PlacementMonitor&BlockMover
同HDFS中Block分配策略BlockPlacementPolicy相似,HDFS RAID提供了针对stripeBlocks(source blocks + parity blocks)的检测分配策略。与BlockPlacementPolicy分发数据前根据策略选择合适节点不同,RAID的PlacementMonitor是事后检测行为,随PurgeMonitor线程执行。
PlacementMonitor监控线程主要检测stripe blocks(source/parity)是否有多个block分布在一个节点。一旦发现立即分散。
(4) Policy&TriggerMonitor
TriggerMonitor线程的运行依赖配置规则raid-site.xml,读入内存以PolicyInfo存在,后台线程每间隔10s检查一次是否需要重新Load配置文件到PolicyInfo。
PolicyInfo可接受配置文件raid-site.xml的多个Policy的配置项,每一个Policy的选项里目前仅可以识别下面几个参数:
Element | Define |
| name | Policy名称 |
| srcPath | 目录 |
| fileList | 文件路径,存放需要raid的文件路径集合/支持正则表达式 |
| erasureCode | 编码类型xor/rs |
| shouldRaid | 是否需要raid |
| description | 描述 |
| parentPolicy | —- |
| property | 属性 |
TriggerMonitor根据配置文件raid-site.xml配置的Policy对尚未RAID的文件集合执行Raid操作。
(5)BlockReconstructor
HDFS RAID允许数据块异常、数据丢失乃至节点故障。当出现上述情况时需及时发现尽快重建。数据重建工作即为BlockReconstructor。
BlockReconstructor包括对两类数据的重建:SourceFile和ParityFile。不管是SourceFile或ParityFile的数据恢复,入口均为reconstructFile。通过文件路径[/{raid,rsraid}/$path]判断文件是source/parity,然后调用lostBlocksInFile获取文件内出现异常数据的数据块,接着根据文件类型和数据块确定重建方式,对异常数据块逐个进行重建。
xor | rs | |
source | xorDecoder | rsDecoder |
parity | xorEncoder | rsEncoder |
五、问题
RAID不是万能的,依然存在诸多问题,表现在:
1、集群压力增加
最直接的表现就是元数据量显著增加,每一个原始文件都会在目标目录里生成对应的校验文件,对NameNode带来压力;RaidNode对NameNode的频繁访问,给NameNode的RPC处理能力带来负载;一旦发生数据丢失,需要读取多个Block数据用于恢复数据,增加额外的网络及IO负载;副本数降低后势必会对本地性造成影响,所以需要结合实际业务场景充分考虑冷热数据的划分标准。
2、数据安全问题
RAID与Balancer之间的矛盾,由于Balancer不能理解Block属于哪个文件,所以极有可能Balance之后将原始文件和校验文件的Block保存在相同的DataNode上,增加丢块的风险。
3、作业数据倾斜问题
RaidNode批量操作数据执行Raid时,暂时还没有充分考虑数据的规模,可能造成由于少量大文件带来数据倾斜的问题。
六、总结
虽然RAID能够节约存储空间,但是由于其出错概率且计算复杂度高不适于所有数据,一般用于集群中部分冷数据。存放在HDFS上的数据分为热数据和冷数据两种。热数据因为经常被用到,一般存放默认三个副本,这样可以达到高效冗余和负载均衡的作用。对于冷数据,通过不同的RAID策略降低副本数。比较常见的方案是,对于不太冷的数据块A/B/C,通过XOR方式产生parity数据块,原始数据块A/B/C和parity数据块各保留2个副本,这样,理论上副本数就从3减小到了2.7=(3×2+2)/3,实际可能会稍微多于该值。对于较冷的数据(如访问时间在3个月之前),方案可以更加激进,由10个数据块通过Reed Solomon算法生成4个parity数据块,原始数据块只保留一个副本,parity数据块有2份副本,这样副本数就降到了1.4,当然也是理论值。图3示前面所述的冷热数据分布和其容错能力情况。

图3 不同用途数据的分布方式及容错能力
RAID将向两个方向发展:一方面由于RAID的低成本高可靠的优势,社区也在持续投入大量精力优化升级(https://issues.apache.org/jira/browse/HDFS-8031),针对Raid存在的问题进行优化,比如引入LRC减少网络和IO负载等;另一方面,在摩尔定律的作用下存储设备价格持续下降,同时RAID对元数据量增加、高出错概率、密集计算资源和网络IO占用等要素叠加不得不重新思考Hadoop中RAID的必要性。
六、参考资料
[1] Facebook-Hadoop. https://github.com/facebook/hadoop-20
[2] HDFS-RAID. http://wiki.apache.org/hadoop/HDFS-RAID
[3] Erasure Code. http://en.wikipedia.org/wiki/Erasure_code
[4] Hadoop jira. https://issues.apache.org/jira/browse/HDFS
[5] DataScientist. http://yanbohappy.sinaapp.com
[6] Jiangbo. http://jiangbo.me
[7] FB Pres. http://hbtc2012.hadooper.cn/subject/track1dongsiying4.pdf
利益相关:无。
免责声明:部分引用均在参考资料里说明。
题图:Fly Hadoop
--------------------------------------
如对内容感兴趣,需要订阅请长按二维码:

