




一、概述
Hadoop IPC在整个Hadoop生态系统中扮演非常通用和基础的角色,包括HDFS、MapReduce、HBase以及YARN内部各组件之间的RPC交互几乎都依赖大致相同的IPC框架实现,分析Hadoop的IPC实现原理对理解整个Hadoop生态系统内各系统都会有极大的帮助。
这里通过从具体的实现抽象出Hadoop IPC框架的实现逻辑,一方面能够更深入的理解和积累,另一方面希望能够对想了解Hadoop底层RPC交互过程的同学提供帮助。
Hadoop实现了一套简单且高效的IPC(Inter-Process Communication)机制,没有直接使用Java RMI。主要原因在于有效的IPC对于Hadoop至关重要,Hadoop自身对连接控制、超时、缓存等通信细节需要更加精确的掌控。
二、架构
Hadoop IPC的实现基于Java动态代理、Java NIO和多线程技术。
Hadoop IPC代码在在hadoop-common子工程下org.apache.hadoop.ipc包中。主要实现在以下三个关键类中:
Client:IPC客户端逻辑,主要包含IPC连接(Client.Connection, Client.ConnectionId)和远程调用(Client.Call)。
Server:IPC服务端逻辑,主要包含IPC连接(Server.Connection)和远程调用处理(Server.Call, Server.Listener, Server.Handler, Server.Responder)。
RPC:在Client和Server基础上实现了Hadoop IPC。
从图1所示Hadoop IPC整体架构可以清楚看到客户端和服务端交互时数据的流动方式和过程。
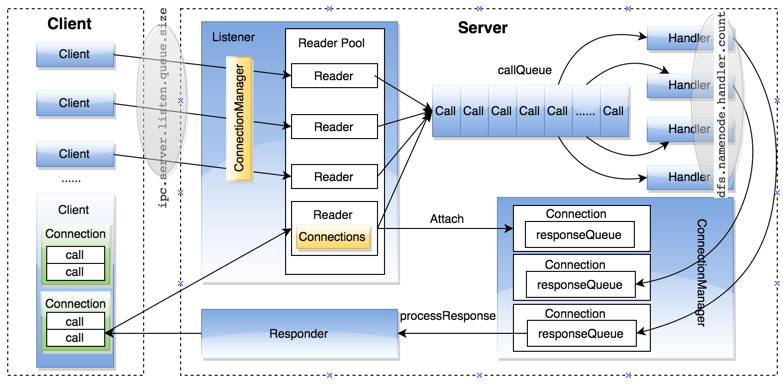
图1 Hadoop IPC整体架构
2.1 Client
Client端通过阻塞IO的方式达到轻量级的目标。Client端主要包含以下几个主要的数据结构:
Call:封装了一个RPC请求,包含成员:唯一ID、函数调用信息param(包含函数名称及参数)、函数返回值value、函数异常信息error、函数完成标识done。ipc server采用异步方式处理Client请求,使得RPC的发生顺序和返回顺序无直接关系,而Client通过ID识别不同的函数调用。当Client向Server发送请求,只需填充ID和param两个变量,其余3个变量由Server根据函数执行情况填充。
Connection:是Client和Server之间的一个通信连接,封装了连接相关的基本信息和操作。包括:连接唯一标识remoteId(ConnectionId)、与Server端通信的Socket、网络输入输出流in/out、保存同一个连接内多个RPC请求的哈希表calls(Hashtable<Integer, Call>)。其中在Connection内部可以通过addCall将一个Call对象添加到哈希表calls中,sendParam向服务端发送RPC请求,receiveResponse从服务端接收已经处理完成的RPC请求,run调用receiveResponse方法,等待返回结果。
ConnectionId:连接Connection标记,包括Server地址,协议,其他一些连接的配置项信息,通过ConnectionId来区分客户端与多个Server之间建立的连接关系。
Client的整个实现逻辑相对比较简单:
1、创建一个Connection对象,并将RPC信息封装成Call对象,放到Connection对象中的哈希表中;
2、调用Connection类中的sendRpcRequest()方法将当前Call对象发送给Server端,并等待结果返回;
3、Server端处理完RPC请求后,将结果通过网络返回给Client端,Client端通过receiveRpcResponse()函数获取结果;
4、Client检查结果处理状态(成功还是失败),将其返回给上层应用,并将对应Call对象从哈希表calls中删除。
2.2 Server
Server端相比Client端相对要复杂些,Server端通过线程池、Selector、异步非阻塞等技术实现高并发和可扩展的目标。
在Master/Slave架构下,Master是整个系统的单点,这是制约系统性能和可扩展性的最关键因素;Master通过ipc.Server接收并处理所有Slave发送的请求,这就要求其将高并发和可扩展性作为设计目标。Hadoop相关子系统在这点上体现尤为明显。
按照Server对RPC的处理流程,可以分为三个阶段:接收、执行和返回。
1、接收
该阶段主要任务是接收来自Client的RPC请求,并将它们封装成固定的格式(Call类)放到共享队列(callQueue)中,以便进行后续处理。该阶段内部又分为连接监听和接收请求两个子阶段,分别由Listener和Reader两个线程完成。
整个Server只有一个Listener线程,统一负责监听来自Client的连接请求,一旦有新的请求到达,它会采用轮询的方式从线程池中选择一个Reader线程进行处理,而Reader线程可同时存在多个(默认为128个),它们分别负责接收部分Client连接的RPC请求,至于每个Reader线程负责哪些Client连接,完全由Listener决定,当前Listener采用Round-Robin方式。
Listener和Reader线程内部各自包含一个Selector对象,分别用于监听SelectionKey.OP_ACCEPT和SelectionKey.OP_READ事件。对于Listener线程,主循环的实现体是监听是否有新的连接请求到达,并采用轮询策略选择一个Reader线程处理新连接;对于Reader线程,主循环的实现体是监听它负责的那部分Client连接中是否有新的RPC请求到达,并将新的RPC请求封装成Call对象,放到共享队列callQueue中。需要说明的是callQueue本身有空间大小限制,默认大小为3200,当在高并发请求情况下,如果Server处理RPC请求不及时就会出现callQueue被打满的情况。
2、执行
该阶段主要任务是从共享队列callQueue中获取Call对象,通过动态代理技术调用上层应用的对应函数,并通过Connection将结果返回给Client,这一系列动作全部由Handler线程完成。
Server端可同时存在多个Handler线程,默认为32个Handler,它们并行从共享队列中读取Call对象,经执行对应的函数调用后,将尝试着直接将结果返回给对应的客户端,但考虑到某些函数调用返回结果数据规模大或者网络异常原因,可能难以将结果一次性发送到Client端,此时Handler将尝试着将后续发送任务交给Responder线程异步返回,这样空闲出来的Handler就能继续处理后续请求。
3、返回
每个Handler线程执行完函数调用后,会尝试着将执行结果通过Connection返回给Client,但对于特殊情况,比如函数调用返回结果数据规模较大或者网络异常情况,会将发送任务交给Responder线程。
Server端仅存在唯一的Responder线程,它的内部包含一个Selector对象,用于监听SelectionKey.OP_WRITE事件。当Handler不能将结果一次性发送到Client时,会向该Selector对象注册SelectionKey.OP_WRITE事件,进而由Responder线程采用异步方式继续发送未发送完成的结果。
三、总结
1、整理了Hadoop IPC的整体架构;
2、分别对Client/Server具体实现逻辑进行了总结;
四、参考
[1]https://github.com/apache/hadoop/tree/branch-2.7.1/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/ipc
[2]https://wiki.apache.org/hadoop/ipc
