




1、DStream缓存和持久化
同RDD类似,DStream也允许开发人员手动控制,将流式数据保存到内存中,也就是说,在DStream上可以通过调用persist()方法将该DStream的每个RDD数据保存到内存中。如果DStream中的数据将被多次计算(如相同数据上执行多个操作),那么这个操作就会非常有用,因为多次计算操作可以共享同一份数据。对于基于窗口的算子操作,如reduceByWindow和reduceByKeyAndWindow以及基于状态的操作,如updateStateByKey,默认就开启了持久化的机制,数据会默认进行持久化。因此,基于窗口操作生成的DStream,数据会自动保存到内存中,而不需要开发人员调用persist()方法。
DStream支持的persist级别同RDD一致,这里再列举如下表:
存储级别 | 解释 |
MEMORY_ONLY | 将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别。 |
MEMORY_AND_DISK | 以反序列化的JAVA对象的方式存储在JVM中. 如果内存不够, RDD的一些分区将将会缓存在磁盘上,再次需要的时候从磁盘读取 |
MEMORY_ONLY_SER | 以序列化JAVA对象的方式存储 (每个分区一个字节数组). 相比于反序列化的方式,这样更高效的利用空间, 尤其是使用快速序列化时。但是读取是CPU操作很密集。 |
MEMORY_AND_DISK_SER | 与MEMORY_ONLY_SER相似, 区别是但内存不足时,存储在磁盘上而不是每次重新计算 |
DISK_ONLY | 只存储RDD在磁盘 |
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc | 与上面的级别相同,只不过每个分区的副本只存储在两个集群节点上。 |
OFF_HEAP (experimental) | 与MEMORY_ONLY_SER类似,但将数据存储在非堆内存中。这需要启用非堆内存。 |
而对于通过网络接收数据的输入流(如Kafka,Flume,Socket等),默认持久化级别被设置为将数据复制到两个节点进行容错。这里需要特别注意的一点是,与RDD不通,默认的持久化级别,统一都是要进行序列化的。
2、Spark Streaming检查点支持
Spark Streaming应用程序如果不手动停止,则将会一致运行下去,在实际生产环境中一般都是24小时*7天不间断地运行。因此,SparkStreaming应用必须对与程序逻辑无关的故障(例如,系统故障,JVM崩溃等)具有很强的弹性,具备一定的非应用程序出错的容错性。为了实现这一特性,Spark Streaming的Checkpoint机制应运而生,它将足够多的信息checkpoint到某些具备容错性的存储系统上,如HDFS,以便出错时能够迅速从故障中进行恢复。
适合使用检查点的两种类型的数据
(1)元数据检查点(Metadata checkpointing):将流式计算的信息保存到具备容错性的存储系统中(如HDFS)。这适用于当Spark Streaming应用程序的driver程序所在的节点出错时,从故障中进行恢复。该类元数据包括以下几种:
配置(Configuration)——用于创建Spark Streaming应用程序的配置信息;
DStream操作(DStream Operation) ——在Spark Streaming应用程序中定义的DStream操作;
不完整的Batch(Incomplete Batch)——作业仍在队列中,但尚未完成的Batch。
(2)数据检查点(Data checkpointing):将生成的RDD保存到外部可靠的存储系统层。对于一些数据跨度为多个Batch的有状态的transformation操作来说(即将多个批次之间的数据进行组合的状态转换操作),设置数据检查点是非常有必要的。因为在这些转换操作中,当前生成的RDD依赖于先前批次的RDD,随着时间的推移,依赖链的长度可能会变得非常长,由此会导致基于血统机制的恢复时间无限增加。为了避免这种情况,为状态装换的中间RDD定期设置检查点并保存到可靠的存储系统中(如HDFS)以切断依赖关系链。
总的来说,元数据检查点主要用于从driver程序故障中进行恢复,而数据或RDD检查点在任何使用状态转换操作时是必须要使用的。
什么时候启用检查点?
既然检查点的作用这么大,那么什么时候该启用checkpoint呢?通常来说,对于具有以下任一要求的Spark Streaming应用程序都必须启用检查点:
(1)使用了状态转换操作:如果在Spark Streaming应用程序中使用了updateStateByKey或reduceByKeyAndWindow(具有逆函数)等状态转换操作,则必须提供检查点目录以允许定期保存RDD检查点;
(2)从Spark Streaming应用程序的driver程序故障中恢复:元数据检查点用于使用进度信息,进行恢复。
如何使用检查点?
使用检查点,需要设置一个支持容错的、可靠的文件系统(如HDFS、S3等)目录来保存检查点数据信息,可以通过调用streamingContext.checkpoint (checkpointDirectory)来完成。设置了检查点后。就可以使用上述的有状态转换操作。此外,如果要使Spark Streaming应用程序能够从driver程序故障中进行恢复,需要重写Spark Streaming应用程序以使程序具有如下行为:
(1)当程序第一次启动时,它将创建一个新的StreamingContext实例,设置好所有流数据源,然后调用start()方法;
(2)当程序在运行失败后重新启动时,它将基于checkpoint目录中的检查点数据重新创建一个StreamingContext实例;
通过使用StreamingContext.getOrCreate可以达到目的,使用方法如下图所示:
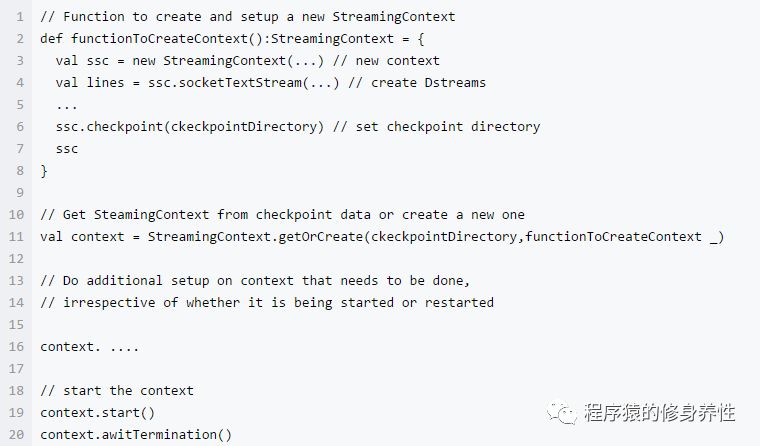
如果checkpointDirecrory存在,那么context将导入checkpoint数据;如果该目录不存在,函数functionToCreateContext将被调用并创建新的context。除调用getOrCreate方法外,还需要集群模式支持driver挂掉之后重启。例如,在yarn模式下,driver是运行在ApplicationMaster中,若ApplicationMaster挂掉,yarn会自动在另一个节点上启动一个新的ApplicationMaster。
需要注意的是,随着Spark Streaming应用程序的持续运行,checkpoint数据占用的存储空间会不断变大。因此,需要小心设置checkpoint的时间间隔,设置的越小,checkpoint次数会越多,占用存储空间会越大;如果设置越大,会导致恢复时丢失的数据和进度越多。一般情况下设置为batch duration的5~10倍比较合适。
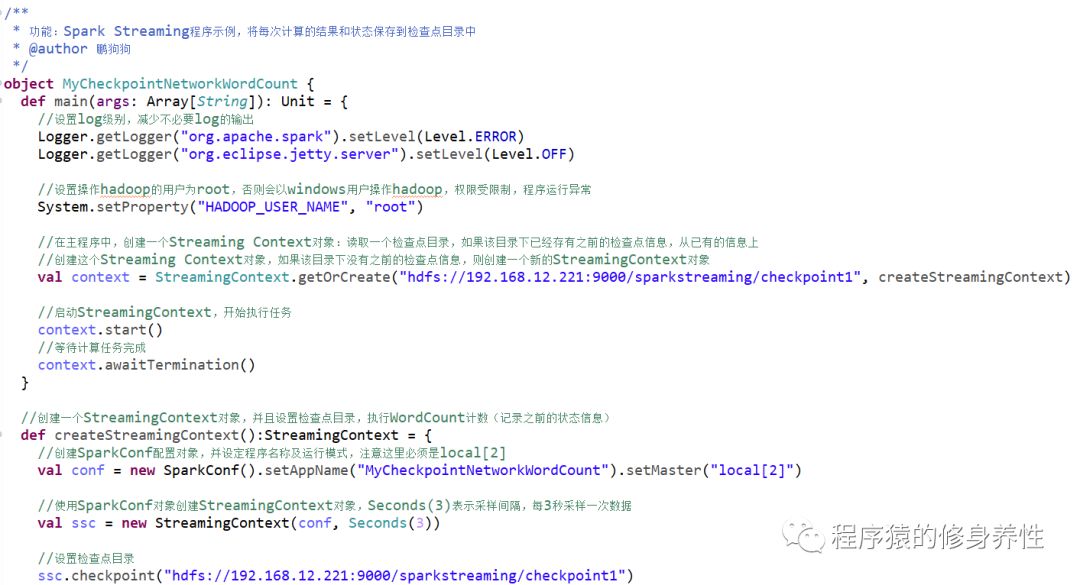
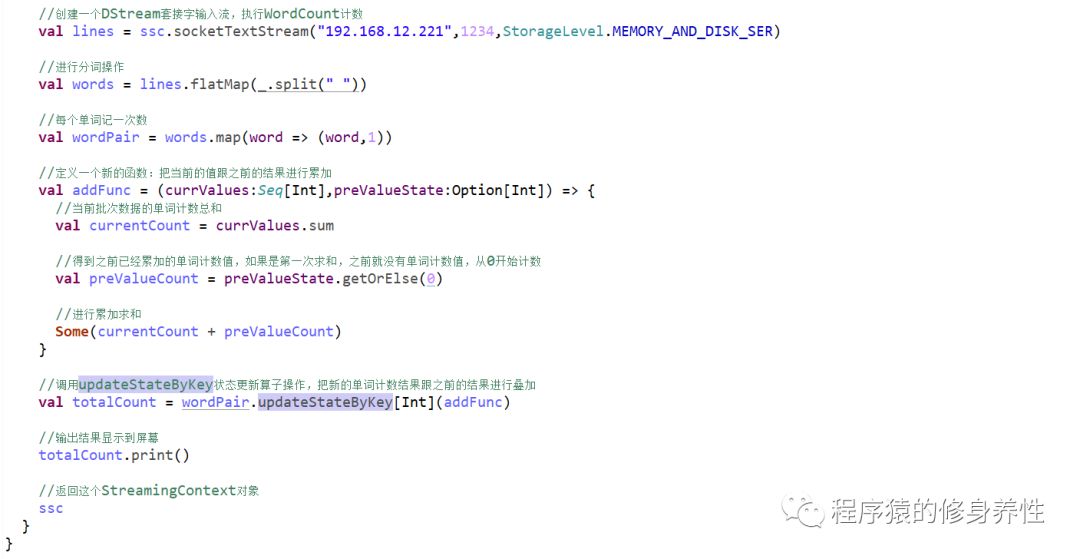
重写前文的MyNetworkWordCount程序,将每次计算的结果和状态保存到检查点目录中
代码如下图所示:
运行结果如下图所示:
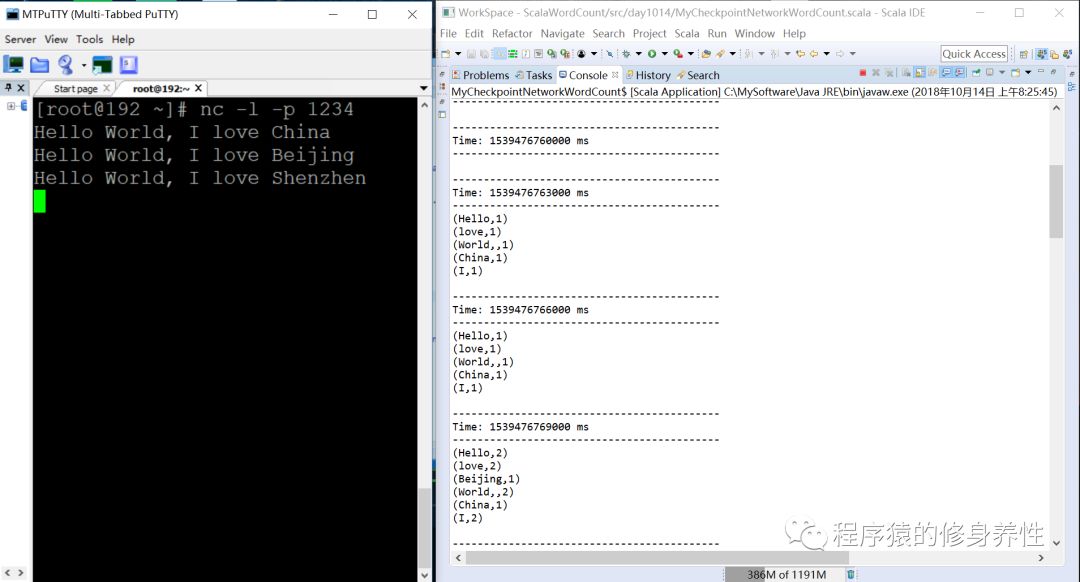
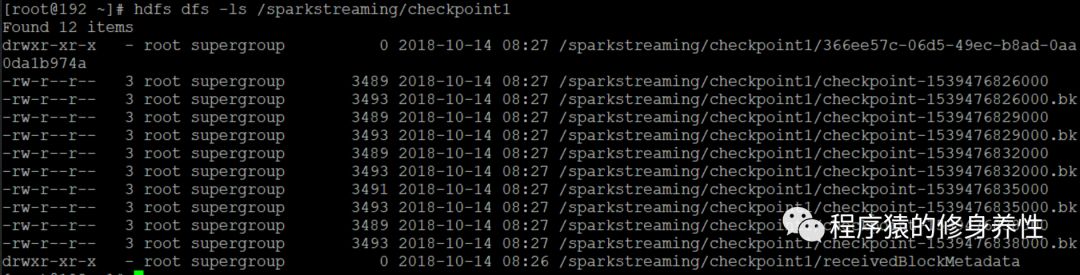
查看HDFS中检查点目录hdfs://192.168.12.221:9000/sparkstreaming/checkpoint1中保存的数据文件信息,如下图所示,/sparkstreaming/checkpoint1/receivedBlockMetadata文件中保存的便是元数据信息,其他文件中保存的是数据信息。
3、高级数据源
A、Spark Streaming接收Flume数据
基于Flume的Push模式
Flume被用于在Flumeagents之间推送数据,在这种方式下,Spark Streaming可以很方便的建立一个receiver,起到一个Avro agent的作用,Flume可以将数据主动推送到该receiver。
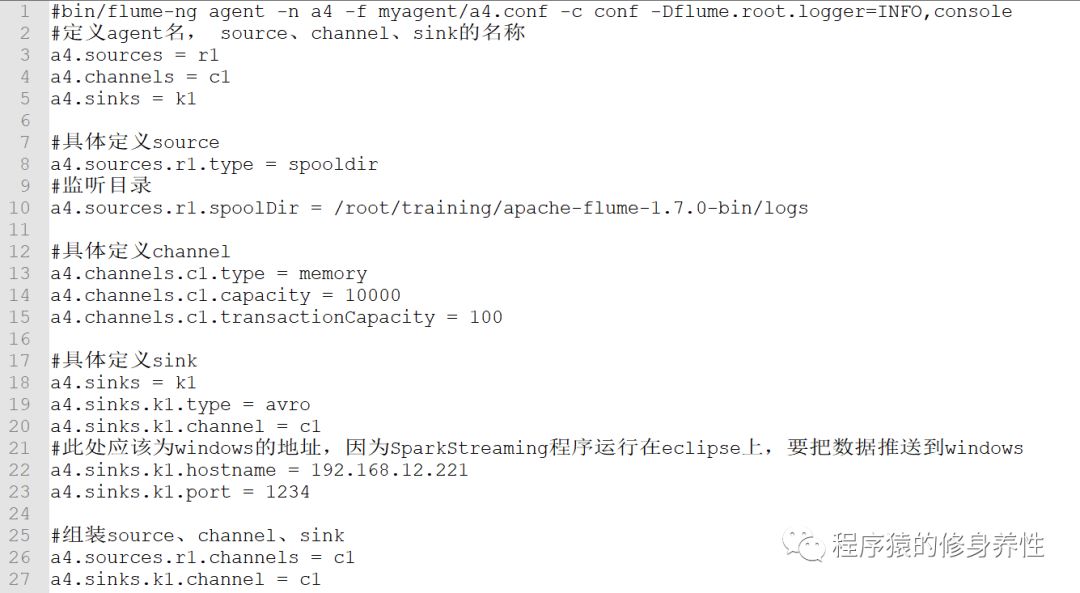
(1)构造Flume配置文件:a4.conf
a4.conf配置文件中的代码如下图所示:
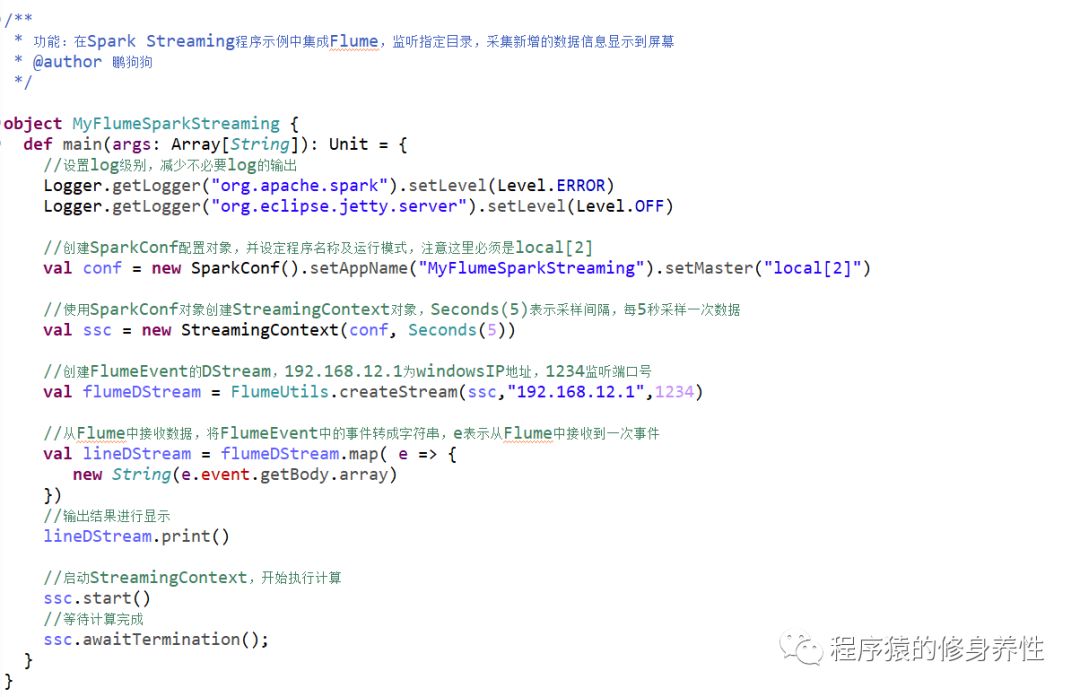
(2)编写Spark Streaming程序
这里编写的是Spark Streaming程序,由于集成了Flume,因而需要导入Flume相关的jar包,将/root/training/apache-flume-1.7.0-bin/lib目录下的所有jar包导入到该项目工程中,同时还额外需要导入一个jar,即spark-streaming-flume_2.10-2.1.0.jar。程序代码如下图所示:
(3)运行程序,进行测试
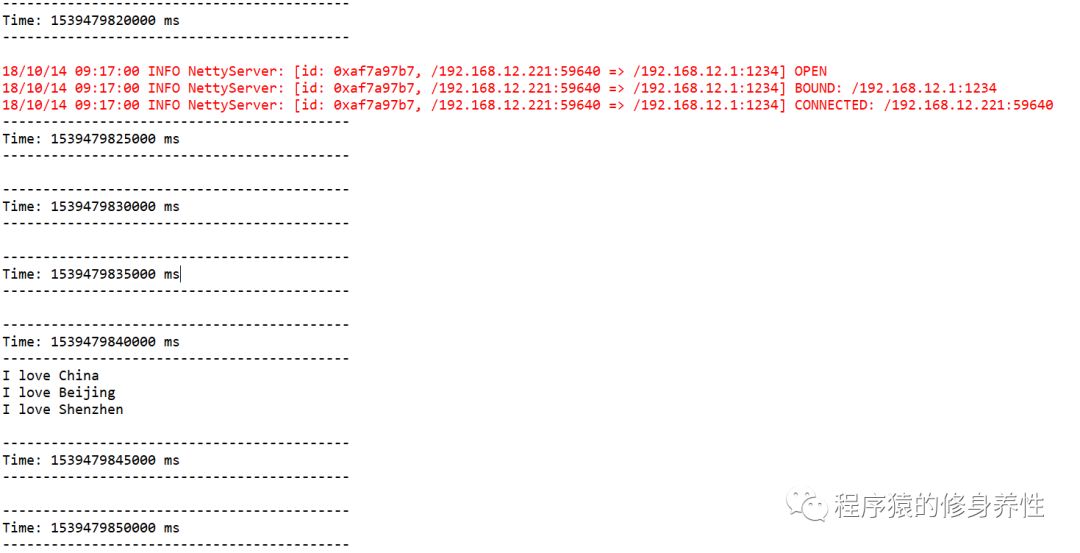
首先,运行Spark Streaming程序,监听1234号端口获取数据;然后创建一个文件flumetestfile.txt,在其中添加如下内容:
I loveChina
I loveBeijing
I loveShenzhen
再启动Flume,执行命令bin/flume-ng agent -n a4 -fMyAgent/a4.conf -c conf -Dflume.root.logger=INFO,console;最后将文件flumetestfile.txt拷贝到/root/training/apache-flume-1.7.0-bin/logs目录下,观察eclipse控制台输出,运行结果如下图所示:
基于Flume CustomSink的Pull模式
不同于Flume直接将数据推送到Spark Streaming程序中,这种模式通过以下条件运行一个正常的Flumesink。Flume将数据推送到sink中,并且数据保持buffered状态。Spark Streaming使用一个可靠的Flume接收器和转换器从sink拉取数据。只要当数据被接收并且被Spark Streaming备份后,转换器才运行成功。
这样,与前一种模式相比,保证了很好的健壮性和容错能力。然而,这种模式需要为Flume配置一个正常的sink。
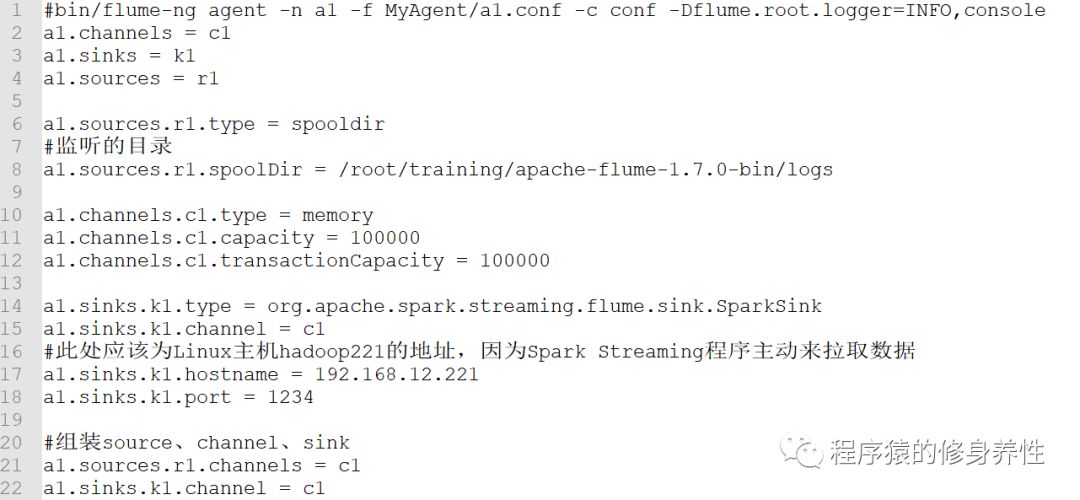
(1)构造Flume配置文件:a1.conf
a1.conf配置文件中的代码如下图所示:
(2)编写Spark Streaming程序
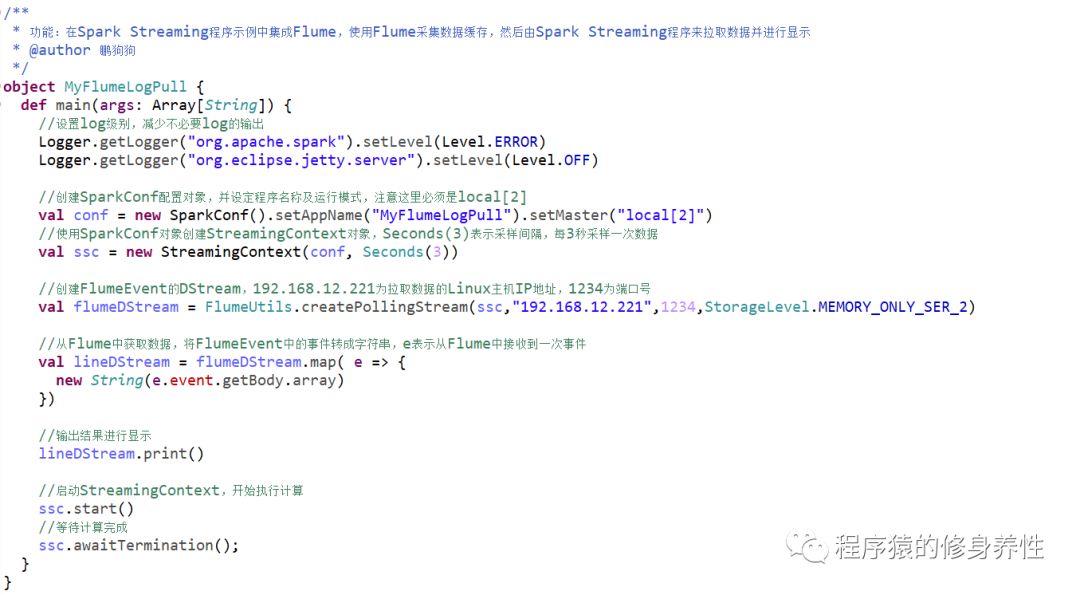
这里编写的是Spark Streaming程序,由于集成Flume,采用Pull模式获取数据,因而需要在Flume相应目录下导入Spark的jar包,将/root/training/spark-2.1.0-bin-hadoop2.7/jars目录下所有的jar包拷贝到Flume的/root/training/apache-flume-1.7.0-bin/lib目录下,并且额外将spark-streaming-flume-sink_2.10-2.1.0.jar也拷贝到该目录下;除此之外,在Scala工程中也将该jar包添加buildpath中。程序代码如下图所示:
(3)运行程序,进行测试
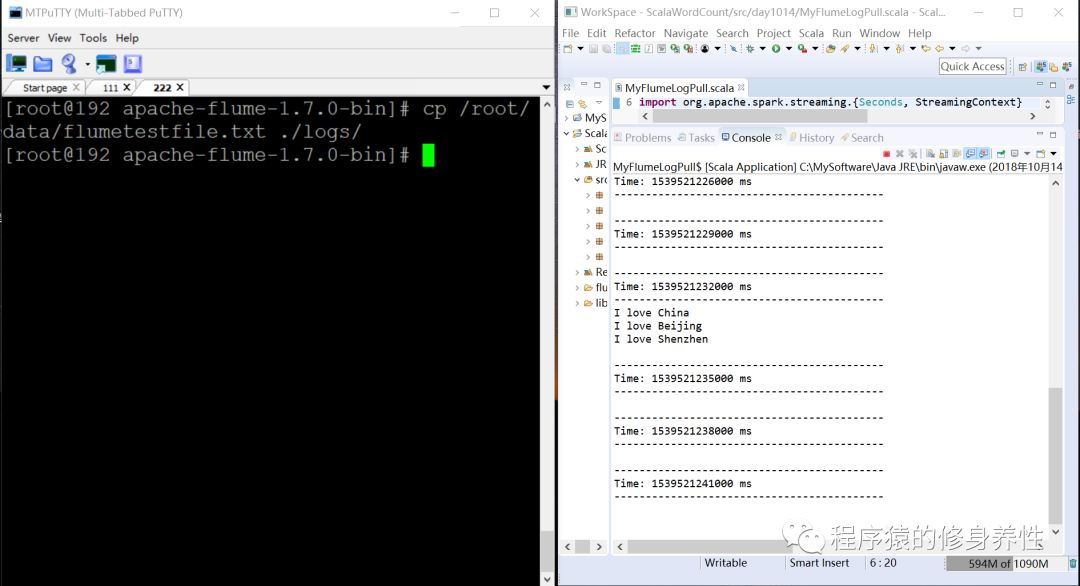
首先,运行命令bin/flume-ng agent -n a1 -f MyAgent/a1.conf -c conf-Dflume.root.logger=INFO,console,启动Flume进行监听;然后,运行Spark Streaming程序,从1234号端口获取数据;再拷贝文件flumetestfile.txt到/root/training/spark-2.1.0-bin-hadoop2.7/logs目录下,可以看到运行结果如下图所示。程序采集到了flumetestfile.txt文件中的内容,并显示到了eclipse的控制台界面。
B、Spark Streaming接收Kafka数据
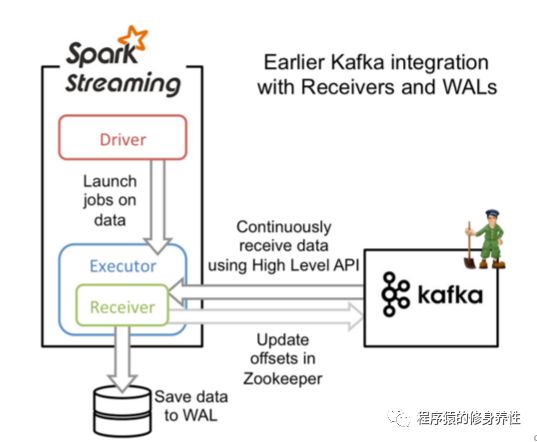
基于Receiver的方式
这个方式使用了Receiver来接收数据,Receiver的实现使用到Kafka高层次的消费者API,对于所有的Receiver,接收到的数据将会保存在Spark executors中,然后由Spark Streaming启动的任务Job来对这些数据进行处理,整个过程简单描述如下图所示:
基于Kafka Receiver方式的Spark Streaming程序代码如下图所示:
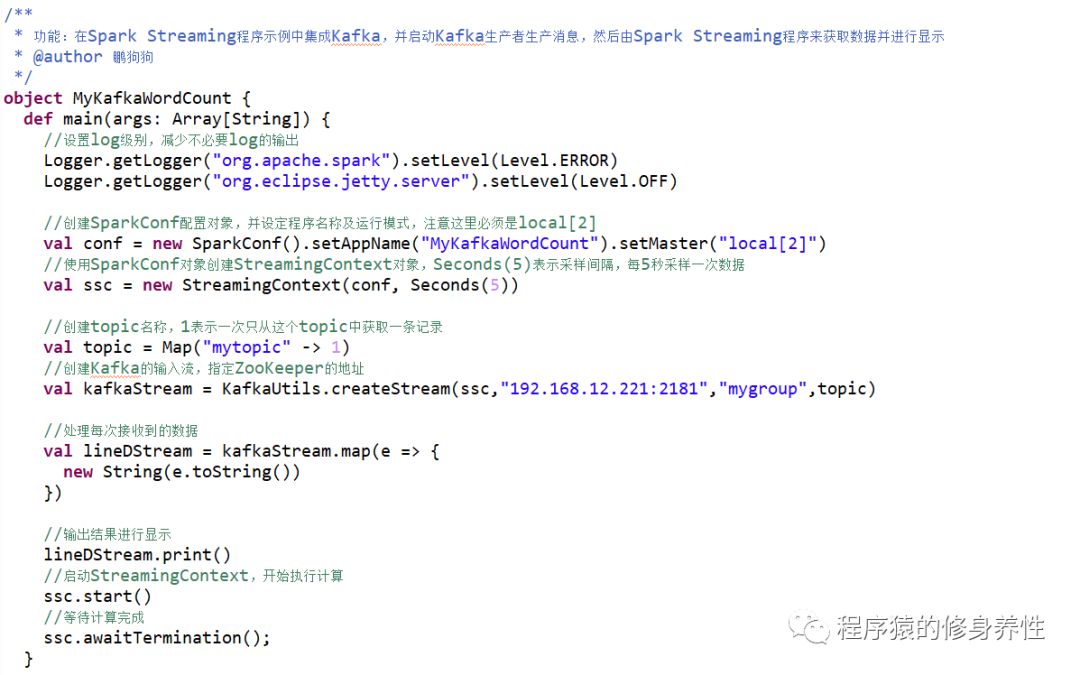
在运行该程序进行测试实验时,需要先运行命令kafka-server-start.sh config/server.properties &,以后台方式启动Kafka,然后运行命令kafka-topics.sh --create--zookeeper hadoop221:2181 -replication-factor 1 --partitions 3 --topic mytopic,创建主题mytopic,再运行命令kafka-console-producer.sh--broker-list hadoop221:9092 --topic mytopic,启动一个生产者,以生产消息。
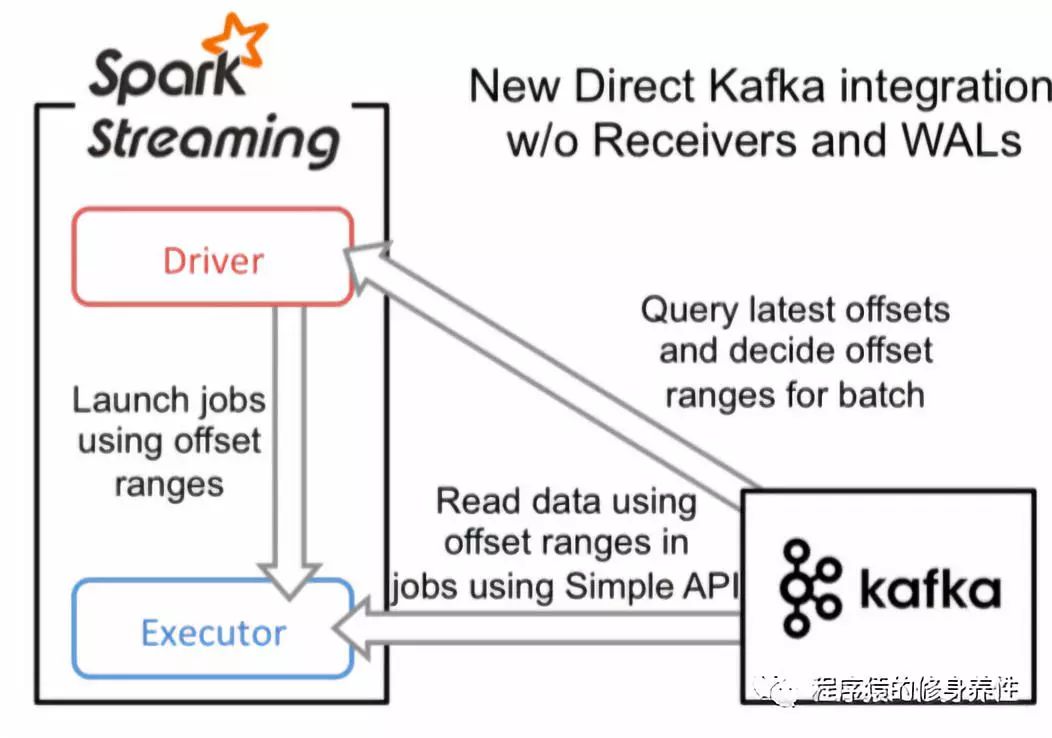
直接读取的方式
同基于Receiver接收数据的方式不一样,这种方式定期地从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里面处理数据。当作业需要处理的数据来临时,Spark通过调用Kafka的简单消费者API读取一定范围的数据,该过程如下图所示:
基于直接读取方式的SparkStreaming程序代码如下图所示:
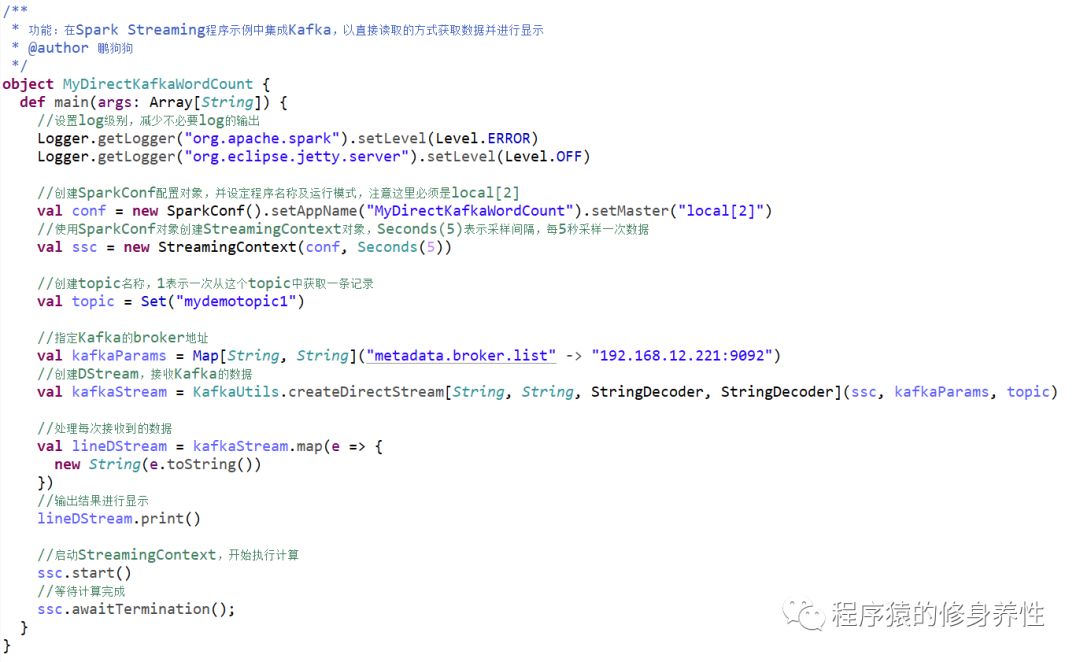
在运行该程序进行测试实验时,需要先运行命令kafka-topics.sh --create --zookeeper hadoop221:2181-replication-factor 1 --partitions 3 –topic mydemotopic1,创建主题mydemotopic1,再运行命令kafka-console-producer.sh--broker-list hadoop221:9092 --topic mydemotopic1,启动一个生产者,以生产消息。
4、Spark Streaming性能优化
A、减少批数据的执行时间
在Spark Streaming中,有几个优化措施可以减少批处理的时间:
(1)数据接收的并行水平
通过网络(如kafka,flume,socket等)接收数据需要这些数据反序列化并被保存到Spark中。如果数据接收成为系统的瓶颈,就要考虑并行地接收数据。注意,每个输入DStream创建一个receiver(运行在worker机器上)接收单个数据流。创建多个输入DStream并配置它们可以从源中接收不同分区的数据流,从而实现多数据流接收。例如,接收两个topic数据的单个输入DStream可以被切分为两个kafka输入流,每个接收一个topic。这将在两个worker上运行两个receiver,因此允许数据并行接收,提高整体的吞吐量。多个DStream可以被合并生成单个DStream,这样运用在单个输入DStream的transformation操作可以运用在合并的DStream上。

(2)数据处理的并行水平
如果运行在计算stage上的并发任务数不足够大,就不会充分利用集群的资源。默认的并发任务数通过配置属性来确定spark.default.parallelism。
(3)数据序列化
可以通过改变序列化格式来减少数据序列化的开销。在流式传输的情况下,有两种类型的数据会被序列化:
输入数据
由流操作生成的持久RDD
在上述两种情况下,使用Kryo序列化格式可以减少CPU和内存开销。
B、设置正确的批容量
为了Spark Streaming应用程序能够在集群中稳定运行,系统应该能够以足够的速度处理接收的数据(即处理速度应该大于或等于接收数据的速度)。这可以通过流的网络UI观察得到。批处理时间应该小于批间隔时间。
根据流计算的性质,批间隔时间可能显著的影响数据处理速率,这个速率可以通过应用程序维持。可以考虑WordCountNetwork这个例子,对于一个特定的数据处理速率,系统可能可以每2秒打印一次单词计数(批间隔时间为2秒),但无法每500毫秒打印一次单词计数。所以,为了在生产环境中维持期望的数据处理速率,就应该设置合适的批间隔时间(即批数据的容量)。
找出正确的批容量的一个好的办法是用一个保守的批间隔时间(5-10,秒)和低数据速率来测试你的应用程序。
C、内存调优
在这一节,我们重点介绍几个强烈推荐的自定义选项,它们可以减少Spark Streaming应用程序垃圾回收的相关暂停,获得更稳定的批处理时间。
Defaultpersistence level of DStreams:和RDDs不同的是,默认的持久化级别是序列化数据到内存中(DStream是StorageLevel.MEMORY_ONLY_SER,RDD是StorageLevel.MEMORY_ONLY)。即使保存数据为序列化形态会增加序列化/反序列化的开销,但是可以明显的减少垃圾回收的暂停。
Clearingpersistent RDDs:默认情况下,通过Spark内置策略(LUR),Spark Streaming生成的持久化RDD将会从内存中清理掉。如果spark.cleaner.ttl已经设置了,比这个时间存在更老的持久化RDD将会被定时的清理掉。正如前面提到的那样,这个值需要根据SparkStreaming应用程序的操作小心设置。然而,可以设置配置选项spark.streaming.unpersist为true来更智能的去持久化(unpersist)RDD。这个配置使系统找出那些不需要经常保有的RDD,然后去持久化它们。这可以减少Spark RDD的内存使用,也可能改善垃圾回收的行为。
Concurrentgarbage collector:使用并发的标记-清除垃圾回收可以进一步减少垃圾回收的暂停时间。尽管并发的垃圾回收会减少系统的整体吞吐量,但是仍然推荐使用它以获得更稳定的批处理时间。
5、Spark StructuredStreaming基础介绍
A、Spark StructuredStreaming概述
从Spark 2.0版本开始,新增了Spark Structured Streaming,它是构建在Spark SQL引擎之上的流式数据处理引擎,使得实时流式数据计算可以和离线计算采用相同的处理方式(如DataFrame和SQL查询)。顾名思义,Spark Structured Streaming将数据源和计算结果都映射成一张“结构化”的表,在计算的时候以结构化的方式去操作数据流,大大方便和提高了流式计算应用程序开发的效率。
Spark Streaming VS Spark StructuredStreaming
在Spark 2.0版本之前,流式计算都是通过Spark Streaming进行,如下图所示:

使用SparkStreaming进行流式计算存在一定的不足,也就是每次只能消费当前批次内的数据,当然呢,可以通过窗口操作,消费过去一段时间内(多个批次)的数据。举个简单的实际案例,需要每隔10秒钟,统计当前小时内的PV和UV,在数据量特别大的情况下,使用窗口操作并不是很好的选择,而通常是借助其它工具,如Redis、HBase等来完成数据统计。
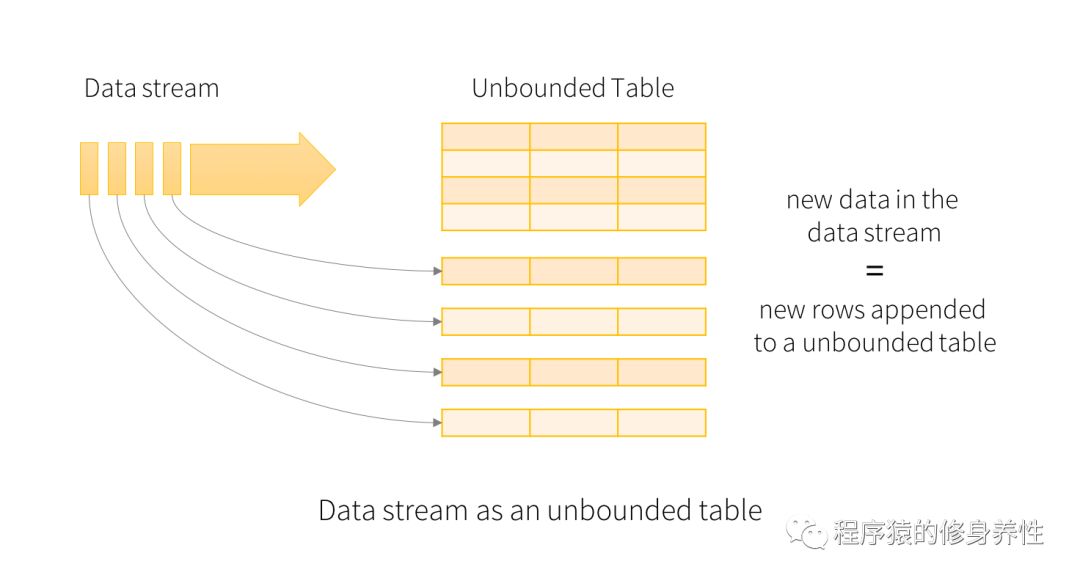
而Spark Structured Streaming相比Spark Streaming,具有什么优势呢?Spark Structured Streaming将数据源和计算结果都看作是无限大的表,数据源中每个批次的数据,经过计算,都添加到结果表中作为行,如下图所示:
B、Spark StructuredStreaming程序模型
Spark Structured Streaming的核心是将流式数据看成一张不断增加的数据库表,这种流式的数据处理模型类似于数据块处理模型,可以把静态数据库表的一些查询操作应用在流式计算中,Spark运行这些标准的SQL查询,从不断增加的无边界表中获取数据。
可以想象一下,把不断输入的流式数据加载为内存中一张没有边界的数据库表,每一条新来的数据都作为一行数据新添加到这张表中,这个过程如上图所示。每一个查询操作都会产生一个结果集——Result Table,每一个触发间隔(比如1秒钟),当新的数据添加到表中,都会最终更新Result Table,无论何时结果集发生了更新,都能将变化的结果写入一个外部的存储系统,如下图所示:
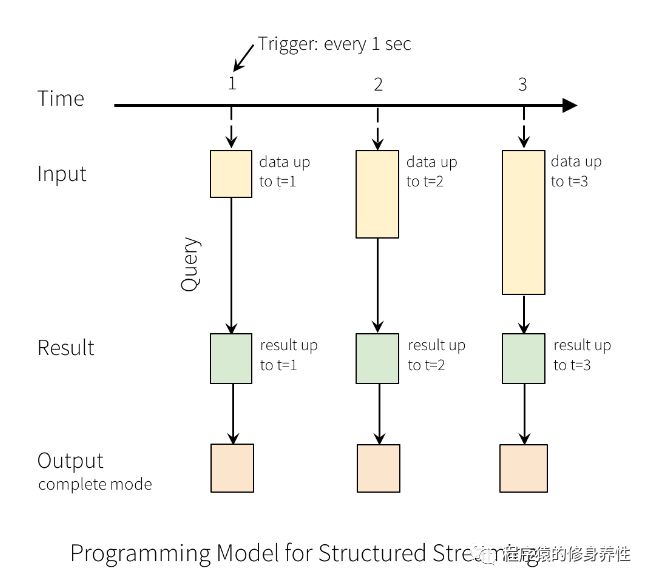
上图中的Output表示将要存储到外部系统,它可以定义不同的存储方式,一般有如下3种:
Complete Mode——整个更新的结果集都会写入到外部存储系统,整张表的写入操作将由外部存储系统的连接器Connector来处理;
Append Mode——当时间间隔触发时,只有在Result Table中新增加的数据行会被写入到外部存储系统。这种方式只适用于结果集中已经存在的内容不希望发生改变的情况,如果已经存在的数据会被更新,不适合应用此种方式;
Update Mode——当时间间隔触发时,只有在Result Table中被更新的数据才会被写入外部存储系统(在Spark2.0中尚未可用)。注意,同Complete Mode方式的不同之处是,不更新的结果集不会写入外部存储系统,如果查询不包含aggregation操作, 将会和append模式相同。
特别需要注意的是,上述的每种模式仅适用于特定类型的查询。
对于Spark StructuredStreaming就只介绍这么多,主要是起到抛砖引玉的作用,如果感兴趣,或者在后续的工作过程中需要用到这部分内容,再去进一步研究和学习。
参考文献:
——《CSDN博文》
——《潭州大数据课程课件》
