




以上四种分类,一致性由弱到强,同时实现难度也由易到难。
Exactly Once:保证所有数据只影响内部状态一次 End To End Exactly Once:保证所有数据对内部和外部状态都只影响一次。
对于 Flink 内部的一致性保证,依靠一致性检查点 checkpoint 来实现,通过 barrier 是否对齐来决定是 At Least Once 还是 Exactly Once(关于 checkpoint 可以查看《Flink | Checkpoint 机制详解》)。
而对于端到端的 Exactly Once 语义,实现原理如下:
Source端:可重设数据的读取位置。即source端会将数据的读取位置作为状态进行存储,当发生故障恢复时,依靠记录的读取位置,重新从数据源读取数据进行计算。 Flink内部:checkpoint机制 Sink端:要求从故障恢复时,数据不会重复地写入外部系统。具体实现方式有两种:
幂等写入:即多次写入的结果是一样的。这种一般针对NoSQL数据库,如 redis、HBase等,只要key-value一样,多次写入的结果是一样的。(注意这里只是结果一致,但不保证过程也是一致的) 事务写入:即事务中的操作要么全部成功,要么全部失败。实现思想是构建的事务对应 Flink 中的 checkpoint,只有等到 checkpoint 真正完成的时候,才把对应的结果写入到 sink 系统中(或者是执行真正的提交)。
事务写入的实现方式:两阶段提交(2PC)
两阶段提交 sink 即TwoPhaseCommitSinkFunction,是 Flink 从 1.4 版本开始引入的。
该 SinkFunction 提取并封装了两阶段提交协议中的公共逻辑,从此 Flink 可以搭配特定 Source 和 Sink 搭建精确一次处理语义( exactly-once semantics)。作为一个抽象类 TwoPhaseCommitSinkFunction 提供了一个抽象层供用户自行实现特定方法来支持 Exactly-Once 语义。
外部 sink 系统必须提供事务支持,或者 sink 任务必须能够模拟外部系统上的事务 在 checkpoint 的间隔期间里,必须能够开启一个事务并接受数据的写入 在收到 checkpoint 完成的通知之前,事务必须是预提交的状态。
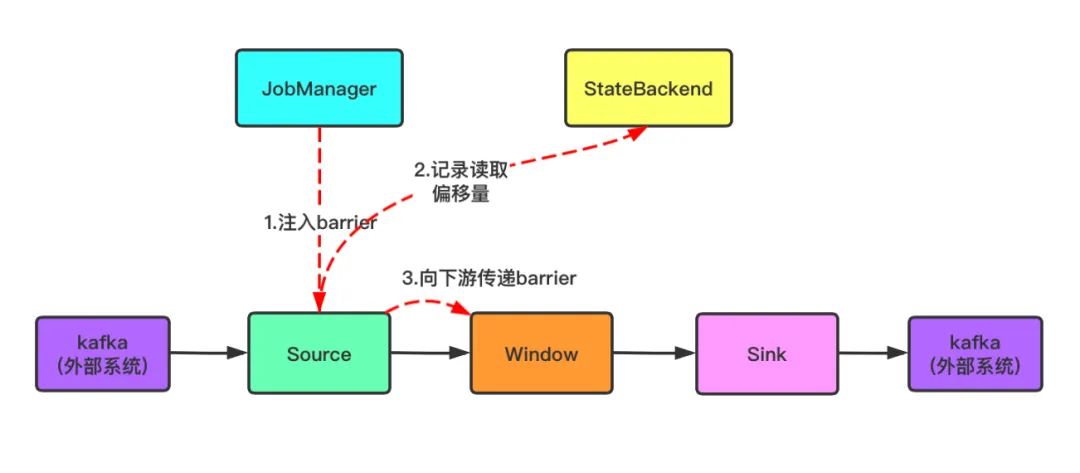
2.当 Window 这个 Operator 收到 Barrier 之后,对自己的状态进行保存,然后将Barrier 发送给 Sink。Sink收到后也对自己的状态进行保存,之后会进行一次预提交,并向 JobManager 报告预提交情况。
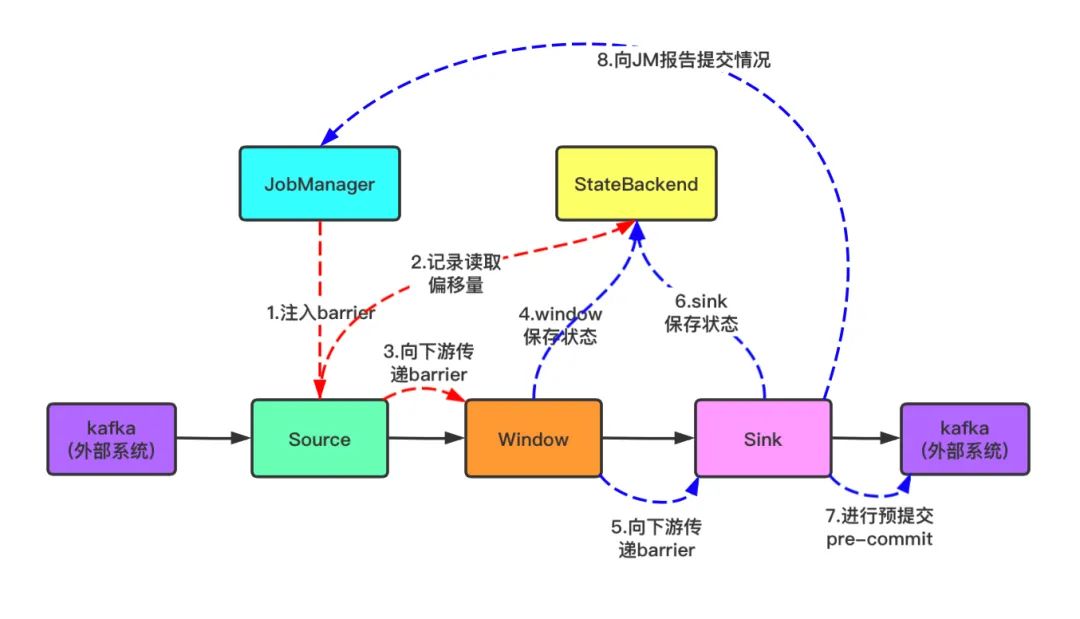
3.预提交成功后,JobManager 会通知每个Operator,这一轮 checkpoint 已经完成,这个时候,Kafka Sink会向 Kafka 进行真正的事务 Commit。
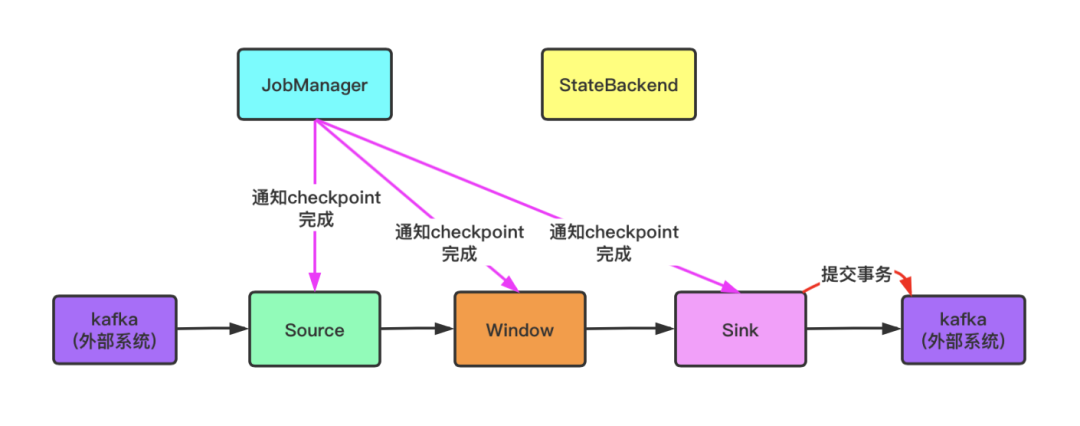
4.提交过程中如果失败有以下两种情况
Pre-commit失败,将会恢复到上一次完成 checkpoint 的状态
pre-commit完成,但正式 commit 过程中崩溃。那么当任务恢复后,Flink 会自动完成正式 commit
