1. 任务启动
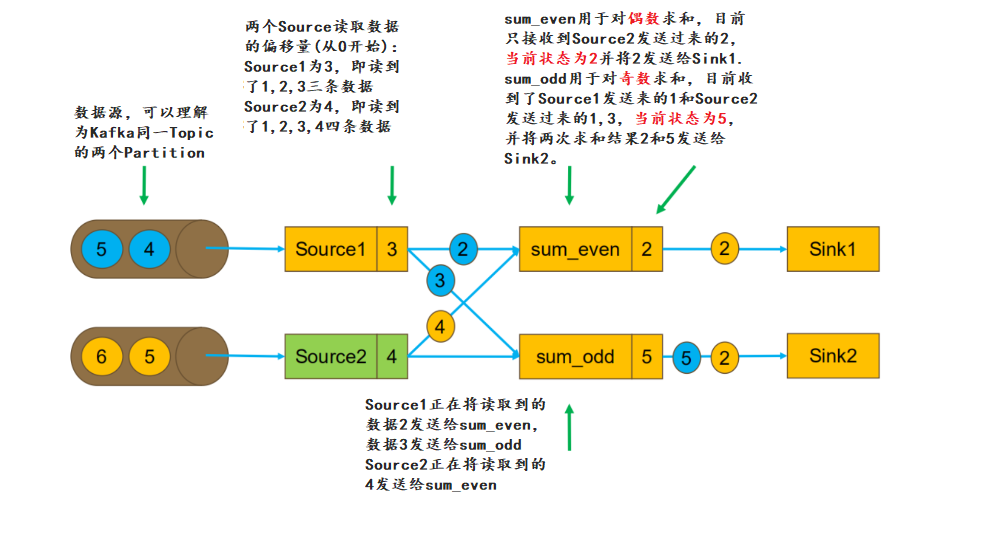
我们假设任务从 Kafka 的某个 Topic 中读取数据,该Topic 有 2 个 Partition,故任务的并行度为 2。根据读取到数据的奇偶性,将数据分发到两个 task 进行求和。
某一时刻,状态如下:
Source1的偏移量为 3,即读取到了 1,2,3 三条数据。数据1已经发送到 sum_odd。
Source2的偏移量为 4,即读取到了1,2,3,4 四条数据。数据1,3已经发送到sum_odd,数据2已经发送到sum_even
此时 sum_even 的状态为 2,sum_odd 的状态为 5
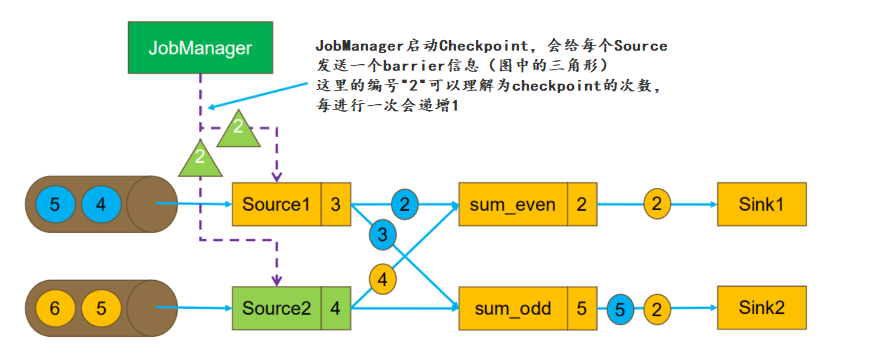
JobManager 根据 Checkpoint 间隔时间,启动 Checkpoint。此时会给每个 Source 发送一个 barrier 消息,消息中的数值表示 Checkpoint 的序号,每次启动新的 Checkpoint 该值都会递增。
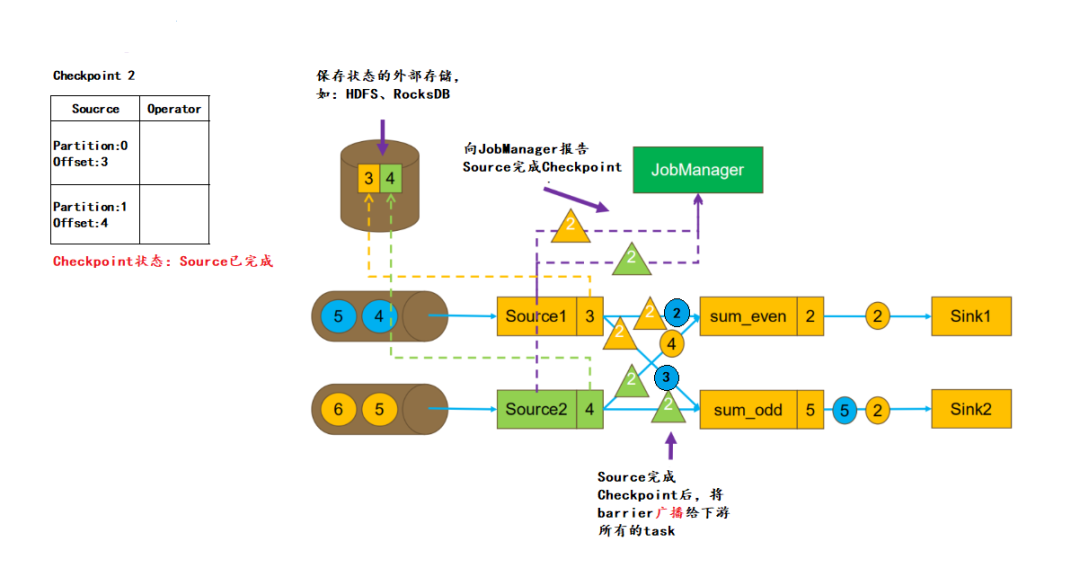
当Source接收到barrier消息,会将当前的状态(Partition、Offset)保存到 StateBackend,然后向 JobManager 报告Checkpoint 完成。之后Source会将barrier消息广播给下游的每一个 task:
4.task 接收 barrier
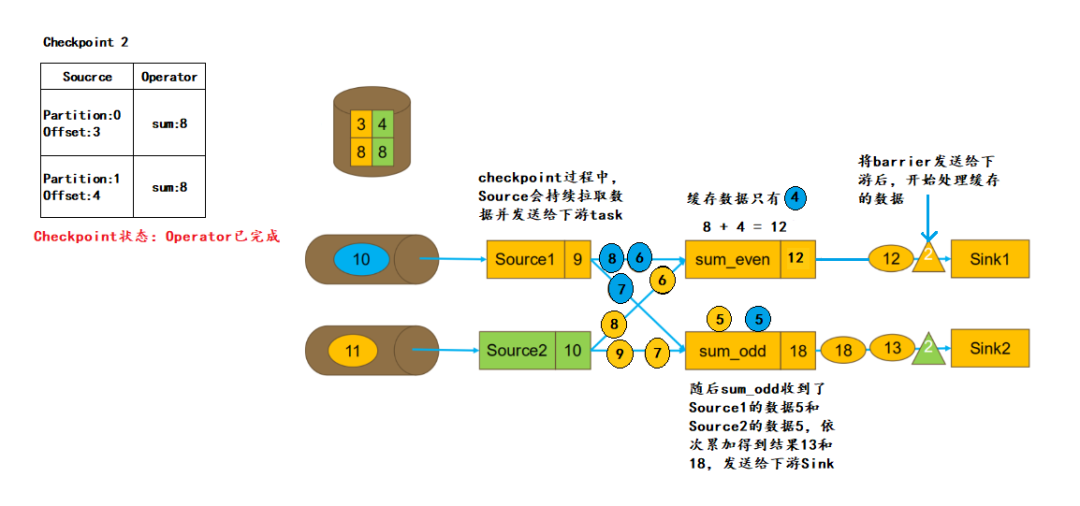
当task接收到某个上游(如这里的Source1)发送来的barrier,会将该上游barrier之前的数据继续进行处理,而barrier之后发送来的消息不会进行处理,会被缓存起来。
之前对barrier的理解比较模糊,直到看到了下面这幅图。barrier的作用和这里 "欢迎光临" 牌子的作用类似,用于区分流中的数据属于哪一个 Checkpoint:

(来源:checkpoint机制详解)
5.barrier对齐
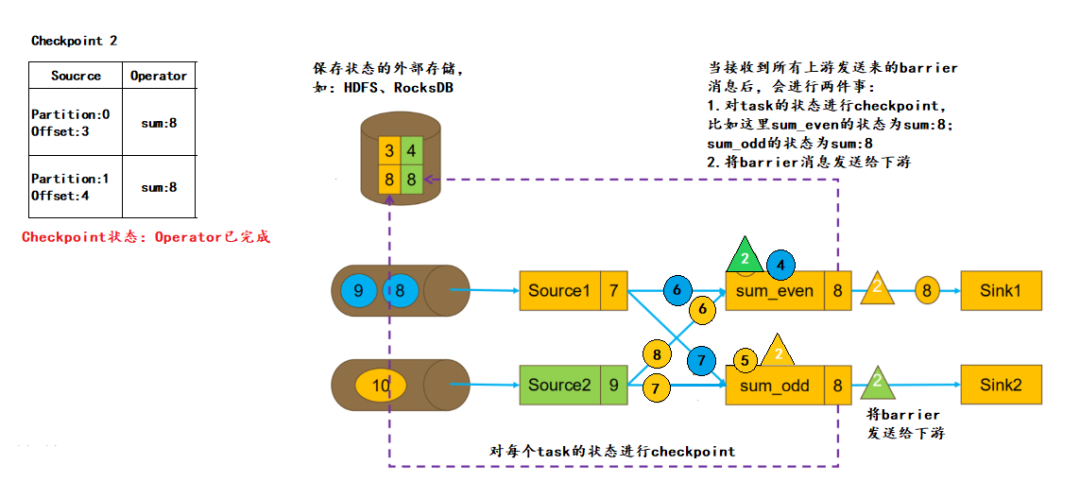
barrier是否对齐决定了程序实现的是 Exactly Once 还是 At Least Once:
如果不进行barrier对齐,那么这里 sum_even 在接收 Source2 的 barrier 之前,对于接收到 Source1的数据4,不会进行缓存,而是直接进行计算,sum_even 的状态改为12,当接收到 Source2 的barrier,会将 sum_even 的状态 sum=12 进行持久化。如果本次Checkpoint成功,在进行下次 Checkpoint 前任务崩溃,会根据本次Checkpoint进行恢复。此时状态如下:
Source1的 offset 为3,从数据4开始读。
Source2 的 offset 为4,从数据5开始读。
sum_even 的状态为 12(Souce1的数据2,数据4;Source2的数据2,数据4),后续接收Source1的数据4,数据6...;接收Source2的数据6,数据8...
从这里我们就可以看出,Source1的数据4被计算了两次。因此,Exactly Once语义下,必须进行barrier的对齐,而 At Least Once语义下 barrier 可以不对齐。
注意:barrier对齐只会发生在多对一的Operator(如 join)或者一对多的Operator(如 reparation/shuffle)。如果是一对一的Operator,如map、flatMap 或 filter 等,则没有对齐这个概念,都会实现Exactly Once语义,即使程序中配置了At Least Once 。
6.处理缓存数据
7.上报Checkpoint完成
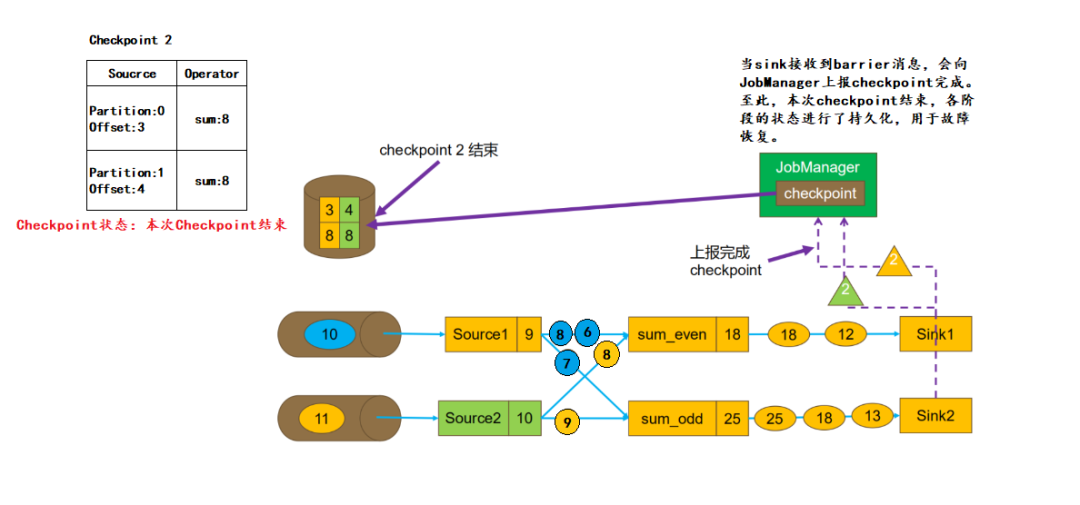
当sink收到barrier后,会向JobManager上报本次Checkpoint完成。至此,本次Checkpoint结束,各阶段的状态均进行了持久化,可以用于后续的故障恢复。