




感谢您抽出

.

.

来阅读本文
直接用 FlinkSQL 消费 kafka 中的数据,并经过一系列数据转换后 sink 到 kafka 另一个 Topic中,类似于如下语句:
INSERT INTO kafka_sink_table SELECT xxx FROM kafka_source_table
那么Flink 将数据分发到kafka中时,数据的分区分配规则是怎样的呢?
查看flink文档发现Flink SQL的kafka connector里有一个参数sink.partitioner,如下:
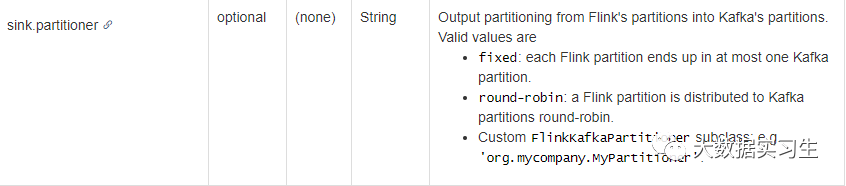
这个参数有3种有效值:
fixed:每个Flink分区最多分配到一个Kafka分区中。
round-robin:Flink分区轮询被分配到Kafka分区中。
自定义FlinkKafkaPartitioner子类:例如“org.mycompany.MyPartitioner”
后两个都比较好理解,我们这里探讨一下第一种 fixed 类型,通过查看 Flink 的源码我们找到了 fixed 类型分区分配的源代码:
package org.apache.flink.streaming.connectors.kafka.partitioner;import org.apache.flink.util.Preconditions;public class FlinkFixedPartitioner<T> extends FlinkKafkaPartitioner<T> {private int parallelInstanceId;public FlinkFixedPartitioner() {}public void open(int parallelInstanceId, int parallelInstances) {Preconditions.checkArgument(parallelInstanceId >= 0, "Id of this subtask cannot be negative.");Preconditions.checkArgument(parallelInstances > 0, "Number of subtasks must be larger than 0.");this.parallelInstanceId = parallelInstanceId;}public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {Preconditions.checkArgument(partitions != null && partitions.length > 0, "Partitions of the target topic is empty.");return partitions[this.parallelInstanceId % partitions.length];}}
从上段代码中可以看出:
当 sink.partitioner 参数选择 fixed 类型时,flink 是根据 sink 的 并行度的 id(即parallelInstanceId),和 kafka 中 Topic 的 partition 数量进行取余计算的,所以使用的时候就需要注意:
当 Sink 的并行度低于 Topic 的 partition 个数时,一个 sink task 写一个 partition,会导致部分 partition 完全没有数据。
当 topic 的 partition 扩容时,则需要重启作业,以便发现新的 partition。
所以在这个场景下,当我们分区分配原则选用 fixed 类型时就需要注意一下 Sink 的并行度与下游 kafka 中的 Topic 分区数,以免造成数据倾斜或者部分分区完全没有数据。
END


关注我们一起探索大数据
文章转载自大数据记事本,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
