




// 处理延时PRODUCE生产请求的PurgatoryvaldelayedProducePurgatory: DelayedOperationPurgatory[DelayedProduce],// 处理延时FETCH拉取请求的PurgatoryvaldelayedFetchPurgatory: DelayedOperationPurgatory[DelayedFetch],// 处理延时DELETE_RECORDS删除请求的PurgatoryvaldelayedDeleteRecordsPurgatory: DelayedOperationPurgatory[DelayedDeleteRecords],// 处理延时ELECT_LEADERS leader选举请求的PurgatoryvaldelayedElectPreferredLeaderPurgatory: DelayedOperationPurgatory[DelayedElectPreferredLeader],
《深入理解Kafka服务端之副本管理器介绍及Leader副本和Follower副本的切换》
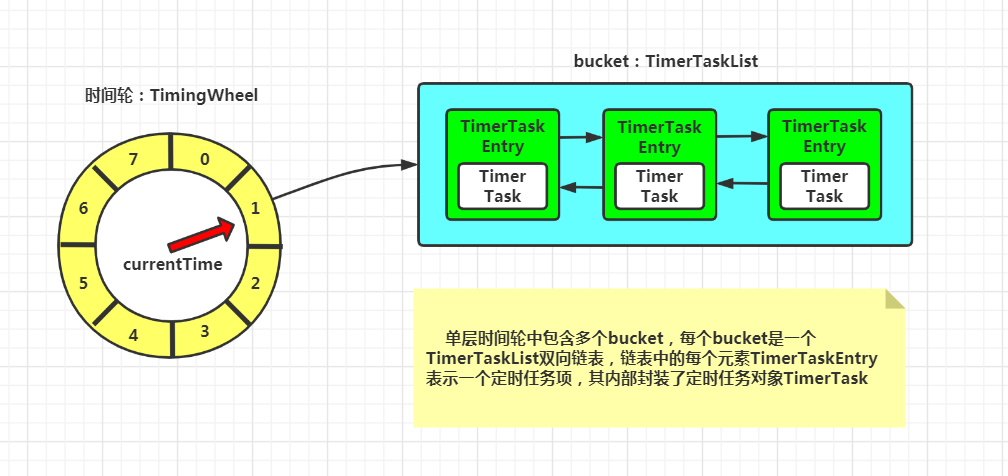
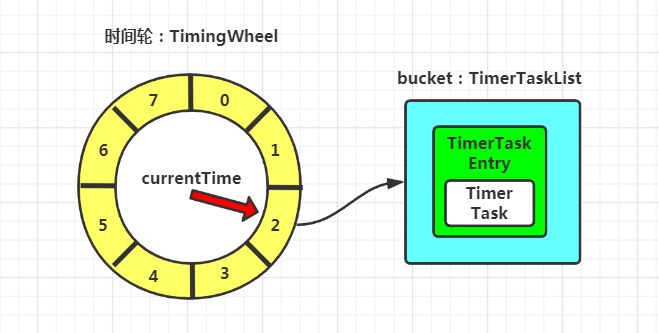
tickMs:时间轮的基本时间跨度,每个时间格代表一个时间跨度。 wheelSize:每层时间轮的时间格的个数。对于每层时间轮来说,这个值是固定的 interval:总体时间跨度。可以通过公式:tickMs * wheelSize 计算得出 currentTime:表盘指针,表示当前时间轮所处的时间。这里对时间做了调整,表示小于当前时间的最大时间跨度的整数倍。假设当前时间戳为 123 毫秒,时间轮每格跨度为 20 ms,那么 currentTimer 就是小于 123 且 20 的整数倍,即 120 ms。currentTime 将整个时间轮划分为到期部分和未到期部分,currentTime 当前执行的时间格也属于到期部分,表示刚好到期。需要处理当前时间格对应的 TimerTaskList 中的所有任务。
第一层的 tickMs 为 1 ms,所以第一层的 interval = 1 * 20 =20 ms; 第二层的 tickMs = 第一层的 interval,即 20 ms,所以第二层的 interval = 20 * 20 = 400 ms,以此类推。
时间轮的工作机制:

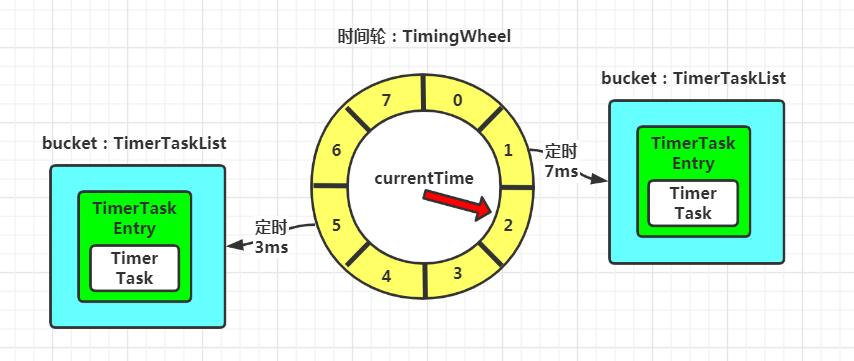
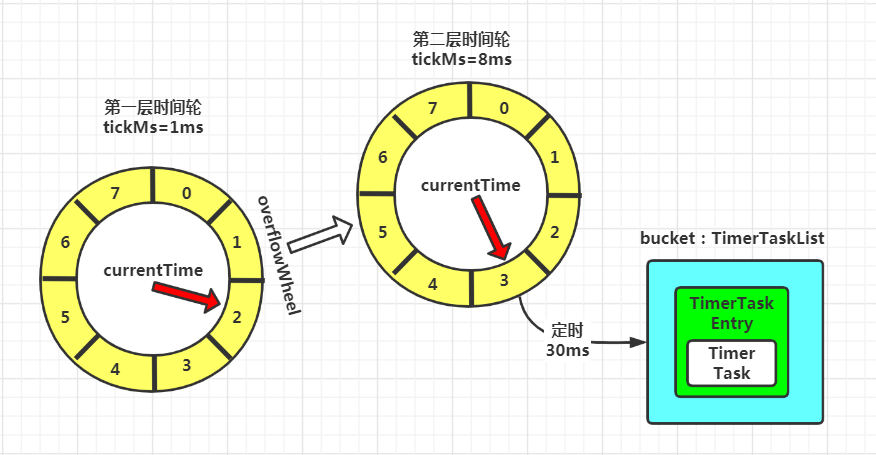
时间轮的降级:
三、源码分析
TimerTask:定时任务
TimerTaskEntry:封装了定时任务的定时任务项
TimerTaskList:定时任务列表,是一个双向链表,链表的每个元素为 TimerTaskEntry
TimingWheel:时间轮
1.TimerTask
trait TimerTask extends Runnable {// 延时时间。通常是request.timeout.ms参数值val delayMs: Long// 每个TimerTask实例关联一个TimerTaskEntry// 就是说每个定时任务需要知道它在哪个Bucket链表下的哪个链表元素上private[this] var timerTaskEntry: TimerTaskEntry = null// 取消定时任务,原理就是将关联的timerTaskEntry置空def cancel(): Unit = {synchronized {if (timerTaskEntry != null) timerTaskEntry.remove()timerTaskEntry = null}}// 关联timerTaskEntry,原理是给timerTaskEntry字段赋值private[timer] def setTimerTaskEntry(entry: TimerTaskEntry): Unit = {synchronized {if (timerTaskEntry != null && timerTaskEntry != entry)timerTaskEntry.remove()timerTaskEntry = entry}}// 获取关联的timerTaskEntry实例private[timer] def getTimerTaskEntry(): TimerTaskEntry = {timerTaskEntry}}
private[timer] class TimerTaskEntry(val timerTask: TimerTask, val expirationMs: Long) extends Ordered[TimerTaskEntry] {@volatile// 绑定的Bucket链表实例//Kafka 的延时请求可能会被其他线程从一个链表搬移到另一个链表中,因此,为了保证必要的内存可见性,代码声明 list 为 volatilevar list: TimerTaskList = nullvar next: TimerTaskEntry = nullvar prev: TimerTaskEntry = null// 关联给定的定时任务if (timerTask != null) timerTask.setTimerTaskEntry(this)// 关联定时任务是否已经被取消了def cancelled: Boolean = {timerTask.getTimerTaskEntry != this}// 从Bucket链表中移除自己def remove(): Unit = {var currentList = list//需要注意的是,置空这个动作是在 TimerTaskList 的 remove 中完成的,而这个方法可能会被其他线程同时调用,// 因此,下面的代码使用了 while 循环的方式来确保 TimerTaskEntry 的 list 字段确实被置空了。这样,Kafka 才能安全地认为此链表元素被成功移除。while (currentList != null) {//将自身节点从所属的双向列表上移除currentList.remove(this)currentList = list}}override def compare(that: TimerTaskEntry): Int = {this.expirationMs compare that.expirationMs}}
3. TimerTaskList
类定义:
private[timer] class TimerTaskList(taskCounter: AtomicInteger //用于标识当前这个链表中的总定时任务数) extends Delayed {private[this] val root = new TimerTaskEntry(null, -1)root.next = rootroot.prev = root//表示这个链表所在 Bucket 的过期时间戳private[this] val expiration = new AtomicLong(-1L)...}
taskCounter:用于标识当前这个链表中的总任务数
expiration:表示这个链表所在的时间格(bucket)的过期时间戳
主要方法:
① setExpiration:设置过期时间戳。这里使用了 AtomicLong 的 CAS 方法 getAndSet 原子性地设置了过期时间戳,之后将新过期时间戳和旧值进行比较,看看是否不同,然后返回结果,如果不同则返回 true。
def setExpiration(expirationMs: Long): Boolean = {//通过getAndSet的CAS操作原子性地设置了过期时间戳// 之后将新过期时间戳和旧值进行比较,看看是否不同,然后返回结果,不同返回true//这里为什么要比较新旧值是否不同呢?这是因为,目前 Kafka 使用一个 DelayQueue 统一管理所有的 Bucket,也就是 TimerTaskList 对象。// 随着时钟不断向前推进,原有 Bucket 会不断地过期,然后失效。当这些 Bucket 失效后,源码会重用这些 Bucket。// 重用的方式就是重新设置 Bucket 的过期时间,并把它们加回到 DelayQueue 中。// 这里进行比较的目的,就是用来判断这个 Bucket 是否要被插入到 DelayQueue。如果为true则插入到DelayQueue中expiration.getAndSet(expirationMs) != expirationMs}
def flush(f: (TimerTaskEntry) => Unit): Unit = {synchronized {// 找到链表第一个元素var head = root.next// 开始遍历链表while (head ne root)// 移除遍历到的链表元素remove(head)// 执行传入函数f的逻辑f(head)head = root.next}// 清空过期时间设置expiration.set(-1L)}
def add(timerTaskEntry: TimerTaskEntry): Unit = {var done = falsewhile (!done) {// 在添加之前尝试移除该定时任务,保证该任务没有在其他链表中timerTaskEntry.remove()synchronized {timerTaskEntry.synchronized {if (timerTaskEntry.list == null) {val tail = root.prevtimerTaskEntry.next = roottimerTaskEntry.prev = tailtimerTaskEntry.list = this// 把timerTaskEntry添加到链表末尾tail.next = timerTaskEntryroot.prev = timerTaskEntrytaskCounter.incrementAndGet()done = true}}}}}
def remove(timerTaskEntry: TimerTaskEntry): Unit = {synchronized {timerTaskEntry.synchronized {//如果该TimerTaskEntry的list对象就是当前TimerTaskList对象,说明该TimerTaskEntry在当前链表上if (timerTaskEntry.list eq this) {//将下一个节点的前置指针指向当前节点的前置指针timerTaskEntry.next.prev = timerTaskEntry.prev//将上一个节点的后置指针指向当前节点的后置指针timerTaskEntry.prev.next = timerTaskEntry.next//将给定TimerTaskEntry的前置、后置指针和所属TimerTaskList对象置空timerTaskEntry.next = nulltimerTaskEntry.prev = nulltimerTaskEntry.list = null//更新链表上节点个数taskCounter.decrementAndGet()}}}}
4. TimingWheel
类定义:
private[timer] class TimingWheel(tickMs: Long, //时间格跨度,类似于手表的例子中向前推进一格的时间,第一层时间轮的tickMs为1毫秒wheelSize: Int,//每一层时间轮上的 Bucket 数量。第 1 层的 Bucket 数量是 20startMs: Long,//时间轮对象被创建时的起始时间戳taskCounter: AtomicInteger,//这一层时间轮上的总定时任务数queue: DelayQueue[TimerTaskList]//将所有 Bucket 按照过期时间排序的延迟队列。// 随着时间不断向前推进,Kafka 需要依靠这个队列获取那些已过期的 Bucket,并清除它们) {//这层时间轮总时长,等于时间格跨度乘以 wheelSize。对于第一层时间轮来说,tickMs=1MS,wheelSize=20,所以interval=20MSprivate[this] val interval = tickMs * wheelSize//时间轮下的所有 Bucket 对象,也就是所有 TimerTaskList 对象private[this] val buckets = Array.tabulate[TimerTaskList](wheelSize) { _ => new TimerTaskList(taskCounter) }//当前时间戳,只是源码对它进行了一些微调整,将它设置成小于当前时间的最大时间格跨度的整数倍。// 例如:假设时间格跨度是 20 毫秒,当前时间戳是 123 毫秒,那么,currentTime 会被调整为 120 毫秒。private[this] var currentTime = startMs - (startMs % tickMs)//上层时间轮,按需创建@volatile private[this] var overflowWheel: TimingWheel = null
tickMs:每一个时间格的跨度。在 Kafka 中,第 1 层时间轮的 tickMs 被固定为 1 毫秒,也就是说,向前推进一格 Bucket 的时长是 1 毫秒。
wheelSize:每一层时间轮上的时间格 Bucket 的数量。第 1 层的 Bucket 数量是 20。
startMs:时间轮对象被创建时的起始时间戳。
taskCounter:这一层时间轮上的总定时任务数。
queue:将所有 Bucket 按照过期时间排序的延迟队列。随着时间不断向前推进,Kafka 需要依靠这个队列获取那些已过期的 Bucket,并清除它们。
interval:这层时间轮总时长,等于时间格跨度乘以 wheelSize。以第 1 层为例,interval 就是 20 毫秒。由于下一层时间轮的时间格跨度就是上一层的总时长,因此,第 2 层的时间格跨度就是 20 毫秒,总时长是 400 毫秒,以此类推。
buckets:时间轮下的所有 Bucket 对象,也就是所有 TimerTaskList 对象。
currentTime:当前时间戳,只是源码对它进行了一些微调整,将它设置成小于当前时间的最大时间格跨度的整数倍。举个例子,假设tickMs时长是 20 毫秒,当前时间戳是 123 毫秒,那么,currentTime 会被调整为 120 毫秒。
overflowWheel:上层时间轮对象,不一定存在,按需创建
① addOverflowWheel:用于创建上层时间轮对象
private[this] def addOverflowWheel(): Unit = {synchronized {if (overflowWheel == null) {//创建一个新的时间轮对象,其起始时间就是当前时间,时间格跨度就是当前时间轮的总时长,且每层时间轮的轮子数量wheelSize是一样的//例如:第一层时间轮的总时长为20MS,而第二层时间轮一个bucket的时间跨度就是20MS,总时长为400MSoverflowWheel = new TimingWheel(tickMs = interval,wheelSize = wheelSize,startMs = currentTime,taskCounter = taskCounter,queue)}}}
def add(timerTaskEntry: TimerTaskEntry): Boolean = {// 获取定时任务的过期时间戳val expiration = timerTaskEntry.expirationMs// 如果该任务已然被取消了,则无需添加,直接返回falseif (timerTaskEntry.cancelled) {false// 如果该任务超时时间已过期,返回false} else if (expiration < currentTime + tickMs) {false//如果该任务超时时间在本层时间轮覆盖时间范围内} else if (expiration < currentTime + interval) {//计算要被放入到哪个Bucket中val virtualId = expiration tickMs//获取对应的bucketval bucket = buckets((virtualId % wheelSize.toLong).toInt)//将元素添加到bucket对应的双向链表bucket.add(timerTaskEntry)// 设置Bucket过期时间// 如果该时间变更过,说明Bucket是新建或被重用,将其加回到DelayQueueif (bucket.setExpiration(virtualId * tickMs)) {//将bucket添加到queue中queue.offer(bucket)}true// 如果本层时间轮无法容纳该任务,交由上层时间轮处理} else {//如果上层时间轮对象为空,创建新的上层时间轮if (overflowWheel == null) addOverflowWheel()overflowWheel.add(timerTaskEntry)}}
该方法的逻辑如下:
第一步:获取定时任务的过期时间戳。所谓过期时间戳,就是这个定时任务过期时的时点。 第二步:看定时任务是否已被取消。如果已经被取消,则无需加入到时间轮中。如果没有被取消,就接着看这个定时任务是否已经过期。如果过期了,也不用加入到时间轮中。如果没有过期,再看这个定时任务的过期时间是否能够被涵盖在本层时间轮的时间范围内。如果可以,则进入到下一步。 第三步:计算目标 Bucket 序号,也就是这个定时任务需要被保存在哪个 TimerTaskList 中。确定了目标 Bucket 序号之后,代码会将该定时任务添加到这个 Bucket 下,同时更新这个 Bucket 的过期时间戳。 第四步:如果这个 Bucket 是首次插入定时任务,那么,还同时要将这个 Bucket 加入到 DelayQueue 中,方便 Kafka 轻松地获取那些已过期 Bucket,并删除它们。如果定时任务的过期时间无法被涵盖在本层时间轮中,那么,就按需创建上一层时间轮,然后在上一层时间轮上完整地执行刚刚所说的所有逻辑。
def advanceClock(timeMs: Long): Unit = {// 向前驱动到的时点要超过Bucket的时间范围,才是有意义的推进,否则什么都不做// 更新当前时间currentTime到下一个Bucket的起始时点/*** 假设当前时间轮为第二层时间轮,其tickMs=20MS* currentTime=40MS,timeMs=70MS,此时满足if条件,向前推进* 更新 currentTime = 70 - (70 % 20)= 70 - 10 = 60 MS,也就是 40 MS时间轮下一个轮子的起始时间点*/if (timeMs >= currentTime + tickMs) {currentTime = timeMs - (timeMs % tickMs)// 同时尝试为上一层时间轮做向前推进动作if (overflowWheel != null) overflowWheel.advanceClock(currentTime)}}
参数 timeMs 表示要把时钟向前推动到这个时点。向前驱动到的时点必须要超过 Bucket 的时间范围,才是有意义的推进,否则什么都不做,毕竟它还在 Bucket 时间范围内。
相反,一旦超过了 Bucket 覆盖的时间范围,代码就会更新当前时间 currentTime 到下一个 Bucket 的起始时点,同时递归地为上一层时间轮做向前推进动作。
推进时钟的动作是由 Kafka 后台专属的 Reaper 线程发起的。
参考:
极客时间《Kafka核心源码解读》
《深入理解Kafka核心设计与实践原理》
