




一、往期回顾
org.apache.spark.deploy.worker.Worker
启动 Worker 实际执行的就是伴生对象的 main 方法。
Worker 和 Master 都是 Endpoint 的子类,所以启动流程很相似,即创建 RpcEnv 对象,然后创建 Worker 对象并执行 onStart 方法开启其生命周期。
由于 Master 和 Worker 采用的是主从架构,所以 Worker 启动后最重要的事就是向 Master 注册,注册成功后定期发送心跳消息告诉 Master 自己活着。
二、Worker 启动流程图解
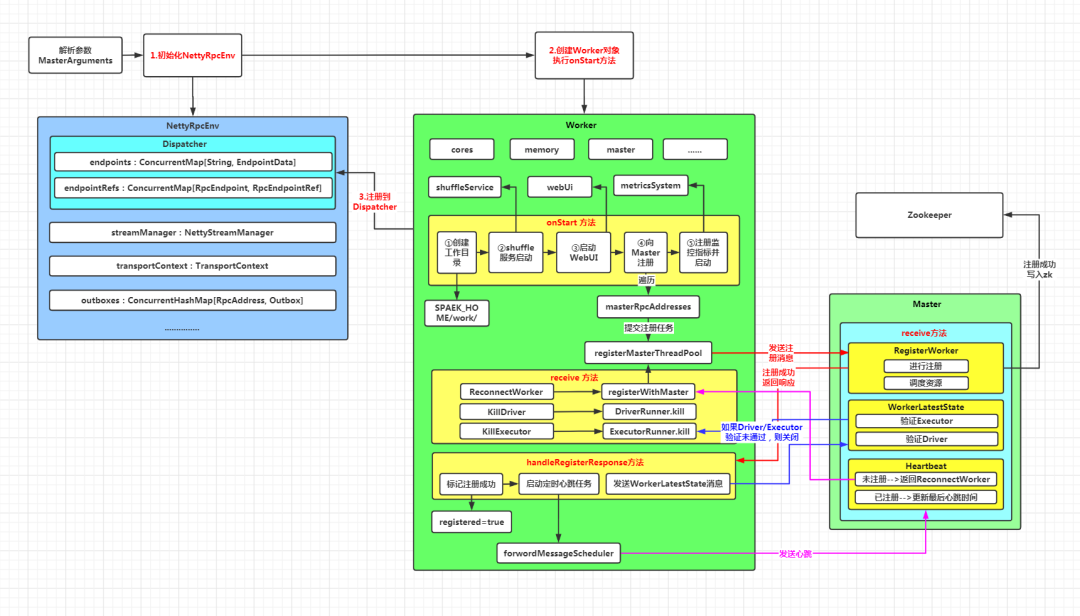
Worker 伴生对象的 main 方法:
def main(argStrings: Array[String]) {Thread.setDefaultUncaughtExceptionHandler(new SparkUncaughtExceptionHandler(exitOnUncaughtException = false))Utils.initDaemon(log)//第一步:解析参数//创建conf对象,读取spark默认的配置参数val conf = new SparkConf//解析程序运行参数,读取以spark. 开头的环境变量val args = new WorkerArguments(argStrings, conf)//TODO 第二步:启动 Worker 的 RPC 服务端val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,args.memory, args.masters, args.workDir, conf = conf)val externalShuffleServiceEnabled = conf.get(config.SHUFFLE_SERVICE_ENABLED)val sparkWorkerInstances = scala.sys.env.getOrElse("SPARK_WORKER_INSTANCES", "1").toIntrequire(externalShuffleServiceEnabled == false || sparkWorkerInstances <= 1,"Starting multiple workers on one host is failed because we may launch no more than one " +"external shuffle service on each host, please set spark.shuffle.service.enabled to " +"false or set SPARK_WORKER_INSTANCES to 1 to resolve the conflict.")rpcEnv.awaitTermination()}
该方法主要做了两件事:
解析参数:包括配置文件、程序运行参数及环境变量
启动 Worker 的 RPC 服务端
这里启动 Worker 的 RPC 服务端调用的是 startRpcEnvAndEndpoint 方法,逻辑如下:
def startRpcEnvAndEndpoint(host: String,port: Int,webUiPort: Int,cores: Int,memory: Int,masterUrls: Array[String],workDir: String,workerNumber: Option[Int] = None,conf: SparkConf = new SparkConf): RpcEnv = {val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")//初始化SecurityManagerval securityMgr = new SecurityManager(conf)//TODO 创建RpcEnv对象val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)//获取可能存在的多个 Master 的地址val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))//TODO 创建EndPoint对象并启动,用于网络通信// 做两件事:// 1.创建Worker对象,调用onStart 方法开启生命周期// 2.Worker 对象向 rpcEnv 中的 Dispatcher 对象注册rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,masterAddresses, ENDPOINT_NAME, workDir, conf, securityMgr))rpcEnv}
该方法主要包括三个步骤:
第一步:创建 RpcEnv 对象
第二步:创建 Worker 对象并调用 onStart 方法开启生命周期
第三步:将 Worker 对象注册到 RpcEnv 管理的 Dispatcher 对象中
其中,第一步和第三步在分析 Master 启动流程时已经进行了详细说明,这里不再赘述。重点看 Worker 对象的初始化及其 onStart 方法
注意:由于高可用的机制,一个 Worker 可能对应多个 Master,其中只有一个状态是 ALIVE,其它状态都是 STANDBY
Worker 定义:
private[deploy] class Worker(override val rpcEnv: RpcEnv,webUiPort: Int,cores: Int,//总核数memory: Int,//总的可用内存masterRpcAddresses: Array[RpcAddress],//Master地址,可能存在多个endpointName: String,workDirPath: String = null,//工作目录路径val conf: SparkConf,val securityMgr: SecurityManager,externalShuffleServiceSupplier: Supplier[ExternalShuffleService] = null)extends ThreadSafeRpcEndpoint with Logging {//设置主机名和端口号private val host = rpcEnv.address.hostprivate val port = rpcEnv.address.port//主机名和端口号合法性验证Utils.checkHost(host)assert (port > 0)//进行发送消息调度的线程池private val forwordMessageScheduler =ThreadUtils.newDaemonSingleThreadScheduledExecutor("worker-forward-message-scheduler")//也是一个线程池,完成清理工作的线程池。清理任务执行过程中的jar包,文件等,每隔30分钟执行一次private val cleanupThreadExecutor = ExecutionContext.fromExecutorService(ThreadUtils.newDaemonSingleThreadExecutor("worker-cleanup-thread"))//心跳间隔时间,用 60/4 = 15秒private val HEARTBEAT_MILLIS = conf.getLong("spark.worker.timeout", 60) * 1000 4private val INITIAL_REGISTRATION_RETRIES = 6private val TOTAL_REGISTRATION_RETRIES = INITIAL_REGISTRATION_RETRIES + 10private val FUZZ_MULTIPLIER_INTERVAL_LOWER_BOUND = 0.500private val REGISTRATION_RETRY_FUZZ_MULTIPLIER = {val randomNumberGenerator = new Random(UUID.randomUUID.getMostSignificantBits)randomNumberGenerator.nextDouble + FUZZ_MULTIPLIER_INTERVAL_LOWER_BOUND}private val INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS = (math.round(10 *REGISTRATION_RETRY_FUZZ_MULTIPLIER))private val PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS = (math.round(60* REGISTRATION_RETRY_FUZZ_MULTIPLIER))private val CLEANUP_ENABLED = conf.getBoolean("spark.worker.cleanup.enabled", false)//cleanup定时任务的周期:30分钟private val CLEANUP_INTERVAL_MILLIS =conf.getLong("spark.worker.cleanup.interval", 60 * 30) * 1000//应用文件夹/数据的ttl,ttl过期时间为7天,过期后将被清理private val APP_DATA_RETENTION_SECONDS =conf.getLong("spark.worker.cleanup.appDataTtl", 7 * 24 * 3600)//是否清理 executor 存在的非 shuffer 产生的文件,默认为trueprivate val CLEANUP_NON_SHUFFLE_FILES_ENABLED =conf.getBoolean("spark.storage.cleanupFilesAfterExecutorExit", true)private val testing: Boolean = sys.props.contains("spark.testing")//Master节点的RpcEndpointRef代理对象private var master: Option[RpcEndpointRef] = Noneprivate val preferConfiguredMasterAddress =conf.getBoolean("spark.worker.preferConfiguredMasterAddress", false)private var masterAddressToConnect: Option[RpcAddress] = Noneprivate var activeMasterUrl: String = ""private[worker] var activeMasterWebUiUrl : String = ""private var workerWebUiUrl: String = ""private val workerUri = RpcEndpointAddress(rpcEnv.address, endpointName).toString//标识该worker节点是否注册成功private var registered = falseprivate var connected = false//生成workerIDprivate val workerId = generateWorkerId()private val sparkHome =if (testing) {assert(sys.props.contains("spark.test.home"), "spark.test.home is not set!")new File(sys.props("spark.test.home"))} else {new File(sys.env.get("SPARK_HOME").getOrElse("."))}//工作目录var workDir: File = null//当前Worker上完成的Executor的集合val finishedExecutors = new LinkedHashMap[String, ExecutorRunner]//当前Worker上的Driver集合val drivers = new HashMap[String, DriverRunner]//当前Worker上executor集合val executors = new HashMap[String, ExecutorRunner]//当前Worker上完成的Driver集合val finishedDrivers = new LinkedHashMap[String, DriverRunner]//当前Worker上Application的工作文件夹val appDirectories = new HashMap[String, Seq[String]]//当前Worker上已完成的Applicationval finishedApps = new HashSet[String]val retainedExecutors = conf.getInt("spark.worker.ui.retainedExecutors",WorkerWebUI.DEFAULT_RETAINED_EXECUTORS)val retainedDrivers = conf.getInt("spark.worker.ui.retainedDrivers",WorkerWebUI.DEFAULT_RETAINED_DRIVERS)//TODO 启动shuffle服务private val shuffleService = if (externalShuffleServiceSupplier != null) {externalShuffleServiceSupplier.get()} else {//默认实现new ExternalShuffleService(conf, securityMgr)}private val publicAddress = {val envVar = conf.getenv("SPARK_PUBLIC_DNS")if (envVar != null) envVar else host}private var webUi: WorkerWebUI = nullprivate var connectionAttemptCount = 0//性能监控的组件private val metricsSystem = MetricsSystem.createMetricsSystem("worker", conf, securityMgr)private val workerSource = new WorkerSource(this)val reverseProxy = conf.getBoolean("spark.ui.reverseProxy", false)private var registerMasterFutures: Array[JFuture[_]] = nullprivate var registrationRetryTimer: Option[JScheduledFuture[_]] = None//向Master注册的线程池,由于向Master注册是同步阻塞的,所以线程个数和Master的个数是一致的private val registerMasterThreadPool = ThreadUtils.newDaemonCachedThreadPool("worker-register-master-threadpool",masterRpcAddresses.length // Make sure we can register with all masters at the same time)//用于记录资源//已使用cpu个数var coresUsed = 0//已使用内存大小var memoryUsed = 0...}
可以看到,Worker 中定义了多个属性。重点看以下几个:
cores:cup总个数
memory:可用内存
masterRpcAddresses:可能存在的多个 Master 地址
workDirPath:工作目录路径
forwordMessageScheduler:进行发送消息调度的线程池
cleanupThreadExecutor:完成清理工作的线程池。清理任务执行过程中上传的 jar 包、文件等,清理周期由参数 spark.worker.cleanup.interval 设置,默认每隔 30 分钟清理一次
HEARTBEAT_MILLIS:心跳的间隔时间。计算逻辑是 spark.worker.timeout 4,即 60 4 = 15 秒
APP_DATA_RETENTION_SECONDS:应用文件夹/数据的过期时间。由参数 spark.worker.cleanup.appDataTtl 配置,默认为 7 天
master:ALIVE 状态的 Master 的代理对象
registered:标识该 Worker 是否注册成功
drivers:当前 Worker 上的 Driver 集合
executors:当前 Worker 上的 Executor 集合
shuffleService:shuffle 服务对象。后面会进行单独分析
coreUsed:已使用的 CPU 个数
memoryUsed:已使用的内存大小
由于 Worker 是真正执行任务的,所以它会记录自身的可用资源,以便向 Master 报告
override def onStart() {//验证该Worker未注册assert(!registered)logInfo("Starting Spark worker %s:%d with %d cores, %s RAM".format(host, port, cores, Utils.megabytesToString(memory)))logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")logInfo("Spark home: " + sparkHome)//TODO 第一步:创建当前Worker的工作目录createWorkDir()//TODO 第二步:启动shuffle服务startExternalShuffleService()//TODO 第三步:启动WebUI,绑定端口webUi = new WorkerWebUI(this, workDir, webUiPort)webUi.bind()workerWebUiUrl = s"http://$publicAddress:${webUi.boundPort}"//TODO 第四步:向Master注册registerWithMaster()//TODO 第五步:注册指标监控系统并启动metricsSystem.registerSource(workerSource)metricsSystem.start()metricsSystem.getServletHandlers.foreach(webUi.attachHandler)}
onStart 方法主要分为五步:
第一步:创建当前 Worker 的工作目录。也就是在 SPARK_HOME 目录下创建一个 work 目录
第二步:启动 shuffle 服务
第三步:启动 WebUI,绑定端口
第四步:向 Master 注册
第五步:注册指标监控系统并启动
这里重点分析如何向 Master 进行注册,至于如何启动 shuffle 服务,后面单独分析
向 Master 注册调用了 registerWithMaster 方法:
private def registerWithMaster() {registrationRetryTimer match {case None =>//如果还未注册registered = false//TODO 开启注册,多次重试直到注册成功registerMasterFutures = tryRegisterAllMasters()connectionAttemptCount = 0//如果没有注册成功,就启动一个定时任务,每隔一段时间([5,15]之间的随机整数)重新注册一次registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate(new Runnable {override def run(): Unit = Utils.tryLogNonFatalError {Option(self).foreach(_.send(ReregisterWithMaster))}},//[5,15]之间的随机整数INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,TimeUnit.SECONDS))case Some(_) =>logInfo("Not spawning another attempt to register with the master, since there is an" +" attempt scheduled already.")}}
如果从未注册过,则启动注册;
如果没有注册成功,则启动一个定时任务,每隔一段时间给自己发送一个 ReregisterWithMaster 类型的消息
启动注册:tryRegisterAllMasters
private def tryRegisterAllMasters(): Array[JFuture[_]] = {//向每个Master提交注册信息masterRpcAddresses.map { masterAddress =>//往线程池中提交了一个注册的任务registerMasterThreadPool.submit(new Runnable {override def run(): Unit = {try {logInfo("Connecting to master " + masterAddress + "...")//获取到MasterEndPointRef代理对象val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)//发送RegisterWorker注册消息给MastersendRegisterMessageToMaster(masterEndpoint)} catch {case ie: InterruptedException => // Cancelledcase NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)}}})}}
该方法会遍历所有 Master 地址,给每个 Master 往 registerMasterThreadPool 线程池中提交一个任务,任务的功能就是向 Master 发送 RegisterWorker 注册消息
Master 接收注册消息的处理逻辑如下:
case RegisterWorker(id, workerHost, workerPort, workerRef, cores, memory, workerWebUiUrl, masterAddress) =>logInfo("Registering worker %s:%d with %d cores, %s RAM".format(workerHost, workerPort, cores, Utils.megabytesToString(memory)))//如果是STANDBY状态的Masterif (state == RecoveryState.STANDBY) {//什么都不做,给Worker返回一个StandByworkerRef.send(MasterInStandby)//判断该Worker是否注册过} else if (idToWorker.contains(id)) {//如果注册过了,就返回一个RegisterWorkerFailed消息workerRef.send(RegisterWorkerFailed("Duplicate worker ID"))//如果没有注册过,则完成注册} else {//初始化一个WorkerInfo对象,存储了Worker的信息val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,workerRef, workerWebUiUrl)//执行Worker的注册,将Worker信息放入各种数据结构中//如果注册成功if (registerWorker(worker)) {//把Worker信息写到zk集群persistenceEngine.addWorker(worker)//给Worker发送RegisteredWorker注册成功的消息workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress))//Worker加入工作,当Worker加入时,可用资源必定增加,那么就将等待执行的Driver,Executor等启动起来执行任务schedule()} else {val workerAddress = worker.endpoint.addresslogWarning("Worker registration failed. Attempted to re-register worker at same " +"address: " + workerAddress)workerRef.send(RegisterWorkerFailed("Attempted to re-register worker at same address: "+ workerAddress))}}
如果 Master 的状态为 STANDBY,则给 Worker 返回一个 MasterInStandby 消息,Worker 接收该类型消息什么都不会做 如果 Master 状态为 ALIVE,但该 Worker 已经注册过,就返回一个 RegisterWorkerFailed 类型的消息,Worker 接收该类型消息后,如果 Worker 已经注册过,则什么都不做,如果没有注册过则记录错误日志 如果 Master 状态为 ALIVE,且该 Worker 没有注册过,则完成 Worker 注册:
第一步:将 Worker 信息封装成一个 WorkerInfo 对象 第二步:进行 Worker 注册,即将 Worker 信息保存到 Master 的各种数据结构中 第三步:如果注册成功,则将 Worker 信息写到 zk 集群 第四步:给 Worker 发送 RegisteredWorker 类型的消息 第五步:调度资源,让等待资源的 Driver 和 Executor 执行任务
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {msg match {//接收到注册成功的消息case RegisteredWorker(masterRef, masterWebUiUrl, masterAddress) =>if (preferConfiguredMasterAddress) {logInfo("Successfully registered with master " + masterAddress.toSparkURL)} else {logInfo("Successfully registered with master " + masterRef.address.toSparkURL)}//标记注册成功registered = true//Worker会同时给两个Master发送注册信息,如果Master节点发生变更,那么这里就会更新Master的信息changeMaster(masterRef, masterWebUiUrl, masterAddress)//Worker注册成功后,启动定时任务,每隔15秒执行一次,给自己发送一个SendHeartbeat消息forwordMessageScheduler.scheduleAtFixedRate(new Runnable {override def run(): Unit = Utils.tryLogNonFatalError {self.send(SendHeartbeat)}}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)//如果配置了定期清理工作目录,则启动定时任务,延时30分钟后,每隔30分钟执行一次if (CLEANUP_ENABLED) {logInfo(s"Worker cleanup enabled; old application directories will be deleted in: $workDir")forwordMessageScheduler.scheduleAtFixedRate(new Runnable {override def run(): Unit = Utils.tryLogNonFatalError {self.send(WorkDirCleanup)}}, CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)}val execs = executors.values.map { e =>new ExecutorDescription(e.appId, e.execId, e.cores, e.state)}//给Master发送WorkerLatestState类型的消息masterRef.send(WorkerLatestState(workerId, execs.toList, drivers.keys.toSeq))...}}
如果接收到注册成功的消息,会执行以下步骤:
第一步:更新 Worker 的 registered 变量,标记注册成功
第二步:更新 Master 信息。Worker会同时给两个Master发送注册信息,如果Master节点发生变更,那么这里就会更新Master的信息
第三步:启动心跳定时任务,每隔 15 秒给自己发送一个 SendHeartbeat 消息,自身接收到该消息,会给 Master 发送 Heartbeat 类型的消息
第四步:如果开启了定期清理工作目录,则启动定时任务,延时30分钟后,每隔30分钟执行一次清理任务
第五步:将所有 Executor 封装成 ExecutorDescription 对象,然后向 Master 发送 WorkerLatestState 类型的消息
上面向 Master 发送了两种类型的消息:Heartbeat 和 WorkerLatestState ,下面看 Master 是如何处理的
Heartbeat :
case Heartbeat(workerId, worker) =>//根据WorkerID获取Worker信息idToWorker.get(workerId) match {//如果获取到了则更新最后一次心跳的时间case Some(workerInfo) =>workerInfo.lastHeartbeat = System.currentTimeMillis()//如果没有获取到,说明还没有注册 则给Worker发送ReconnectWorker消息case None =>if (workers.map(_.id).contains(workerId)) {logWarning(s"Got heartbeat from unregistered worker $workerId." +" Asking it to re-register.")worker.send(ReconnectWorker(masterUrl))} else {logWarning(s"Got heartbeat from unregistered worker $workerId." +" This worker was never registered, so ignoring the heartbeat.")}}
如果是 Heartbeat 类型的消息,Master 会判断该 Worker 是否注册:
如果注册了,会更新最后一个心跳的时间
如果没有注册,会给 Worker 返回一个 ReconnectWorker 类型的消息。Worker 处理该消息的逻辑就是调用上面的 registerWithMaster 方法进行注册
WorkerLatestState :
case WorkerLatestState(workerId, executors, driverIds) =>//根据workerId获取Worker信息idToWorker.get(workerId) match {//如果获取到了指定的 Worker 信息case Some(worker) =>//遍历所有的Executor信息,看Master保存的Worker信息中是否包含该Executor信息,// 如果不包含,则给Worker发送KillExecutor消息,让其关闭该Executorfor (exec <- executors) {val executorMatches = worker.executors.exists {case (_, e) => e.application.id == exec.appId && e.id == exec.execId}if (!executorMatches) {// master doesn't recognize this executor. So just tell worker to kill it.worker.endpoint.send(KillExecutor(masterUrl, exec.appId, exec.execId))}}//遍历所有的Driver信息,看Master保存的Worker信息中是否包含该Driver信息,// 如果不包含,则给Worker发送KillDriver消息,让其关闭该Driverfor (driverId <- driverIds) {val driverMatches = worker.drivers.exists { case (id, _) => id == driverId }if (!driverMatches) {// master doesn't recognize this driver. So just tell worker to kill it.worker.endpoint.send(KillDriver(driverId))}}//如果没有获取到则记录日志case None =>logWarning("Worker state from unknown worker: " + workerId)}
该分支的作用是检查当前 Worker 上的 Executor 和 Driver 是否和 Master 端记录的一致,如果不一致则关闭 Executor 和 Driver
注意:从这里也可以看出,在 Master 端维护的 WorkerInfo 信息中,包含了该 Worker 上运行的所有 Executor 和 Driver 信息
最后看一下如果 Worker 注册不成功,如何重新注册。调用的是
Worker.reregisterWithMaster 方法
private def reregisterWithMaster(): Unit = {Utils.tryOrExit {//更新尝试注册的次数connectionAttemptCount += 1//如果已经注册成功,取消最后一次重新注册的操作if (registered) {cancelLastRegistrationRetry()//如果重试次数小于阈值(默认16)} else if (connectionAttemptCount <= TOTAL_REGISTRATION_RETRIES) {logInfo(s"Retrying connection to master (attempt # $connectionAttemptCount)")master match {case Some(masterRef) =>//如果Worker中保存了Master信息,但是注册失败了,说明失去了和Master的连接,所以代理对象不可用,需要重新创建代理对象if (registerMasterFutures != null) {registerMasterFutures.foreach(_.cancel(true))}//重新获取Master代理对象val masterAddress =if (preferConfiguredMasterAddress) masterAddressToConnect.get else masterRef.address//重新向线程池添加注册Worker的任务registerMasterFutures = Array(registerMasterThreadPool.submit(new Runnable {override def run(): Unit = {try {logInfo("Connecting to master " + masterAddress + "...")val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)//给Master发送RegisterWorker消息sendRegisterMessageToMaster(masterEndpoint)} catch {case ie: InterruptedException => // Cancelledcase NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)}}}))case None =>if (registerMasterFutures != null) {registerMasterFutures.foreach(_.cancel(true))}// We are retrying the initial registration//尝试进行注册registerMasterFutures = tryRegisterAllMasters()}// We have exceeded the initial registration retry threshold// All retries from now on should use a higher interval//如果达到了初始的重试次数阈值(默认为6),那么应该加大重试间隔if (connectionAttemptCount == INITIAL_REGISTRATION_RETRIES) {//取消注册重试计时registrationRetryTimer.foreach(_.cancel(true))//重新设置注册的重试计时,重试间隔增大到[30,90]之间的一个随机数,假设为m//那么延时m秒后,每隔m秒重试一次registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate(new Runnable {override def run(): Unit = Utils.tryLogNonFatalError {self.send(ReregisterWithMaster)}}, PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,TimeUnit.SECONDS))}} else {//如果超过重试次数阈值,则记录错误日志logError("All masters are unresponsive! Giving up.")System.exit(1)}}}
该方法的逻辑是:
第一步:更新重试注册的计数器
第二步:如果已经注册成功了,那么取消最后一次的重新注册操作
第三步:如果超过了注册重试的总次数(默认16次),则记录错误日志
第四步:如果没有超过注册重试的总次数,判断是否有 Master 代理信息,如果没有,且没有注册失败的信息,则尝试进行初始注册
第五步:如果有 Master 代理信息,但是注册失败了,说明失去了和 Master 的连接,那么需要重新获取 Master 的代理对象。然后使用重新获取的代理对象,向 Master 发送注册消息(这里是将注册的任务重新添加到管理注册线程的线程池里面)
第六步:如果注册重试的次数达到了初始的重试次数阈值(默认6次),则重新设置注册的重试计时,增大重试的间隔时间,这个时间是 [30,90] 之前的一个随机整数,假设为m,单位是秒。然后启动定时任务,在延时 m 秒之后,每个 m 秒重新注册一次,直到达到总的重试次数。
