




消费者组内消费者数量发生变化,包括: 有新消费者加入 有消费者宕机下线。包括真正宕机,或者长时间GC、网络延迟导致消费者未在超时时间内向 GroupCoordinator 发送心跳,也会被认为下线 有消费者主动退出消费者组(发送 LeaveGroupRequest 请求) 比如客户端调用了 unsubscrible() 方法取消对某些主题的订阅 消费者组对应的 GroupCoordinator 节点发生了变化 消费者组订阅的主题发生变化(增减)或者主题分区数量发生了变化
寻找管理该消费者组的 GroupCoordinator 所在节点 向消费者组加入新成员 向所有消费者组成员同步消费分区分配方案 消费者向 GroupCoordinator 发送心跳
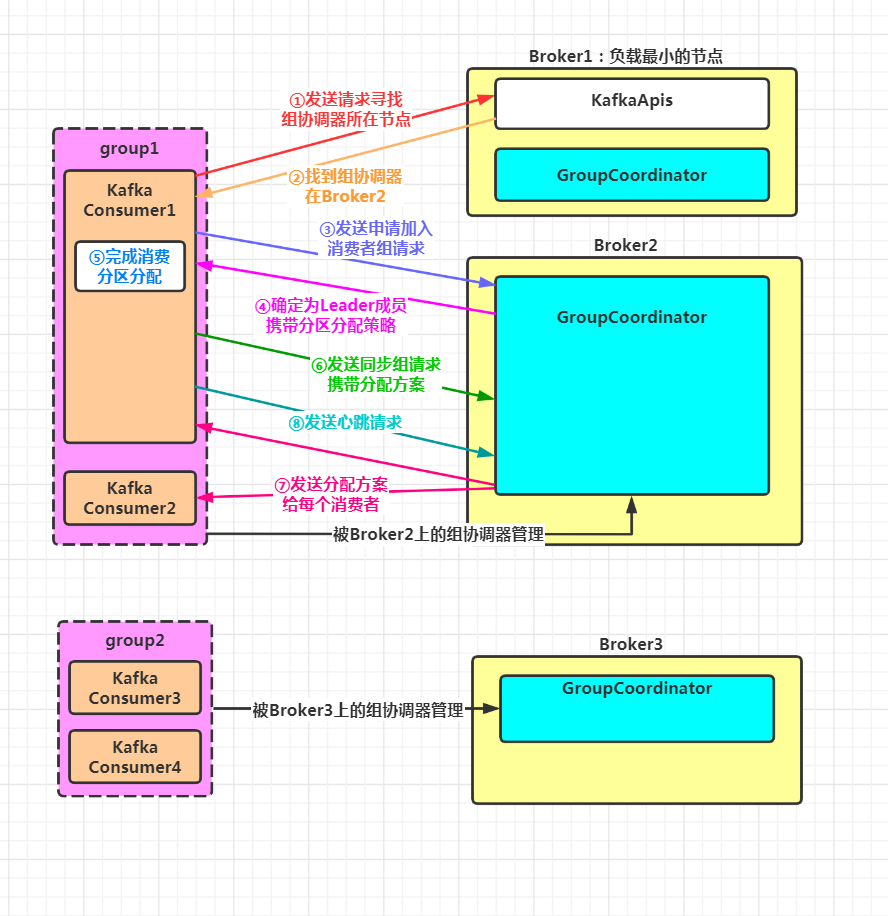
假设 KafkaConsumer1 为待加入的消费者,其属于消费者组 group1
Rebalance 整体流程如下图:
三、源码分析
def handleFindCoordinatorRequest(request: RequestChannel.Request) {//提取请求体,获取FindCoordinatorRequest 对象val findCoordinatorRequest = request.body[FindCoordinatorRequest]//验证请求的合法性...//如果请求合法else {// get metadata (and create the topic if necessary)val (partition, topicMetadata) = CoordinatorType.forId(findCoordinatorRequest.data.keyType) match {//如果是查找GroupCoordinator的请求case CoordinatorType.GROUP =>//根据消费者组名称,获取消费者所在组的注册消息在__consumer_offsets主题中的分区号val partition = groupCoordinator.partitionFor(findCoordinatorRequest.data.key)//获取__consumer_offsets主题元数据,如果还未创建该主题,则创建val metadata = getOrCreateInternalTopic(GROUP_METADATA_TOPIC_NAME, request.context.listenerName)(partition, metadata)//如果是查找事务协调器的请求case CoordinatorType.TRANSACTION =>...case _ =>throw new InvalidRequestException("Unknown coordinator type in FindCoordinator request")}//创建响应对象def createResponse(requestThrottleMs: Int): AbstractResponse = {def createFindCoordinatorResponse(error: Errors, node: Node): FindCoordinatorResponse = {new FindCoordinatorResponse(new FindCoordinatorResponseData().setErrorCode(error.code).setErrorMessage(error.message)//GroupCoordinator所在节点id.setNodeId(node.id)//GroupCoordinator所在节点主机名.setHost(node.host)//GroupCoordinator所在节点端口号.setPort(node.port).setThrottleTimeMs(requestThrottleMs))}val responseBody = if (topicMetadata.error != Errors.NONE) {createFindCoordinatorResponse(Errors.COORDINATOR_NOT_AVAILABLE, Node.noNode)} else {val coordinatorEndpoint = topicMetadata.partitionMetadata.asScala.find(_.partition == partition).map(_.leader).flatMap(p => Option(p))coordinatorEndpoint match {case Some(endpoint) if !endpoint.isEmpty =>createFindCoordinatorResponse(Errors.NONE, endpoint)case _ =>createFindCoordinatorResponse(Errors.COORDINATOR_NOT_AVAILABLE, Node.noNode)}}trace("Sending FindCoordinator response %s for correlation id %d to client %s.".format(responseBody, request.header.correlationId, request.header.clientId))responseBody}//向请求发送方返回响应,响应中包含对应的请求以及查找到的GroupCoordinator节点信息sendResponseMaybeThrottle(request, createResponse)}}
该方法的逻辑是:
第一步:获取请求体并验证请求的合法性
第二步:如果请求合法,判断请求中要查找的协调器类型,这里只看查找 GroupCoordinator 的分支
第三步:根据请求中的消费者组的名称,获取其注册消息所在 __consumer_offsets 主题中的分区号;然后获取位移主题的元数据信息,如果该主题还未创建,则创建该主题
第四步:根据第三步找到的分区号,确定该分区 Leader 副本所在的节点,该节点就是当前消费者组的 GroupCoordinator 所在节点。
第五步:封装响应,里面包含了接收到的请求以及 GroupCoordinator 所在节点的 id,主机名和端口号等信息。
其中,最重要的就是:根据请求中的消费者组名称,获取其注册消息所在 __consumer_offsets 主题中的分区号,依次调用了 GroupCoordinator.partitionFor -> GroupMetadataManager.partitionFor 方法
//查找给定消费者组元数据消息所在__consumer_offset主题的分区号def partitionFor(groupId: String): Int = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
2. 向消费者组加入成员
和第一阶段类似,在调用了 KafkaConsumer.poll 方法后,最终调用了AbstractCoordinator.sendJoinGroupRequest 方法。在该方法中,向消费者组对应的 GroupCoordinator 所在节点发送了JoinGroupRequest 请求。
在服务端,处理 JoinGroupRequest 请求的方法是 KafkaApis.handleJoinGroupRequest 方法,其中重点逻辑如下:
def handleJoinGroupRequest(request: RequestChannel.Request) {//获取请求对象val joinGroupRequest = request.body[JoinGroupRequest]...//获取消费者配置的所有分区分配策略val protocols = joinGroupRequest.data.protocols.valuesList.asScala.map(protocol =>(protocol.name, protocol.metadata)).toList//TODO 重点逻辑在handleJoinGroup方法中groupCoordinator.handleJoinGroup(joinGroupRequest.data.groupId,joinGroupRequest.data.memberId,groupInstanceId,requireKnownMemberId,request.header.clientId,request.session.clientAddress.toString,joinGroupRequest.data.rebalanceTimeoutMs,joinGroupRequest.data.sessionTimeoutMs,joinGroupRequest.data.protocolType,protocols,sendResponseCallback)...}
def handleJoinGroup(groupId: String,//消费者组名称memberId: String,//成员idgroupInstanceId: Option[String],//组实例ID,用于标识静态成员requireKnownMemberId: Boolean,//是否需要成员ID不为空clientId: String,//client.id值clientHost: String,//消费者程序主机名rebalanceTimeoutMs: Int,//rebalance超时时间sessionTimeoutMs: Int,//会话超时时间protocolType: String,//协议类型,普通消费者就是consumerprotocols: List[(String, Array[Byte])],//分区分配策略集合responseCallback: JoinCallback//回调函数): Unit = {//验证组状态的合法性validateGroupStatus(groupId, ApiKeys.JOIN_GROUP).foreach { error =>responseCallback(joinError(memberId, error))return}//会话超时时间如果设置不合适,即<6秒 或者 > 1800秒,则返回一个INVALID_SESSION_TIMEOUT异常响应if (sessionTimeoutMs < groupConfig.groupMinSessionTimeoutMs ||sessionTimeoutMs > groupConfig.groupMaxSessionTimeoutMs) {responseCallback(joinError(memberId, Errors.INVALID_SESSION_TIMEOUT))} else {//判断请求中是否存在memberId,如果是新创建的消费者,发送请求时是没有memberId的val isUnknownMember = memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID//根据消费者组id,获取组元数据对象groupManager.getGroup(groupId) match {//如果没有获取到组元数据对象case None =>//如果消费者第一次加入,则没有memberId信息if (isUnknownMember) {//则根据消费者组id创建一个元数据对象,并交给GroupMetadataManager管理val group = groupManager.addGroup(new GroupMetadata(groupId, Empty, time))//为空memberId成员执行加入组操作doUnknownJoinGroup(group, groupInstanceId, requireKnownMemberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)} else {//如果消费者不是首次加入,则返回UNKNOWN_MEMBER_ID异常响应responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))}//如果获取到了组元数据对象case Some(group) =>group.inLock {//如果满足以下条件之一,则将该消费者从组中移除,返回GROUP_MAX_SIZE_REACHED异常信息// 1.该消费者组已满员,且组中包含该消费者成员信息,且该成员不是正在等待加入组// 消费者数量由group.max.size参数配置,默认为Int.MaxValue// 2.是新加入的消费者,且消费者组已满if ((groupIsOverCapacity(group)&& group.has(memberId) && !group.get(memberId).isAwaitingJoin) // oversized group, need to shed members that haven't joined yet|| (isUnknownMember && group.size >= groupConfig.groupMaxSize)) {group.remove(memberId)group.removeStaticMember(groupInstanceId)responseCallback(joinError(JoinGroupRequest.UNKNOWN_MEMBER_ID, Errors.GROUP_MAX_SIZE_REACHED))} else if (isUnknownMember) {//为空memberId成员执行加入组操作doUnknownJoinGroup(group, groupInstanceId, requireKnownMemberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)} else {//为非空memberId成员执行加入组操作doJoinGroup(group, memberId, groupInstanceId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)}//如果消费者组正处于PreparingRebalance状态if (group.is(PreparingRebalance)) {//尝试执行加入组joinPurgatory.checkAndComplete(GroupKey(group.groupId))}}}}}
如果没有获取到,则看消费者是否是第一次加入组,即 memberId 为空 如果 memberId 为空,则根据消费者组id创建一个消费者组元数据对象,并交给GroupMetadataManager管理,然后调用 doUnknownJoinGroup 方法为空 memberId 成员执行加入组操作 如果 memberId不为空,则封装UNKNOWN_MEMBER_ID异常并调用回调函数返回 如果获取到了消费者组元数据,则判断是否满足下列条件之一,如果满足则将该消费者从组中移除,封装GROUP_MAX_SIZE_REACHED异常并调用回调函数返回 该消费者组已满,且组中包含该消费者成员信息,且该成员不是正在等待加入组。这里消费者组容量由group.max.size参数配置,默认为Int.MaxValue 该消费者是新准备加入的,且消费者组已满 如果上面两个条件均不满足,说明消费者组未满,可以加入成员。然后判断待加入的成员是否为新成员,即 memberId 为空
如果 memberId 为空,则调用 doUnknownJoinGroup 方法为空 memberId 成员执行加入组操作
否则,调用 doJoinGroup 方法为非空memberId成员执行加入组操作
最后,判断消费者组如果正处于PreparingRebalance状态,则尝试加入组
private def doUnknownJoinGroup(group: GroupMetadata,//消费者组元数据groupInstanceId: Option[String],requireKnownMemberId: Boolean,clientId: String,//client.idclientHost: String,//消费者程序主机名rebalanceTimeoutMs: Int,//Rebalance超时时间sessionTimeoutMs: Int,//会话超时时间protocolType: String,//协议类型protocols: List[(String, Array[Byte])],//分配分配策略列表responseCallback: JoinCallback//回调函数): Unit = {group.inLock {if (group.is(Dead)) {//如果消费者组状态为Dead,封装COORDINATOR_NOT_AVAILABLE异常并调用回调函数返回responseCallback(joinError(JoinGroupRequest.UNKNOWN_MEMBER_ID, Errors.COORDINATOR_NOT_AVAILABLE))//如果成员配置的协议类型/分区消费分配策略与消费者组的不匹配,封装INCONSISTENT_GROUP_PROTOCOL异常并调用回调函数返回//这里需要注意一点:新加入成员的设置的分区分配策略,必须至少有一个策略是组内所有成员都支持的,因为消费者组选举分区分配策略时//第一步就是要获取所有成员都支持的分区分配策略,否则无法选举} else if (!group.supportsProtocols(protocolType, MemberMetadata.plainProtocolSet(protocols))) {responseCallback(joinError(JoinGroupRequest.UNKNOWN_MEMBER_ID, Errors.INCONSISTENT_GROUP_PROTOCOL))} else {//给消费者成员分配一个memberId,用client.di+'-'+UUID 拼接而成val newMemberId = group.generateMemberId(clientId, groupInstanceId)//如果配置了静态成员(暂时不考虑)if (group.hasStaticMember(groupInstanceId)) {...//如果要求成员ID不为空,默认为true} else if (requireKnownMemberId) {//将该成员加入到待决成员列表group.addPendingMember(newMemberId)addPendingMemberExpiration(group, newMemberId, sessionTimeoutMs)//封装MEMBER_ID_REQUIRED异常并携带新生成的memberId,调用回调函数返回responseCallback(joinError(newMemberId, Errors.MEMBER_ID_REQUIRED))//如果请求中没有memberId,实际是不走这个分支的} else {//添加成员addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, newMemberId, groupInstanceId,clientId, clientHost, protocolType, protocols, group, responseCallback)}}}}
第一步:判断消费者组的状态是否为Dead,如果是,则封装COORDINATOR_NOT_AVAILABLE异常并调用回调函数返回 第二步:判断加入组的成员配置的协议类型/分区分配策略与消费者组的是否匹配,如果不匹配,封装INCONSISTENT_GROUP_PROTOCOL异常并调用回调函数返回。这里需要注意一点:新加入成员设置的分区分配策略,必须至少有一个策略是组内所有成员都支持的,因为消费者组选举分区分配策略时,第一步就是要获取所有成员都支持的分区分配策略 第三步:如果组状态不是Dead,且协议和分区分配策略都匹配,则先给该成员生成一个 memberId,用client.di+'-'+UUID 拼接而成。 第四步:如果要求成员ID不为空,即 requireKnownMemberId = true(默认为true),则将该成员加入到待决定成员列表,然后封装MEMBER_ID_REQUIRED异常并携带新生成的memberId,调用回调函数返回
doJoinGroup:为配置了 memberId 的成员,执行加入组逻辑
验证组信息及成员信息,处理待决定成员的入组 处理非待决成员的入组
group.inLock {if (group.is(Dead)) {//如果消费者组状态为Dead,封装COORDINATOR_NOT_AVAILABLE异常并调用回调函数返回responseCallback(joinError(memberId, Errors.COORDINATOR_NOT_AVAILABLE))//如果成员配置的协议类型/分区消费分配策略与消费者组的不匹配,封装INCONSISTENT_GROUP_PROTOCOL异常并调用回调函数返回} else if (!group.supportsProtocols(protocolType, MemberMetadata.plainProtocolSet(protocols))) {responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL))//如果是待决成员,由于这次分配了成员ID,故允许加入组} else if (group.isPendingMember(memberId)) {if (groupInstanceId.isDefined) {throw new IllegalStateException(s"the static member $groupInstanceId was unexpectedly to be assigned " +s"into pending member bucket with member id $memberId")//如果没有定义group.instance.id参数} else {//让成员加入组,如果还未选出Leader成员,则设置当前成员为LeaderaddMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, memberId, groupInstanceId,clientId, clientHost, protocolType, protocols, group, responseCallback)}}
private def addMemberAndRebalance(rebalanceTimeoutMs: Int,sessionTimeoutMs: Int,memberId: String,groupInstanceId: Option[String],clientId: String,clientHost: String,protocolType: String,protocols: List[(String, Array[Byte])],group: GroupMetadata,callback: JoinCallback) {//初始化成员元数据对象val member = new MemberMetadata(memberId, group.groupId, groupInstanceId,clientId, clientHost, rebalanceTimeoutMs,sessionTimeoutMs, protocolType, protocols)//标记是新成员member.isNew = true//如果组状态为PreparingRebalance,且generationId == 0,说明是第一次进行Rebalanceif (group.is(PreparingRebalance) && group.generationId == 0)//设置newMemberAdded = truegroup.newMemberAdded = true//将成员信息添加到组元数据对象中,如果还没有选出Leader成员,则设置当前成员为Leadergroup.add(member, callback)// 设置下次心跳超期时间completeAndScheduleNextExpiration(group, member, NewMemberJoinTimeoutMs)if (member.isStaticMember)group.addStaticMember(groupInstanceId, memberId)else//从待决成员列表中移除group.removePendingMember(memberId)//准备开启RebalancemaybePrepareRebalance(group, s"Adding new member $memberId with group instanceid $groupInstanceId")}
第一步:根据给定的元数据信息初始化成员元数据对象
第二步:标记该成员是新加入组的
第三步:如果组状态是PreparingRebalance,且generationId == 0,说明是第一次进行Rebalance,那么设置newMemberAdded = true。这个变量的作用,是 Kafka 为消费者组 Rebalance 流程做的一个性能优化。大致的思想,是在消费者组首次进行 Rebalance 时,让 Coordinator 多等待一段时间,从而让更多的消费者组成员加入到组中,以免后来者申请入组而反复进行 Rebalance。这段多等待的时间,由服务端参数 group.initial.rebalance.delay.ms 设置。
第四步:将成员信息添加到对应消费者组的元数据对象中,如果还没有选出Leader成员,则设置当前成员为Leader
第五步:完成心跳并设置下次心跳超时的时间
第六步:将该成员从待决成员中移除,并调用 maybePrepareRebalance 准备开启 Rebalance。
至于 maybePrepareRebalance 方法,在第二阶段也会调用,后面再进行分析
第二阶段:
处理非待决成员的入组
else {val groupInstanceIdNotFound = groupInstanceId.isDefined && !group.hasStaticMember(groupInstanceId)if (group.isStaticMemberFenced(memberId, groupInstanceId)) {responseCallback(joinError(memberId, Errors.FENCED_INSTANCE_ID))} else if (!group.has(memberId) || groupInstanceIdNotFound) {responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))} else {//根据成员id获取成员元数据对象val member = group.get(memberId)//根据消费者组当前的状态,执行不同的操作group.currentState match {//如果是PreparingRebalance状态case PreparingRebalance =>//更新成员信息并开始准备RebalanceupdateMemberAndRebalance(group, member, protocols, responseCallback)//如果是CompletingRebalance状态case CompletingRebalance =>//判断请求中的分区分配策略是否和内存中的一致,如果一致说明该成员以前申请过加入组,Coordinator也批准了,但是该消费者没有收到//如果一致还说明该成员的元数据信息未发生改变if (member.matches(protocols)) {//直接返回当前组信息responseCallback(JoinGroupResult(members = if (group.isLeader(memberId)) {group.currentMemberMetadata} else {List.empty},memberId = memberId,generationId = group.generationId,subProtocol = group.protocolOrNull,leaderId = group.leaderOrNull,error = Errors.NONE))} else {//如果分配策略和内存中不一致,说明该成员的元数据发生了变更,那么更新成员信息并开始准备RebalanceupdateMemberAndRebalance(group, member, protocols, responseCallback)}//如果是Stable状态case Stable =>val member = group.get(memberId)//如果该成员是Leader成员,或者该成员的元数据发生了变更if (group.isLeader(memberId) || !member.matches(protocols)) {//更新成员信息并开始准备RebalanceupdateMemberAndRebalance(group, member, protocols, responseCallback)//如果不是Leader消费者,且元数据未发生变更} else {//直接返回当前组信息responseCallback(JoinGroupResult(members = List.empty,memberId = memberId,generationId = group.generationId,subProtocol = group.protocolOrNull,leaderId = group.leaderOrNull,error = Errors.NONE))}//如果是其它状态,封装UNKNOWN_MEMBER_ID异常调用回调函数返回case Empty | Dead =>warn(s"Attempt to add rejoining member $memberId of group ${group.groupId} in " +s"unexpected group state ${group.currentState}")responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))}}}
如果是 PreparingRebalance 状态:调用 updateMemberAndRebalance 更新成员信息并准备 Rebalance 如果是 CompletingRebalance 状态:判断请求中的分区分配策略是否和内存中的一致 如果一致说明该成员以前申请过加入组,GroupCoordinator也同意了,但该成员没有收到同意的信息;同时也说明:该成员的元数据信息未发生改变,可以直接返回当前的组信息 如果不一致则说明该成员的元数据信息发生了改变,调用 updateMemberAndRebalance 更新成员信息并准备 Rebalance 如果是 Stable 状态:判断该成员是否是 Leader 成员,或者该成员的元数据发生了变更 如果满足上面条件之一,调用 updateMemberAndRebalance 更新成员信息并准备 Rebalance 如果均不满足,说明该成员不是 Leader 成员,且元数据信息未发生改变,可以直接返回当前的组信息 如果是 Dead 或者 Empty 状态,则封装UNKNOWN_MEMBER_ID异常调用回调函数返回
private def updateMemberAndRebalance(group: GroupMetadata,member: MemberMetadata,protocols: List[(String, Array[Byte])],callback: JoinCallback) {//更新消费者组元数据group.updateMember(member, protocols, callback)//尝试准备进行RebalancemaybePrepareRebalance(group, s"Updating metadata for member ${member.memberId}")}
根据新加入成员的元数据信息,更新消费者组元数据 尝试准备进行Rebalance操作
private def maybePrepareRebalance(group: GroupMetadata, reason: String) {group.inLock {//如果可以进行Rebalance//即当前组状态为Stable, CompletingRebalance, Empty中的一种if (group.canRebalance)//准备进行RebalanceprepareRebalance(group, reason)}}
private def prepareRebalance(group: GroupMetadata, reason: String) {//如果是CompletingRebalance状态if (group.is(CompletingRebalance))//清空分配方案并发给所有成员,携带REBALANCE_IN_PROGRESS异常resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS)//如果是Empty状态,则初始化InitialDelayedJoin对象val delayedRebalance = if (group.is(Empty))new InitialDelayedJoin(this,joinPurgatory,group,groupConfig.groupInitialRebalanceDelayMs,groupConfig.groupInitialRebalanceDelayMs,max(group.rebalanceTimeoutMs - groupConfig.groupInitialRebalanceDelayMs, 0))else//如果是Stable状态,则初始化DelayedJoin对象new DelayedJoin(this, group, group.rebalanceTimeoutMs)//将组状态转为PreparingRebalancegroup.transitionTo(PreparingRebalance)info(s"Preparing to rebalance group ${group.groupId} in state ${group.currentState} with old generation " +s"${group.generationId} (${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)}) (reason: $reason)")val groupKey = GroupKey(group.groupId)//尝试完成加入组操作,如果没有完成,则设置监听,延时进行加入joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))}
def tryCompleteElseWatch(operation: T, watchKeys: Seq[Any]): Boolean = {assert(watchKeys.nonEmpty, "The watch key list can't be empty")var isCompletedByMe = operation.tryComplete()...}
def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean) = {group.inLock {//如果所有成员都已经加入if (group.hasAllMembersJoined)forceComplete()else false}}
hasAllMembersJoined:
//判断组中是否创建了所有成员的元数据对象,条件有两个//1.组中成员元数据对象数 = 申请加入组的成员数//2.待决成员列表为空def hasAllMembersJoined = members.size == numMembersAwaitingJoin && pendingMembers.isEmpty
def onCompleteJoin(group: GroupMetadata) {group.inLock {...if (group.is(Dead)) {info(s"Group ${group.groupId} is dead, skipping rebalance stage")//如果组成员不为空,且还未选出Leader成员} else if (!group.maybeElectNewJoinedLeader() && group.allMembers.nonEmpty) {error(s"Group ${group.groupId} could not complete rebalance because no members rejoined")joinPurgatory.tryCompleteElseWatch(new DelayedJoin(this, group, group.rebalanceTimeoutMs),Seq(GroupKey(group.groupId)))} else {//选举分区分配策略group.initNextGeneration()//如果组为空if (group.is(Empty)) {info(s"Group ${group.groupId} with generation ${group.generationId} is now empty " +s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")//向位移主题写入消费者组元数据groupManager.storeGroup(group, Map.empty, error => {if (error != Errors.NONE) {warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}")}})//如果组不为空} else {info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")//遍历所有组成员for (member <- group.allMemberMetadata) {//封装回调结果val joinResult = JoinGroupResult(//如果是Leader成员,该members变量是组内的所有成员//如果不是Leader成员,该members变量为空members = if (group.isLeader(member.memberId)) {group.currentMemberMetadata} else {List.empty},memberId = member.memberId,generationId = group.generationId,//选举出的分去分配策略,是唯一的subProtocol = group.protocolOrNull,leaderId = group.leaderOrNull,error = Errors.NONE)//调用回调函数返回group.maybeInvokeJoinCallback(member, joinResult)//完成当前心跳任务并设置下一个completeAndScheduleNextHeartbeatExpiration(group, member)//标记该成员为非新成员member.isNew = false}}}}}
3. 消费者接收响应并分配消费方案,发送同步组请求,向所有消费者同步分配方案
if (error == Errors.NONE) {log.debug("Received successful JoinGroup response: {}", joinResponse);sensors.joinLatency.record(response.requestLatencyMs());synchronized (AbstractCoordinator.this) {if (state != MemberState.REBALANCING) {future.raise(new UnjoinedGroupException());} else {//根据响应中的generationId、memberId和分区分配策略更新generation对象AbstractCoordinator.this.generation = new Generation(joinResponse.data().generationId(),joinResponse.data().memberId(), joinResponse.data().protocolName());//如果是Leader成员if (joinResponse.isLeader()) {onJoinLeader(joinResponse).chain(future);//如果是普通成员} else {onJoinFollower().chain(future);}}}}
这里重点是调用 onJoinLeader 方法对 Leader 成员的处理和调用 onJoinFollower 方法对普通成员的处理
onJoinLeader:根据返回的分区分配策略,为所有消费者分配消费分区,然后向 GroupCoordinator 发送 SyncGroupRequest 同步组的请求
private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {try {// perform the leader synchronization and send back the assignment for the group//执行消费分区的分配,返回结果中,key是memberId,value是该消费者分配的消费分区的序列化结果Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(),joinResponse.data().members());List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList = new ArrayList<>();//遍历各个消费者的消费分区分配方案for (Map.Entry<String, ByteBuffer> assignment : groupAssignment.entrySet()) {//封装SyncGroupRequestData对象并加入groupAssignmentList集合groupAssignmentList.add(new SyncGroupRequestData.SyncGroupRequestAssignment().setMemberId(assignment.getKey()).setAssignment(Utils.toArray(assignment.getValue())));}//封装同步组的请求SyncGroupRequest.Builder requestBuilder =new SyncGroupRequest.Builder(new SyncGroupRequestData().setGroupId(groupId).setMemberId(generation.memberId).setGroupInstanceId(this.groupInstanceId.orElse(null)).setGenerationId(generation.generationId).setAssignments(groupAssignmentList));log.debug("Sending leader SyncGroup to coordinator {}: {}", this.coordinator, requestBuilder);//发送同步组的请求return sendSyncGroupRequest(requestBuilder);} catch (RuntimeException e) {return RequestFuture.failure(e);}}
private RequestFuture<ByteBuffer> onJoinFollower() {// 封装同步组的请求SyncGroupRequest.Builder requestBuilder =new SyncGroupRequest.Builder(new SyncGroupRequestData().setGroupId(groupId).setMemberId(generation.memberId).setGroupInstanceId(this.groupInstanceId.orElse(null)).setGenerationId(generation.generationId).setAssignments(Collections.emptyList()));log.debug("Sending follower SyncGroup to coordinator {}: {}", this.coordinator, requestBuilder);//发送同步组请求return sendSyncGroupRequest(requestBuilder);}
服务端处理 SyncGroupRequest 同步组请求的方法是:KafkaApis.handleSyncGroupRequest
def handleSyncGroupRequest(request: RequestChannel.Request) {val syncGroupRequest = request.body[SyncGroupRequest]...else {val assignmentMap = immutable.Map.newBuilder[String, Array[Byte]]//从请求对象中解析出各个消费者的消费分区分配方案,放到assignmentMap集合syncGroupRequest.data.assignments.asScala.foreach { assignment =>assignmentMap += (assignment.memberId -> assignment.assignment)}//调用handleSyncGroup方法进行处理groupCoordinator.handleSyncGroup(syncGroupRequest.data.groupId,syncGroupRequest.data.generationId,syncGroupRequest.data.memberId,Option(syncGroupRequest.data.groupInstanceId),assignmentMap.result,sendResponseCallback)}}
主要是调用了 GroupCoordinator.handleSyncGroup 方法:
def handleSyncGroup(groupId: String,generation: Int,memberId: String,groupInstanceId: Option[String],groupAssignment: Map[String, Array[Byte]],responseCallback: SyncCallback): Unit = {//验证消费者组状态及合法性validateGroupStatus(groupId, ApiKeys.SYNC_GROUP) match {case Some(error) if error == Errors.COORDINATOR_LOAD_IN_PROGRESS =>responseCallback(SyncGroupResult(Array.empty, Errors.REBALANCE_IN_PROGRESS))case Some(error) => responseCallback(SyncGroupResult(Array.empty, error))//如果验证通过case None =>//获取组元数据对象groupManager.getGroup(groupId) match {//如果没有获取到,则封装Errors.UNKNOWN_MEMBER_ID异常并调用回调函数返回case None => responseCallback(SyncGroupResult(Array.empty, Errors.UNKNOWN_MEMBER_ID))//如果获取到了,执行doSyncGroup方法case Some(group) => doSyncGroup(group, generation, memberId, groupInstanceId, groupAssignment, responseCallback)}}}
该方法的逻辑是:
第一步:验证消费者组状态的合法性,这里的合法性包括:
消费者组id是否合法,即不为空;
GroupCoordinator是否为Active状态;
消费者组的元数据信息是否正在被加载;如果正在被加载,说明是从位移主题中读取消息并填充缓存中的消费者组元数据,那么当前 Rebalance 过程中各个消费者成员的元数据信息就丢失了,这时需要让消费者组重新从加入组开始。因此,会封装 REBALANCE_IN_PROGRESS 异常,然后调用回调函数返回。一旦消费者组成员接收到此异常,就会重新开启 Rebalance
当前节点的 GroupCoordinator 是否为管理该消费者组的 GroupCoordinator。
第二步:如果不合法则封装对应异常信息并调用回调函数返回;如果合法则通过组 id 获取组元数据对象
未获取到则封装Errors.UNKNOWN_MEMBER_ID异常并调用回调函数返回
如果获取到了调用 doSyncGroup 方法执行同步组操作
doSyncGroup
private def doSyncGroup(group: GroupMetadata,generationId: Int,memberId: String,groupInstanceId: Option[String],groupAssignment: Map[String, Array[Byte]],responseCallback: SyncCallback) {group.inLock {/*** 进行各种合法性验证,不合法则封装对应错误响应并调用回调函数返回*///如果组状态为Dead,封装Errors.COORDINATOR_NOT_AVAILABLE异常并调用回调函数返回if (group.is(Dead)) {responseCallback(SyncGroupResult(Array.empty, Errors.COORDINATOR_NOT_AVAILABLE))} else if (group.isStaticMemberFenced(memberId, groupInstanceId)) {responseCallback(SyncGroupResult(Array.empty, Errors.FENCED_INSTANCE_ID))//判断memberId对应的成员是否属于该消费者组,不属于则封装Errors.UNKNOWN_MEMBER_ID异常并调用回调函数返回} else if (!group.has(memberId)) {responseCallback(SyncGroupResult(Array.empty, Errors.UNKNOWN_MEMBER_ID))//如果成员的generationId是否和组的一致,不一致则封装Errors.ILLEGAL_GENERATION异常并调用回调函数返回} else if (generationId != group.generationId) {responseCallback(SyncGroupResult(Array.empty, Errors.ILLEGAL_GENERATION))} else {/*** 如果通过合法性验证,则根据当前的组状态执行对应的操作*/group.currentState match {//如果为Empty状态,封装UNKNOWN_MEMBER_ID错误并调用回调函数返回case Empty =>responseCallback(SyncGroupResult(Array.empty, Errors.UNKNOWN_MEMBER_ID))//如果为PreparingRebalance状态,封装REBALANCE_IN_PROGRESS错误并调用回调函数返回case PreparingRebalance =>responseCallback(SyncGroupResult(Array.empty, Errors.REBALANCE_IN_PROGRESS))//如果是CompletingRebalance状态case CompletingRebalance =>// 为该消费者组成员设置组同步回调函数group.get(memberId).awaitingSyncCallback = responseCallback//如果是Leader成员发送的同步组请求,需要特殊处理if (group.isLeader(memberId)) {info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")// fill any missing members with an empty assignment//如果有成员没有被分配任何消费方案,则创建一个空的方案给它val missing = group.allMembers -- groupAssignment.keySetval assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap//把消费者组信息保存在消费者组元数据中,并且将其写入到内部位移主题groupManager.storeGroup(group, assignment, (error: Errors) => {group.inLock {//如果组状态是CompletingRebalance以及成员和组的generationId相同if (group.is(CompletingRebalance) && generationId == group.generationId) {//如果有错误if (error != Errors.NONE) {//清空分配方案并发送给所有成员resetAndPropagateAssignmentError(group, error)//准备开启新一轮的RebalancemaybePrepareRebalance(group, s"error when storing group assignment during SyncGroup (member: $memberId)")} else {//如果没有错误//在消费者组元数据中为每个消费者成员保存分配方案并发送给所有成员setAndPropagateAssignment(group, assignment)//将组状态转换为Stable,之后就可以正常提供服务了group.transitionTo(Stable)}}}})}//如果是Stable状态case Stable =>// if the group is stable, we just return the current assignment//获取组元数据对象val memberMetadata = group.get(memberId)//封装同步结果,包含成员消费分区分配方案和Errors.NONE表示无异常,返回调用回调函数返回responseCallback(SyncGroupResult(memberMetadata.assignment, Errors.NONE))//设定成员下次心跳时间completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId))}}}}
这个方法分为两个部分:
第一部分:进行各种合法性校验
如果组状态为Dead,则封装Errors.COORDINATOR_NOT_AVAILABLE异常并调用回调函数返回
如果 memberId 对应的成员不属于该消费者组,则封装Errors.UNKNOWN_MEMBER_ID异常并调用回调函数返回
如果成员的 generationId 和组的一致,则封装Errors.ILLEGAL_GENERATION异常并调用回调函数返回
如果验证都通过了,进入第二部分
第二部分:根据消费者组状态执行对应的操作
如果是 Empty 或者 PreparingRebalance 状态,则封装对应的异常信息并调用回调函数返回
如果是 Stable 状态,说明该消费组是可用状态,那么直接将组的元数据信息封装到响应中,调用回调函数返回;然后设定成员下一次心跳的时间
如果是 CompletingRebalance 状态,则操作相对复杂:
第一步:为该消费者组成员设置组同步回调函数,也就是将传递给回调函数的数据,通过 Response 的方式发送给消费者组成员。
第二步:判断当前成员是否是消费者组的 Leader 成员。如果不是 Leader 成员,方法直接结束,如果是则进行下一步。只有 Leader 成员的 groupAssignment 属性才携带了分配方案
第三步:如果有成员没有被分配任何消费方案,则创建一个空的方案给它
第四步:调用 GroupMetadataManager.storeGroup 方法,把消费者组信息保存在消费者组元数据中,并且将其写入到内部位移主题
第五步:当组状态是 CompletingRebalance 且成员和组的 Generation ID 相同的情况下,判断调用 storeGroup 方法时是否发生错误
如果有错误,则清空分配方案并发送给所有成员,并准备开启新一轮的 Rebalance
如果没有错误,则在消费者组元数据中为每个消费者成员保存各自分配方案并发送给对应的成员,最后将组状态调整为 Stable
如果组状态不是 CompletingRebalance,或者成员和组的 Generation ID 不相同,说明消费者组可能开启了新一轮的 Rebalance,那么,此时就不能继续给成员发送分配方案,方法结束。
在上面将分配方案发送给每个消费者时,调用了 propagateAssignment 方法。其主要做了两件事:
遍历所有的消费者成员,调用回调函数将属于该成员的消费分区分配方案返回
如果回调函数执行成功,完成心跳并设置下一次心跳的超时时间
从该方法中可以知道,每个消费者只接收到了属于自己的消费分区分配方案,而不知道其它消费者的分配方案。
private def propagateAssignment(group: GroupMetadata, error: Errors) {//遍历组成员for (member <- group.allMemberMetadata) {//TODO 调用回调函数,每个消费者只收到了属于自己的分配方案if (group.maybeInvokeSyncCallback(member, SyncGroupResult(member.assignment, error))) {//如果返回true,则设置下次心跳的时间completeAndScheduleNextHeartbeatExpiration(group, member)}}}
对于设置下一次心跳的超时时间,相关的方法有两个:
private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) {completeAndScheduleNextExpiration(group, member, member.sessionTimeoutMs)}private def completeAndScheduleNextExpiration(group: GroupMetadata, member: MemberMetadata, timeoutMs: Long): Unit = {val memberKey = MemberKey(member.groupId, member.memberId)//完成心跳member.heartbeatSatisfied = trueheartbeatPurgatory.checkAndComplete(memberKey)member.heartbeatSatisfied = false//设置下一次心跳val delayedHeartbeat = new DelayedHeartbeat(this, group, member.memberId, isPending = false, timeoutMs)//加入延时操作heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey))}
def handleHeartbeat(groupId: String,memberId: String,groupInstanceId: Option[String],generationId: Int,responseCallback: Errors => Unit) {//合法性验证validateGroupStatus(groupId, ApiKeys.HEARTBEAT).foreach { error =>if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS)responseCallback(Errors.NONE)elseresponseCallback(error)return}//获取消费者组对象groupManager.getGroup(groupId) match {//如果没有获取到case None =>responseCallback(Errors.UNKNOWN_MEMBER_ID)//如果获取到了,验证合法性case Some(group) => group.inLock {if (group.is(Dead)) {responseCallback(Errors.COORDINATOR_NOT_AVAILABLE)} else if (group.isStaticMemberFenced(memberId, groupInstanceId)) {responseCallback(Errors.FENCED_INSTANCE_ID)} else if (!group.has(memberId)) {responseCallback(Errors.UNKNOWN_MEMBER_ID)} else if (generationId != group.generationId) {responseCallback(Errors.ILLEGAL_GENERATION)} else {group.currentState match {case Empty =>responseCallback(Errors.UNKNOWN_MEMBER_ID)case CompletingRebalance =>responseCallback(Errors.REBALANCE_IN_PROGRESS)case PreparingRebalance =>val member = group.get(memberId)//完成心跳并设置下一次心跳的超时时间completeAndScheduleNextHeartbeatExpiration(group, member)responseCallback(Errors.REBALANCE_IN_PROGRESS)case Stable =>val member = group.get(memberId)//完成心跳并设置下一次心跳的超时时间completeAndScheduleNextHeartbeatExpiration(group, member)responseCallback(Errors.NONE)}}}}}
总结:
1. 触发 Rebalance 操作的场景有三大类:
消费者组成员发生变化
消费者组订阅主题或者主题分区数发生变化
管理消费者组的组协调器所在节点发生变化
2. Rebalance 流程共分为四个阶段
寻找管理消费者组的组协调器所在节点
消费者向组协调器发送请求,申请加入消费者组
消费者将分配好的分区消费方案发送给组协调器,让其同步给组内所有成员
消费者向组协调器发送心跳,证明自己活着
3. 组协调器在处理加入组的请求时,有几个重要步骤:
如果申请加入的成员没有id,则生成一个memberId并将该请求"打回",携带生成的memberId,然后客户端进行重发请求,第二次就带有memberId了
组协调器会确定一个Leader成员,只有给它返回的响应中携带所有的成员信息
组协调器会选举出一个分区分配策略发送给Leader成员,将消费分区的分配交给Leader成员而不是自己去分配
4. 组协调器在处理同步组的请求时,给每个消费者返回的响应中,只包含该消费者的消费分区分配方案
5. 消费者只要向组协调器发送请求,无论是否为 HeartBeatRequest 类型,都会认为完成了心跳,然后设置下一次心跳的超时时间
