




位移提交消息(Offset Commit) 消费者组注册消息(Group Metadata) 墓碑消息(Tombstone):value 为 null 的消息,这种消息写入的目的就是为了清理前两种类型中过期的消息
二、图示说明
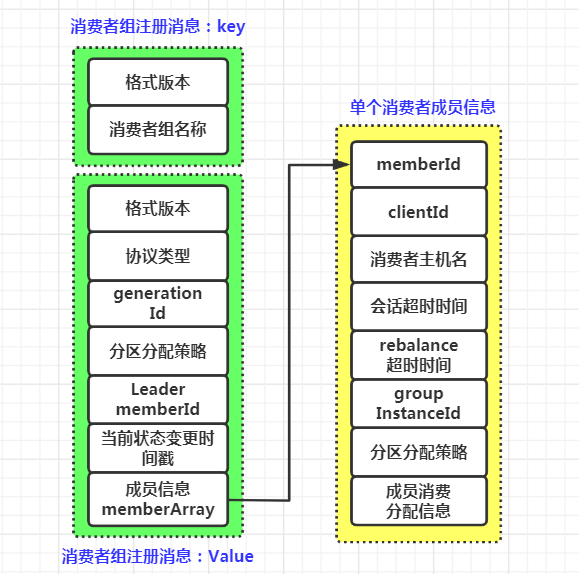
1. 消费者组注册消息的 key-value 信息
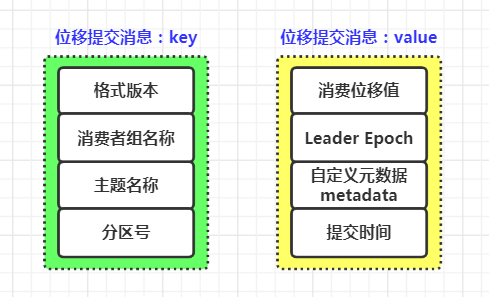
2. 位移提交消息的 key-value 信息
三、源码分析
trait BaseKey{//消息格式的版本def version: Short//消息的keydef key: Any}
消费者成员加入消费者组:Coordinator 向位移主题写入注册消息,只是该消息不含分区消费分配方案;
Leader 成员发送方案给 Coordinator 后:当 Leader 成员将分区消费分配方案发给 Coordinator 后,Coordinator 写入携带分配方案的注册消息。
1.1 消费者组注册消息 key 的定义:
case class GroupMetadataKey(version: Short, key: String) extends BaseKey {override def toString: String = key}
可以看到,对于消费者组注册消息来说,key 是一个字符串类型,保存的就是消费者组的名称,即 group.id 参数的值
在 GroupMetadataManager 中有一个 groupMetadataKey 方法,用于将注册消息的 Key 转换成字节数组,用于后面构造消费者组注册消息
private[group] def groupMetadataKey(group: String): Array[Byte] = {val key = new Struct(CURRENT_GROUP_KEY_SCHEMA)key.set(GROUP_KEY_GROUP_FIELD, group)//构造一个ByteBuffer对象,容纳version和key数据val byteBuffer = ByteBuffer.allocate(2 /* version */ + key.sizeOf)//存入versionbyteBuffer.putShort(CURRENT_GROUP_KEY_SCHEMA_VERSION)//存入keykey.writeTo(byteBuffer)byteBuffer.array()}
1.2 消费者组注册消息 value 的定义:
注册消息 value 在 GroupMetadataManager 的 groupMetadataValue 方法中进行定义,该方法作用是将给定的消费者组的元数据写入到字节数组
private[group] def groupMetadataValue(groupMetadata: GroupMetadata,//消费者组元数据对象assignment: Map[String, Array[Byte]],//分区消费分配方案apiVersion: ApiVersion//Kafka API 版本号,参数 inter.broker.protocol.version 的值): Array[Byte] = {//确定消息格式版本以及格式结构val (version, value) = {if (apiVersion < KAFKA_0_10_1_IV0)(0.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V0))else if (apiVersion < KAFKA_2_1_IV0)(1.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V1))else if (apiVersion < KAFKA_2_3_IV0)(2.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V2))else(3.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V3))}//写入消费者组的重要元数据信息//protocolType,对于普通消费者,就是"consumer"value.set(PROTOCOL_TYPE_KEY, groupMetadata.protocolType.getOrElse(""))//generationId 记录 Rebalance 操作的次数value.set(GENERATION_KEY, groupMetadata.generationId)//分区分配策略value.set(PROTOCOL_KEY, groupMetadata.protocolOrNull)//Leader消费者成员的memberIdvalue.set(LEADER_KEY, groupMetadata.leaderOrNull)if (version >= 2)//写入最近一次状态变更时间戳value.set(CURRENT_STATE_TIMESTAMP_KEY, groupMetadata.currentStateTimestampOrDefault)//写入各个成员的元数据信息val memberArray = groupMetadata.allMemberMetadata.map { memberMetadata =>val memberStruct = value.instance(MEMBERS_KEY)//写入memberIdmemberStruct.set(MEMBER_ID_KEY, memberMetadata.memberId)//写入client.idmemberStruct.set(CLIENT_ID_KEY, memberMetadata.clientId)//写入消费者所在主机名memberStruct.set(CLIENT_HOST_KEY, memberMetadata.clientHost)//写入session超时时间memberStruct.set(SESSION_TIMEOUT_KEY, memberMetadata.sessionTimeoutMs)if (version > 0)//写入rebalance超时时间memberStruct.set(REBALANCE_TIMEOUT_KEY, memberMetadata.rebalanceTimeoutMs)if (version >= 3)//写入groupInstanceIdmemberStruct.set(GROUP_INSTANCE_ID_KEY, memberMetadata.groupInstanceId.orNull)// The group is non-empty, so the current protocol must be defined//获取分区分配策略,必须指定,否则会抛出异常val protocol = groupMetadata.protocolOrNullif (protocol == null)throw new IllegalStateException("Attempted to write non-empty group metadata with no defined protocol")//写入分区分配策略,这个是从多个分区分配策略中选举出来的val metadata = memberMetadata.metadata(protocol)memberStruct.set(SUBSCRIPTION_KEY, ByteBuffer.wrap(metadata))//获取成员的消费分配信息,如果是新加入消费者,这里的分配信息为空,只有同步分配方案时,这里才有分配信息val memberAssignment = assignment(memberMetadata.memberId)assert(memberAssignment != null)// 写入成员消费分配信息memberStruct.set(ASSIGNMENT_KEY, ByteBuffer.wrap(memberAssignment))memberStruct}//写入成员信息数组value.set(MEMBERS_KEY, memberArray.toArray)//申请byteBufferval byteBuffer = ByteBuffer.allocate(2 /* version */ + value.sizeOf)//写入版本信息byteBuffer.putShort(version)//写入上面的元数据信息value.writeTo(byteBuffer)//返回Buffer底层的字节数组byteBuffer.array()}
第一步:根据传入的 apiVersion 参数,确定要使用哪个格式版本,并创建对应版本的结构体(Struct)来保存这些元数据。
第二步:写入消费者组的重要元数据,包括 protocolType,generationId,分区分配策略以及 Leader 消费者的 memberId
第三步:如果 version >=2,写入最近一次消费者组状态变更的时间戳
第四步:写入消费者组中各个成员的元数据信息,这里需要注意的是:
分区分配策略必须指定,而且这个分区分配策略是选举出来的,只有一个
对于成员的消费分配信息,即每个消费者消费哪些主题分区,如果是消费者组加入成员时向 __consumer_offsets 主题写入的注册消息,则分配信息为空;如果是Leader 成员将分区消费分配方案发给 Coordinator 后写入的注册消息,则有分配信息。
第五步:向 Buffer 依次写入版本信息和上面写入的元数据信息,并返回 Buffer 底层的字节数组
已提交位移消息的key定义在 OffsetKey 样例类中:
case class OffsetKey(version: Short, key: GroupTopicPartition) extends BaseKey {override def toString: String = key.toString}
case class GroupTopicPartition(group: String, topicPartition: TopicPartition) {//消费者组id,主题名称,分区号def this(group: String, topic: String, partition: Int) =this(group, new TopicPartition(topic, partition))override def toString: String ="[%s,%s,%d]".format(group, topicPartition.topic, topicPartition.partition)}
private[group] def offsetCommitKey(group: String,topicPartition: TopicPartition): Array[Byte] = {//定义key的结构体val key = new Struct(CURRENT_OFFSET_KEY_SCHEMA)//写入groupId信息key.set(OFFSET_KEY_GROUP_FIELD, group)//写入topic信息key.set(OFFSET_KEY_TOPIC_FIELD, topicPartition.topic)//写入partition信息key.set(OFFSET_KEY_PARTITION_FIELD, topicPartition.partition)//申请ByteBufferval byteBuffer = ByteBuffer.allocate(2 /* version */ + key.sizeOf)//写入版本号byteBuffer.putShort(CURRENT_OFFSET_KEY_SCHEMA_VERSION)//写入结构体key.writeTo(byteBuffer)byteBuffer.array()}
2.2 已提交位移消息 value 的定义:
在 GroupMetadataManager 中定义了 offsetCommitValue 方法,用于定义已提交位移消息的 value 并转成字节数组
private[group] def offsetCommitValue(offsetAndMetadata: OffsetAndMetadata,apiVersion: ApiVersion): Array[Byte] = {//确定消息格式版本以及创建对应的结构体对象val (version, value) = {if (apiVersion < KAFKA_2_1_IV0 || offsetAndMetadata.expireTimestamp.nonEmpty) {val value = new Struct(OFFSET_COMMIT_VALUE_SCHEMA_V1)value.set(OFFSET_VALUE_OFFSET_FIELD_V1, offsetAndMetadata.offset)value.set(OFFSET_VALUE_METADATA_FIELD_V1, offsetAndMetadata.metadata)value.set(OFFSET_VALUE_COMMIT_TIMESTAMP_FIELD_V1, offsetAndMetadata.commitTimestamp)value.set(OFFSET_VALUE_EXPIRE_TIMESTAMP_FIELD_V1,offsetAndMetadata.expireTimestamp.getOrElse(OffsetCommitRequest.DEFAULT_TIMESTAMP))(1, value)} else if (apiVersion < KAFKA_2_1_IV1) {val value = new Struct(OFFSET_COMMIT_VALUE_SCHEMA_V2)value.set(OFFSET_VALUE_OFFSET_FIELD_V2, offsetAndMetadata.offset)value.set(OFFSET_VALUE_METADATA_FIELD_V2, offsetAndMetadata.metadata)value.set(OFFSET_VALUE_COMMIT_TIMESTAMP_FIELD_V2, offsetAndMetadata.commitTimestamp)(2, value)//如果是最新的版本} else {//创建value结构体val value = new Struct(OFFSET_COMMIT_VALUE_SCHEMA_V3)//写入待消费的偏移量value.set(OFFSET_VALUE_OFFSET_FIELD_V3, offsetAndMetadata.offset)//写入Leader Epoch值value.set(OFFSET_VALUE_LEADER_EPOCH_FIELD_V3,offsetAndMetadata.leaderEpoch.orElse(RecordBatch.NO_PARTITION_LEADER_EPOCH))//写入metadata自定义元数据value.set(OFFSET_VALUE_METADATA_FIELD_V3, offsetAndMetadata.metadata)//写入提交时间value.set(OFFSET_VALUE_COMMIT_TIMESTAMP_FIELD_V3, offsetAndMetadata.commitTimestamp)(3, value)}}
第一步:确定消息格式版本以及创建对应的结构体对象
第二步:往结构体对象中写入元数据信息,如消费位移、Leader Epoch值、自定义元数据 metadata 和提交时间。(这里注意,是没有写入过期时间戳信息的)
3. 墓碑消息(Tombstone)
墓碑消息是 value 为 null 的消息。GroupCoordinator 在调用 startup 方法启动的时候,会调用其管理的 GroupMetadataManager 类型属性的 startup 方法,创建一个名为 "delete-expired-group-metadata" 的定时任务,每隔10分钟执行一次,找到 __consumer_offsets 主题中过期的消息,包括位移提交消息和消费者组注册消息,然后创建一个 key 相同,value 为 null 的墓碑消息。
def startup(enableMetadataExpiration: Boolean) {scheduler.startup()if (enableMetadataExpiration) {scheduler.schedule(name = "delete-expired-group-metadata",//创建位移主题定期清理任务fun = () => cleanupGroupMetadata,//调度周期,默认10分钟period = config.offsetsRetentionCheckIntervalMs,unit = TimeUnit.MILLISECONDS)}}
下面具体看一下定期清理任务是如何工作的:
这里调用的是 cleanupGroupMetadata 方法:
private[group] def cleanupGroupMetadata(): Unit = {//获取当前时间val currentTimestamp = time.milliseconds()//调用重载的cleanupGroupMetadata方法,传入两个参数://第一个参数是当前节点的GroupCoordinator管理的所有消费者组元数据//第二个参数是一个函数,用来清理给定消费者组的过期消费位移val numOffsetsRemoved = cleanupGroupMetadata(groupMetadataCache.values, group => {group.removeExpiredOffsets(currentTimestamp, config.offsetsRetentionMs)})info(s"Removed $numOffsetsRemoved expired offsets in ${time.milliseconds() - currentTimestamp} milliseconds.")}
其内部调用了重载的 cleanupGroupMetadata 方法,传入了两个参数:
第一个参数是当前节点的 GroupCoordinator 管理的所有消费者组元数据
第二个参数是一个函数,调用给定消费者组元数据的 removeExpiredOffsets 方法,来清理元数据中保存的过期的消费位移。
关于 removeExpiredOffsets 方法,在上一篇分析过,主要用来清理消费者组元数据中保存的过期消费位移,也就是移除 offsets 变量中关于过期消费位移的信息。
需要注意的是 removeExpiredOffsets 方法的两个参数:
currentTimestamp:表示当前的时间戳
config.offsetsRetentionMs:表示消费者组中消费者被全部移除后,即消费者组状态变为 Empty 后,过多长时间清理位移提交信息,默认是7天
接着看一下重载的 cleanupGroupMetadata 方法:
def cleanupGroupMetadata(groups: Iterable[GroupMetadata], selector: GroupMetadata => Map[TopicPartition, OffsetAndMetadata]): Int = {var offsetsRemoved = 0//遍历GroupCoordinator管理的所有消费者组groups.foreach { group =>val groupId = group.groupId//获取要清理的位移提交信息val (removedOffsets, groupIsDead, generation) = group.inLock {val removedOffsets = selector(group)//如果消费者组状态为Empty,且消费者组元数据中已经没有位移提交信息了,就将消费者组状态转成Deadif (group.is(Empty) && !group.hasOffsets) {info(s"Group $groupId transitioned to Dead in generation ${group.generationId}")group.transitionTo(Dead)}(removedOffsets, group.is(Dead), group.generationId)}//获取消费者组注册信息所在的分区号val offsetsPartition = partitionFor(groupId)//构建主题分区对象val appendPartition = new TopicPartition(Topic.GROUP_METADATA_TOPIC_NAME, offsetsPartition)//如果注册消息所在分区在当前节点存在本地副本,也就是有对应的日志文件getMagic(offsetsPartition) match {case Some(magicValue) =>//时间戳类型为CREATE_TIMEval timestampType = TimestampType.CREATE_TIMEval timestamp = time.milliseconds()//遍历主题分区对象中状态为OfflinePartition的分区replicaManager.nonOfflinePartition(appendPartition).foreach { partition =>//构建一个墓碑消息集合val tombstones = ListBuffer.empty[SimpleRecord]//遍历待移除的提交消息removedOffsets.foreach { case (topicPartition, offsetAndMetadata) =>trace(s"Removing expired/deleted offset and metadata for $groupId, $topicPartition: $offsetAndMetadata")//构建位移提交消息的keyval commitKey = GroupMetadataManager.offsetCommitKey(groupId, topicPartition)//构建墓碑消息并加入集合tombstones += new SimpleRecord(timestamp, commitKey, null)}trace(s"Marked ${removedOffsets.size} offsets in $appendPartition for deletion.")//如果消费者组状态为Dead,且从元数据缓存中移除了该消费者组信息,且generation > 0,说明该消费者组注册消息应该被清理if (groupIsDead && groupMetadataCache.remove(groupId, group) && generation > 0) {//构建注册消息的keyval groupMetadataKey = GroupMetadataManager.groupMetadataKey(group.groupId)//构建墓碑消息并加入集合tombstones += new SimpleRecord(timestamp, groupMetadataKey, null)trace(s"Group $groupId removed from the metadata cache and marked for deletion in $appendPartition.")}//如果有墓碑消息对象if (tombstones.nonEmpty) {try {//构建待写入的消息val records = MemoryRecords.withRecords(magicValue, 0L, compressionType, timestampType, tombstones: _*)//写入本地存储partition.appendRecordsToLeader(records, isFromClient = false, requiredAcks = 0)offsetsRemoved += removedOffsets.sizetrace(s"Successfully appended ${tombstones.size} tombstones to $appendPartition for expired/deleted " +s"offsets and/or metadata for group $groupId")} catch {case t: Throwable =>error(s"Failed to append ${tombstones.size} tombstones to $appendPartition for expired/deleted " +s"offsets and/or metadata for group $groupId.", t)}}}case None =>info(s"BrokerId $brokerId is no longer a coordinator for the group $groupId. Proceeding cleanup for other alive groups")}}offsetsRemoved}
第一步:遍历当前节点 GroupCoordinator 管理的所有消费者组元数据,调用方法参数中的函数清理元数据中的位移提交信息(这里只是清除了内存中的信息),并返回清理的位移提交信息,格式为 Map[TopicPartition, OffsetAndMetadata] ,之后将状态为 Empty,且位移提交信息已经被清理的消费者组的状态置为 Dead。
第二步:判断当前消费者组注册消息所在分区的 Leader 副本是否在当前节点,也就是当前消费者组对应的 GroupCoordinator 是否为当前节点,如果不是则记录一条日志,然后继续遍历下一个消费者组元数据
第三步:如果当前消费者组对应的 GroupCoordinator 是当前节点,那么初始化一个存储墓碑消息的集合 tombstones,然后遍历第一步获取的清理的位移提交信息,封装一个和位移提交消息 key 相同,value 为 null 的墓碑消息并放入集合
第四步:如果消费者组状态为 Dead,且从元数据缓存中移除了该消费者组信息,且 generation > 0,说明该消费者组注册消息应该被清理,那么根据消费者组名称,封装一个和消费者组注册消息 key 相同,value 为 null 的墓碑消息放入集合
第五步:如果墓碑消息集合不为空,则封装消息并写入__consumer_offsets 主题的本地日志文件
之后,__consumer_offsets 主题采用 compact 清理策略清理日志文件,由于后面写入了墓碑消息,之前 key 相同的消息会被清理掉(这里就清理了磁盘文件中的过期消息)。对于墓碑消息,保留一定时间后,也会进行清理。
总结:
- 消费者组注册消息
- 位移提交消息
