




Controller 控制器:接收各种事件,进行封装后交给事件管理器,并定义了 process 方法,用于真正处理各类事件 ControllerEventManager 事件管理器:管理控制器接收到的事件,并启动专属线程进行处理 ControllerChannelManager 通道管理器:维护了 Controller 和集群所有 Broker 节点之间的网络连接,并向 Broker 发送控制类请求及接收响应
二、图示说明
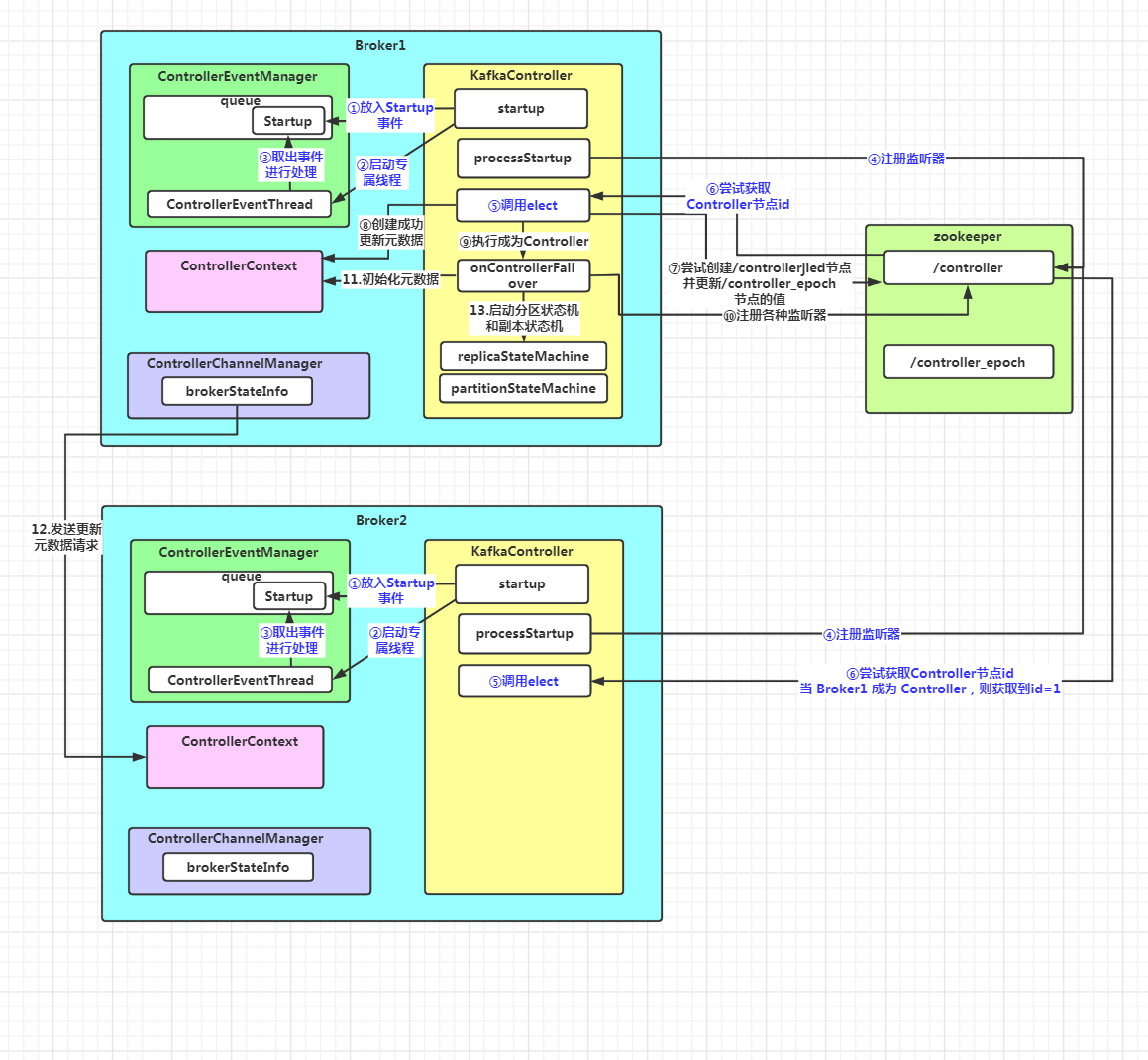
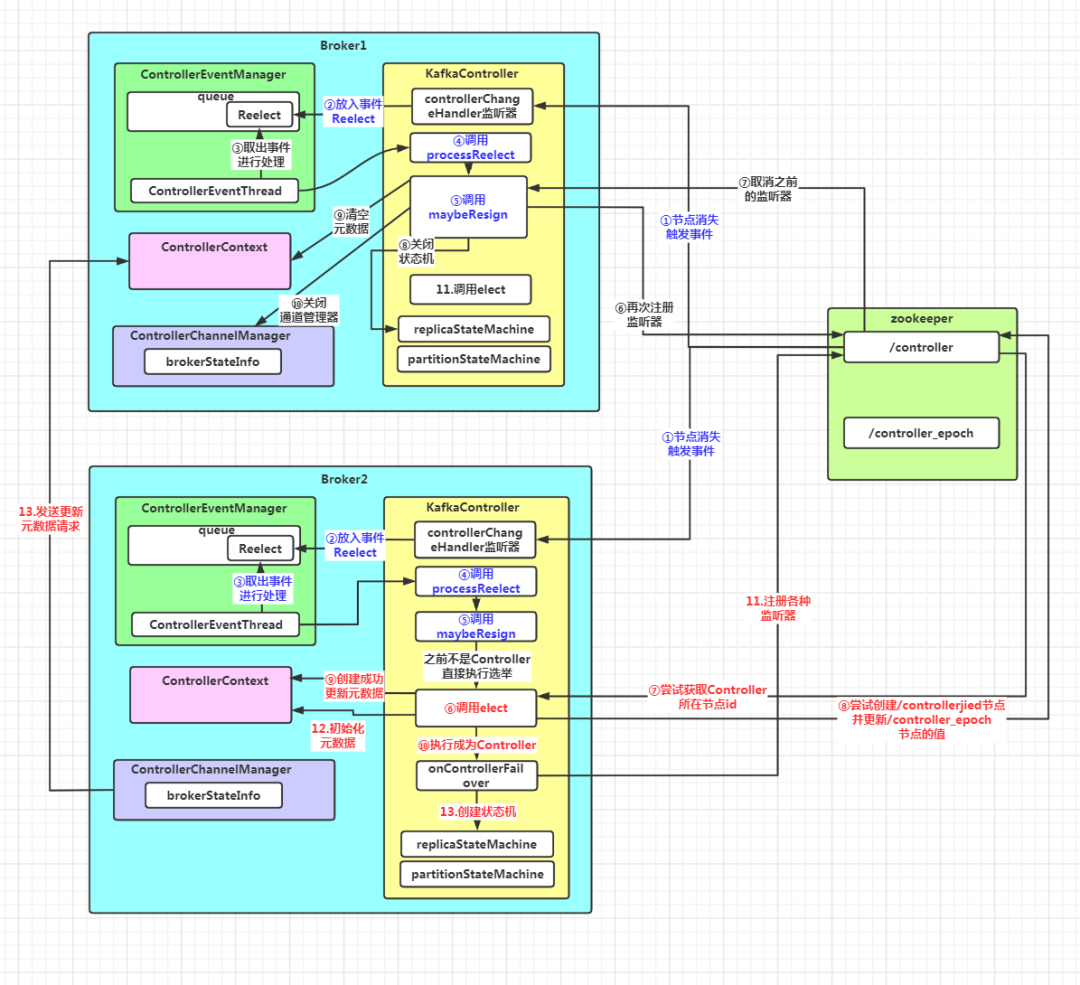
假设 Broker1之前为 Controller,Broker2 为后选举的 Controller,它们监听到/controller 节点消失时前5步是一样的:
三、源码分析
场景一:集群启动时。这时集群中还没有 Controller 角色,所以需要选举出一个 Broker 节点作为 Controller。当一个节点在 zk 集群上创建 controller 节点成功,就称为 Controller,之后其它节点会注册监听器,监听/controller 节点的状态。
场景二:zk集群的/controller 节点消失时。由于/controller 节点是临时节点,当 Controller 所在节点宕机时,就会删除该节点,这就意味着集群没有 Controller 了,其它节点注册的监听器监听到该节点删除的事件,就会触发选举
def startup() {//整个Kafka服务端的功能都在这个里面try {//初始化zk客户端initZkClient(time)//创建KafkaController对象并启动kafkaController = new KafkaController(config, zkClient, time, metrics, brokerInfo, brokerEpoch, tokenManager, threadNamePrefix)kafkaController.startup()}
kafkaController.startup()
def startup() = {//往zkClient的stateChangeHandlers数据结构中添加一个处理器zkClient.registerStateChangeHandler(new StateChangeHandler {//controller-state-change-handleroverride val name: String = StateChangeHandlers.ControllerHandleroverride def afterInitializingSession(): Unit = {eventManager.put(RegisterBrokerAndReelect)}override def beforeInitializingSession(): Unit = {val queuedEvent = eventManager.clearAndPut(Expire)queuedEvent.awaitProcessing()}})//往事件管理器添加Startup事件eventManager.put(Startup)//启动事件管理器eventManager.start()}
startup 方法主要分3步:
注册 ZooKeeper 状态变更监听器,用于监听 Broker 与 ZooKeeper 之间的会话是否过期
将 Startup 事件写入到事件管理器的事件队列
启动事件管理器,主要是启动 ControllerEventThread 线程,开始处理事件队列中的 Startup 事件。
这里 ControllerEventManager 的 put 和 start 方法在上一篇具体分析过,这里不再赘述。
当 ControllerEventThread 线程启动后,会从 ControllerEventManager 的阻塞队列 queue 中取出事件,调用 KafkaController.prosess 方法进行处理。目前事件管理器中只放入了一个 Startup 事件,对应 process 方法中的处理逻辑为:
override def process(event: ControllerEvent): Unit = {try {event match {...//处理启动类事件case Startup =>processStartup()}...}
处理 Startup 事件调用的是processStartup() 方法,逻辑如下:
private def processStartup(): Unit = {//往zk的/controller 节点注册一个监听器,监听节点的变化,包括创建、删除和节点数据的变化zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)//执行选举elect()}
主要就两步:
往 zk 集群的 controller 节点注册一个监听器,监听节点的创建、删除和数据变更。如果节点存在说明选出了控制器,进行注册
调用 elect() 方法进行选举
关于 ControllerChangeHandler 在上一篇分析过,简而言之就是监听 zk 集群 controller 节点的状态,如果发生创建和节点数据变化的事件,则往事件管理器中写入一个ControllerChange 事件;如果发生节点删除事件,则往事件管理器中写入一个 Reelect 事件。
至于 elect() 方法,后面两个场景都会进行调用该方法进行选举,最后进行分析。
注意:上面这个流程是集群中的所有 Broker 都会进行的。
3. controller 节点消失触发的选举流程分析
在 Broker 启动时,往/controller 节点注册了监听器,当监听到删除节点的事件时,会向事件管理器写入一个 Reelect 事件,之后由线程 ControllerEventThread 从阻塞队列中取出,调用 KafkaController.procee 方法进行处理,对应的处理逻辑为:
override def process(event: ControllerEvent): Unit = {try {event match {...//处理重新选举的事件case Reelect =>processReelect()}...}
处理 Reelect 事件调用的是processReelect() 方法,逻辑如下:
private def processReelect(): Unit = {//执行Controller卸任操作maybeResign()//执行新一轮Controller的选举elect()}
主要也是两步:
调用 maybeResign() 方法执行 Controller 卸任的操作
调用 elect() 方法执行新一轮 Controller 的选举
maybeResign() 方法的逻辑如下:
private def maybeResign(): Unit = {//标记Controller变更之前是否在当前节点val wasActiveBeforeChange = isActive//注册ControllerChangeHandler监听器zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)//获取当前集群Controller所在的Broker Id,如果没有Controller则返回-1activeControllerId = zkClient.getControllerId.getOrElse(-1)//如果之前Controller就是该节点,而现在不是了if (wasActiveBeforeChange && !isActive) {//执行 Controller 的卸任操作onControllerResignation()}}
首先,会标记当前节点之前是否为 Controller。如果之前就不是 Controller,就不必再执行后续的卸任操作了
然后会注册 ControllerChangeHandler 监听器,并获取 Controller 所在节点 id,如果不存在返回 -1。这里再次注册监听器的原因是:zk 的监听机制是一次性的,只能触发一次,所以需要再次添加。
如果当前节点之前是 Controller,而现在不是了,则执行卸任操作
调用 onControllerResignation() 方法执行 Controller 的卸任
private def onControllerResignation() {debug("Resigning")//取消各种监听器的注册//取消ISR列表变更监听器的注册zkClient.unregisterZNodeChildChangeHandler(isrChangeNotificationHandler.path)//取消主题分区重分配监听器的注册zkClient.unregisterZNodeChangeHandler(partitionReassignmentHandler.path)//取消preferred Leader选举监听器的注册zkClient.unregisterZNodeChangeHandler(preferredReplicaElectionHandler.path)//取消日志路径变更监听器的注册zkClient.unregisterZNodeChildChangeHandler(logDirEventNotificationHandler.path)//取消Broker信息变更监听器的注册unregisterBrokerModificationsHandler(brokerModificationsHandlers.keySet)// 关闭Kafka线程调度器,其实就是取消定期的Leader重选举kafkaScheduler.shutdown()//统计字段清零offlinePartitionCount = 0preferredReplicaImbalanceCount = 0globalTopicCount = 0globalPartitionCount = 0// 关闭Token过期检查调度器if (tokenCleanScheduler.isStarted)tokenCleanScheduler.shutdown()// 取消分区重分配监听器的注册unregisterPartitionReassignmentIsrChangeHandlers()// 关闭分区状态机partitionStateMachine.shutdown()// 取消主题变更监听器的注册zkClient.unregisterZNodeChildChangeHandler(topicChangeHandler.path)// 取消分区变更监听器的注册unregisterPartitionModificationsHandlers(partitionModificationsHandlers.keys.toSeq)// 取消主题删除监听器的注册zkClient.unregisterZNodeChildChangeHandler(topicDeletionHandler.path)//关闭副本状态机replicaStateMachine.shutdown()//取消Broker变更监听器的注册zkClient.unregisterZNodeChildChangeHandler(brokerChangeHandler.path)// 关闭Controller通道管理器controllerChannelManager.shutdown()// 清空集群元数据controllerContext.resetContext()info("Resigned")}
这个方法的逻辑比较简单:
取消之前注册的各种监听器
将统计字段清零
关闭线程调度器
关闭分区状态机和副本状态机
关闭通道管理器
清空集群的元数据
4. elect():真正进行 Controller 选举的方法
private def elect(): Unit = {//获取Controller所在节点的id,如果没有 Controller,这个变量的初始值为 -1activeControllerId = zkClient.getControllerId.getOrElse(-1)//如果Controller所在节点id 不为 -1,说明已经选举出了Controller,直接返回if (activeControllerId != -1) {debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")return}try {//尝试在 zk 上创建/controller 节点并注册当前节点的信息,包括节点 id 和 时间戳。并更新ControllerEpoch的值val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)//如果注册成功,则更新元数据中的epoch、epochZKVersioncontrollerContext.epoch = epochcontrollerContext.epochZkVersion = epochZkVersion//更新Controller节点所在id为当前的节点idactiveControllerId = config.brokerIdinfo(s"${config.brokerId} successfully elected as the controller. Epoch incremented to ${controllerContext.epoch} " +s"and epoch zk version is now ${controllerContext.epochZkVersion}")//执行当前节点成为Controller的逻辑onControllerFailover()} catch {//如果注册失败了,则抛出ControllerMovedException异常,然后尝试执行Controller的卸任case e: ControllerMovedException =>//执行Controller的卸任操作maybeResign()if (activeControllerId != -1)debug(s"Broker $activeControllerId was elected as controller instead of broker ${config.brokerId}", e)elsewarn("A controller has been elected but just resigned, this will result in another round of election", e)case t: Throwable =>error(s"Error while electing or becoming controller on broker ${config.brokerId}. " +s"Trigger controller movement immediately", t)triggerControllerMove()}
a. 从 zk 集群获取 Controller 节点的 id,如果不存在 Controller,则返回 -1
//获取Controller所在节点的id,集群刚启动时,这个变量的初始值为 -1activeControllerId = zkClient.getControllerId.getOrElse(-1)
b. 判断第一步获取的 Controller 所在节点 id 是否为 -1.如果不是,则说明已经选举出了 Controller,直接返回
if (activeControllerId != -1) {debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")return}
c. 尝试在 zk 上创建/controller 节点并注册当前节点的信息,包括节点 id 和 时间戳。如果注册成功,则更新集群元数据中的 epoch、epochZKVersion,并更新 Controller 节点所在的 id 为当前节点 id。最后执行成为 Controller 的逻辑:
try {//尝试往zk的/controller节点下注册当前节点信息,包括节点id和时间戳,并更新ControllerEpoch的值val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)//如果注册成功,则更新元数据中的epoch、epochZKVersioncontrollerContext.epoch = epochcontrollerContext.epochZkVersion = epochZkVersion//更新Controller节点所在id为当前的节点idactiveControllerId = config.brokerIdinfo(s"${config.brokerId} successfully elected as the controller. Epoch incremented to ${controllerContext.epoch} " +s"and epoch zk version is now ${controllerContext.epochZkVersion}")//执行当前节点成为Controller的逻辑onControllerFailover()}
d. 如果注册失败,则抛出 ControllerMovedException 异常,并执行 Controller 的卸任操作
catch {//如果注册失败了,则抛出ControllerMovedException异常,然后尝试执行Controller的卸任case e: ControllerMovedException =>//执行Controller的卸任操作maybeResign()if (activeControllerId != -1)debug(s"Broker $activeControllerId was elected as controller instead of broker ${config.brokerId}", e)elsewarn("A controller has been elected but just resigned, this will result in another round of election", e)case t: Throwable =>error(s"Error while electing or becoming controller on broker ${config.brokerId}. " +s"Trigger controller movement immediately", t)triggerControllerMove()}
上面涉及到两个关键的方法:
registerControllerAndIncrementControllerEpoch:创建/controller 节点,注册当前节点的信息(version:固定为1;brokerid:当前节点id,timestamp:当前时间戳),并增加/controller_epoch 节点的值,表示选举出了新的 Controller
onControllerFailover:执行当前节点成为 Controller 的逻辑
registerControllerAndIncrementControllerEpoch:
def registerControllerAndIncrementControllerEpoch(controllerId: Int): (Int, Int) = {//获取当前时间val timestamp = time.milliseconds()//获取zk节点/controller_epoch的值和对应zk节点的dataVersion,如果没有则使用默认值0创建该节点val (curEpoch, curEpochZkVersion) = getControllerEpoch.map(e => (e._1, e._2.getVersion)).getOrElse(maybeCreateControllerEpochZNode())//更新Controller Epochval newControllerEpoch = curEpoch + 1val expectedControllerEpochZkVersion = curEpochZkVersiondebug(s"Try to create ${ControllerZNode.path} and increment controller epoch to $newControllerEpoch with expected controller epoch zkVersion $expectedControllerEpochZkVersion")def checkControllerAndEpoch(): (Int, Int) = {//获取zk节点/controller节点的id值val curControllerId = getControllerId.getOrElse(throw new ControllerMovedException(s"The ephemeral node at ${ControllerZNode.path} went away while checking whether the controller election succeeds. " +s"Aborting controller startup procedure"))//如果zk节点的controller id值和传入的id值一致if (controllerId == curControllerId) {//获取zk/controller_epoch节点的值val (epoch, stat) = getControllerEpoch.getOrElse(throw new IllegalStateException(s"${ControllerEpochZNode.path} existed before but goes away while trying to read it"))//如果zk节点的epoch值和当前要更新的值一致,则返回正常的(epoch,dataVersion)if (epoch == newControllerEpoch)return (newControllerEpoch, stat.getVersion)}throw new ControllerMovedException("Controller moved to another broker. Aborting controller startup procedure")}def tryCreateControllerZNodeAndIncrementEpoch(): (Int, Int) = {//封装创建/controller临时节点和更新/controller_epoch节点数据为新epoch值的请求,发送并获取响应//节点/controller的数据格式为{"version":1,"brokerid":0,"timestamp":"xxxxx"}val response = retryRequestUntilConnected(MultiRequest(Seq(CreateOp(ControllerZNode.path, ControllerZNode.encode(controllerId, timestamp), defaultAcls(ControllerZNode.path), CreateMode.EPHEMERAL),SetDataOp(ControllerEpochZNode.path, ControllerEpochZNode.encode(newControllerEpoch), expectedControllerEpochZkVersion))))//根据响应中的结果码,执行对应的操作response.resultCode match {//如果节点已经存在,或者/controller_epoch节点的dataVersion冲突,//则检查/controller节点和/controller_epoch节点的值是否和准备写入或者更新的值一致case Code.NODEEXISTS | Code.BADVERSION => checkControllerAndEpoch()//如果创建成功,则返回新的epoch和对应zk节点的dataVersioncase Code.OK =>val setDataResult = response.zkOpResults(1).rawOpResult.asInstanceOf[SetDataResult](newControllerEpoch, setDataResult.getStat.getVersion)case code => throw KeeperException.create(code)}}tryCreateControllerZNodeAndIncrementEpoch()}
onControllerFailover:执行当前节点成为 Controller 的一些列操作。主要是注册各类 ZooKeeper 监听器、删除日志路径变更和 ISR 副本变更通知事件、启动 Controller 通道管理器,以及启动副本状态机和分区状态机。
private def onControllerFailover() {info("Registering handlers")//先按照监听器的种类,分成监听子节点变化 和 监听当前节点变化,然后遍历监听器进行注册val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,isrChangeNotificationHandler)childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)info("Deleting log dir event notifications")//删除日志路径变更通知zkClient.deleteLogDirEventNotifications(controllerContext.epochZkVersion)info("Deleting isr change notifications")//删除ISR列表变更通知zkClient.deleteIsrChangeNotifications(controllerContext.epochZkVersion)info("Initializing controller context")//初始化集群元数据initializeControllerContext()info("Fetching topic deletions in progress")//获取标记为删除的主题列表和无法删除的主题列表val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()info("Initializing topic deletion manager")//初始化主题删除管理器topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)info("Sending update metadata request")//向集群中的所有Broker发送更新元数据的请求sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set.empty)//启动副本状态机和分区状态机replicaStateMachine.startup()partitionStateMachine.startup()info(s"Ready to serve as the new controller with epoch $epoch")//尝试触发分区的重分配maybeTriggerPartitionReassignment(controllerContext.partitionsBeingReassigned.keySet)//尝试删除主题topicDeletionManager.tryTopicDeletion()//获取等待优先副本选举的分区val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()//进行分区优先副本的选举onPreferredReplicaElection(pendingPreferredReplicaElections, ZkTriggered)info("Starting the controller scheduler")//启动Kafka调度器kafkaScheduler.startup()//如果配置了auto.leader.rebalance.enable为true(默认为true)if (config.autoLeaderRebalanceEnable) {//开启一个名为"auto-leader-rebalance-task"的定时任务来维护分区的优先副本的均衡,周期为5秒scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)}//如果配置了delegation.token.master.key参数不为null(默认为null不开启)if (config.tokenAuthEnabled) {info("starting the token expiry check scheduler")//启动token定期检查调度去tokenCleanScheduler.startup()//进行调度tokenCleanScheduler.schedule(name = "delete-expired-tokens",fun = () => tokenManager.expireTokens,period = config.delegationTokenExpiryCheckIntervalMs,unit = TimeUnit.MILLISECONDS)}}
a. 注册各种监听器
//先按照监听器的种类,分成监听子节点变化 和 监听当前节点变化,然后遍历监听器进行注册val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,isrChangeNotificationHandler)childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)
b. 移除日志路径变更和 ISR 列表变更的通知:
info("Deleting log dir event notifications")//删除日志路径变更通知zkClient.deleteLogDirEventNotifications(controllerContext.epochZkVersion)info("Deleting isr change notifications")//删除ISR列表变更通知zkClient.deleteIsrChangeNotifications(controllerContext.epochZkVersion)
c. 初始化集群元数据:
//初始化集群元数据initializeControllerContext()
这里主要是从zk集群获取各种元数据信息。
注意:在该方法中启动了controllerChannelManager 通道管理器,也就是和所有注册的 Broker 节点创建了网络连接,并启动了发送控制类请求的RequestSendThread线程
private def initializeControllerContext() {val curBrokerAndEpochs = zkClient.getAllBrokerAndEpochsInClustercontrollerContext.setLiveBrokerAndEpochs(curBrokerAndEpochs)info(s"Initialized broker epochs cache: ${controllerContext.liveBrokerIdAndEpochs}")controllerContext.allTopics = zkClient.getAllTopicsInCluster.toSetregisterPartitionModificationsHandlers(controllerContext.allTopics.toSeq)zkClient.getReplicaAssignmentForTopics(controllerContext.allTopics.toSet).foreach {case (topicPartition, assignedReplicas) => controllerContext.updatePartitionReplicaAssignment(topicPartition, assignedReplicas)}controllerContext.partitionLeadershipInfo.clear()controllerContext.shuttingDownBrokerIds = mutable.Set.empty[Int]//注册节点信息变更监听器registerBrokerModificationsHandler(controllerContext.liveOrShuttingDownBrokerIds)//从zk获取并更新所有Leader副本以及 ISR列表的缓存updateLeaderAndIsrCache()//启动通道管理器controllerChannelManager.startup()initializePartitionReassignment()info(s"Currently active brokers in the cluster: ${controllerContext.liveBrokerIds}")info(s"Currently shutting brokers in the cluster: ${controllerContext.shuttingDownBrokerIds}")info(s"Current list of topics in the cluster: ${controllerContext.allTopics}")}
d. 初始化主题删除管理器
//初始化主题删除管理器topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
e. 向集群中所有 Broker 发送更新元数据的请求
//向集群中的所有Broker发送更新元数据的请求sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set.empty)
在这个方法中用到了 ControllerChannelManager 通道管理器,将待发送的请求放入对应 Broker 的阻塞队列中,之后由 RequestSendThread 线程从队列中取出请求发给目标 Broker 并接收返回的响应。
f. 启动副本状态机和分区状态机
//启动副本状态机和分区状态机replicaStateMachine.startup()partitionStateMachine.startup()
g. 尝试触发分区的重分配、尝试删除主题并进行分区优先副本的选举
//尝试触发分区的重分配maybeTriggerPartitionReassignment(controllerContext.partitionsBeingReassigned.keySet)//尝试删除主题topicDeletionManager.tryTopicDeletion()//获取等待优先副本选举的分区val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()//进行分区优先副本的选举onPreferredReplicaElection(pendingPreferredReplicaElections, ZkTriggered)
h. 启动线程调度器
//启动Kafka调度器kafkaScheduler.startup()
i. 根据配置启动定时任务
//如果配置了auto.leader.rebalance.enable为true(默认为true)if (config.autoLeaderRebalanceEnable) {//开启一个名为"auto-leader-rebalance-task"的定时任务来维护分区的优先副本的均衡,周期为5秒scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)}//如果配置了delegation.token.master.key参数不为null(默认为null不开启)if (config.tokenAuthEnabled) {info("starting the token expiry check scheduler")//启动token定期检查调度去tokenCleanScheduler.startup()//进行调度tokenCleanScheduler.schedule(name = "delete-expired-tokens",fun = () => tokenManager.expireTokens,period = config.delegationTokenExpiryCheckIntervalMs,unit = TimeUnit.MILLISECONDS)}
总结:
集群刚启动时 zk 集群上/controller 节点消失时
所有的 Broker 节点都会创建一个 Controller 对象并启动,然后向事件管理器中添加一个Startup事件,并启动 ControllerEventThread 专属线程处理 Startup 事件 之后 Broker 向 zk 的/controller 节点注册一个监听器,并调用 elect 方法执行选举流程 Broker 先获取/controller 节点的值,如果不为 -1 则表示已经选出了 Controller,选举结束 如果为 -1 则尝试在 zk 上创建/controller 节点,并更新/controller_epoch节点的值,如果创建成功,则执行成为 Controller 的逻辑,否则抛出异常
每个 Broker 在/controller 节点注册的监听器会监听到该节点消失的事件,并向事件管理器添加一个 Reelect 事件 进行 Reelect 事件的处理,如果 Broker 之前是 Controller,则执行卸任操作 然后进行 Controller 的选举。先获取/controller 节点的值,如果不为 -1 则表示已经选出了 Controller,选举结束 如果为 -1 则尝试在 zk 上创建/controller 节点,并更新/controller_epoch节点的值,如果创建成功,则执行成为 Controller 的逻辑,否则抛出异常
