




在 Kafka 的运行过程中,难免会发生分区 Leader 副本不可用的现象,这时就需要在 ISR 列表中选择一个 Follower 副本切换为 Leader 副本对外提供服务,那么 Follower 副本和 Leader 副本之间的切换就是副本管理器进行管理的,具体如何进行切换,这篇进行详细说明。
三、源码分析
ReplicaManager 类:它是副本管理器的具体实现代码,里面定义了读写副本、删除副本消息的方法以及其他管理方法。 ReplicaManager 对象:ReplicaManager 类的伴生对象,定义了 几个常量。 FetchPartitionData类:定义获取到的分区数据以及重要元数据信息,如高水位值、Log Start Offset 值等。 LogReadResult 类:表示副本管理器从副本本地日志读取到的消息数据以及相关元数据信息,如高水位值、Log Start Offset 值等。 LogReadResult 对象:LogReadResult 类的伴生对象,只定义了一个UnknownLogReadResult常量 LogDeleteRecordsResult类:表示副本管理器执行副本日志删除操作后返回的结果信息。 LogAppendResult类:表示副本管理器执行副本日志写入操作后返回的结果信息。
class ReplicaManager(val config: KafkaConfig,//配置管理类metrics: Metrics,//监控指标类time: Time,val zkClient: KafkaZkClient,//zk客户端对象scheduler: Scheduler,//调度器val logManager: LogManager,//日志管理器val isShuttingDown: AtomicBoolean,//是否已经关闭quotaManagers: QuotaManagers,//配额管理器val brokerTopicStats: BrokerTopicStats,val metadataCache: MetadataCache,//Broker元数据缓存logDirFailureChannel: LogDirFailureChannel,//失效日志路径的处理类// 处理延时PRODUCE生产请求的Purgatoryval delayedProducePurgatory: DelayedOperationPurgatory[DelayedProduce],// 处理延时FETCH拉取请求的Purgatoryval delayedFetchPurgatory: DelayedOperationPurgatory[DelayedFetch],// 处理延时DELETE_RECORDS删除请求的Purgatoryval delayedDeleteRecordsPurgatory: DelayedOperationPurgatory[DelayedDeleteRecords],// 处理延时ELECT_LEADERS leader选举请求的Purgatoryval delayedElectPreferredLeaderPurgatory: DelayedOperationPurgatory[DelayedElectPreferredLeader],threadNamePrefix: Option[String]) extends Logging with KafkaMetricsGroup {...}
logManager:日志管理器。它负责创建和管理分区的日志对象,里面定义了很多操作日志对象的方法,如 getOrCreateLog 等。 metadataCache:Broker 端的元数据缓存。保存集群上分区的 Leader、ISR 等信息。每台 Broker 上的元数据缓存,是从 Controller 端的元数据缓存异步同步过来的。 四个Purgatory相关的属性:这 4 个属性是 delayedProducePurgatory、delayedFetchPurgatory、delayedDeleteRecordsPurgatory 和 delayedElectLeaderPurgatory,它们分别管理 4 类延时请求:对应分别存放延时生产者请求、延时消费者请求、延时消息删除请求和延时 Leader 选举请求。
在副本管理过程中,状态的变更大多都会引发对延时请求的处理。
ReplicaManager类中定义的几个关键变量:
controllerEpoch:控制器的纪元值,用于隔离控制器的请求,如果控制器请求携带的epoch值小于该值,说明是过期的controller发送的请求,不予处理 localBrokerId:当前broker节点的id值 allPartitions:保存当前broker上所有分区对象的对象池。ReplicaManager对于分区的管理主要就是通过分区对象Partition实现的 replicaFetcherManager:用于创建ReplicaFetcherThread线程,比如其关键的createFetcherThread() 方法:
override def createFetcherThread(fetcherId: Int, sourceBroker: BrokerEndPoint): ReplicaFetcherThread = {val prefix = threadNamePrefix.map(tp => s"$tp:").getOrElse("")val threadName = s"${prefix}ReplicaFetcherThread-$fetcherId-${sourceBroker.id}"//创建ReplicaFetcherThread线程实例对象并返回new ReplicaFetcherThread(threadName, fetcherId, sourceBroker, brokerConfig, failedPartitions, replicaManager,metrics, time, quotaManager)}
2.ReplicaManager如何进行数据的读写
Kafka 中需要进行副本写入的场景:
场景一:生产者向 Leader 副本写入消息;
场景二:Follower 副本拉取消息后写入自身存储;
场景三:消费者组写入组信息;
场景四:事务管理器写入事务信息(包括事务标记、事务元数据等)。
除了场景二是直接调用的 Partition 的方法实现,其他场景都是调用 ReplicaManager.appendRecords 实现的
这里不详细分析 appendRecords() 方法,只需要知道:
将数据追加到本地日志对应的方法是:appendToLocalLog()
判断是否需要等待其他副本写入的方法是:delayedProduceRequestRequired()
private def delayedProduceRequestRequired(requiredAcks: Short,entriesPerPartition: Map[TopicPartition, MemoryRecords],localProduceResults: Map[TopicPartition, LogAppendResult]): Boolean = {requiredAcks == -1 &&entriesPerPartition.nonEmpty &&localProduceResults.values.count(_.exception.isDefined) < entriesPerPartition.size}
requiredAcks 必须等于 -1 依然有数据尚未写完 至少有一个分区的消息已经成功地被写入到本地日志。
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)//创建DelayedProduce延时请求对象val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)val producerRequestKeys = entriesPerPartition.keys.map(new TopicPartitionOperationKey(_)).toSeq/再一次尝试完成该延时请求//如果暂时无法完成,则将对象放入到相应的Purgatory中等待后续处理delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
副本读取数据的方法:fetchMessages()
def fetchMessages(timeout: Long,//请求处理的超时时间replicaId: Int,//副本ID。对于消费者来说,这个值为-1,如果是Follower副本,该值就是Follower副本所在节点的Broker IDfetchMinBytes: Int,//能够获取的最小字节数fetchMaxBytes: Int,//能够获取的最大字节数hardMaxBytesLimit: Boolean,//是否能超过最大字节数限制,如果为True,则表示返回的数据字节数绝对不允许超过最大字节数fetchInfos: Seq[(TopicPartition, PartitionData)],//读取分区的信息,比如读哪些分区,从分区的哪个偏移量开始读取,最多读取多少字节等quota: ReplicaQuota = UnboundedQuota,//配额控制,判断是否需要在读取过程中做限速控制responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit,//回调逻辑isolationLevel: IsolationLevel) {...if (timeout <= 0 || fetchInfos.isEmpty || bytesReadable >= fetchMinBytes || errorReadingData) {//如果满足一个条件,则返回val fetchPartitionData = logReadResults.map { case (tp, result) =>tp -> FetchPartitionData(result.error, result.highWatermark, result.leaderLogStartOffset, result.info.records,result.lastStableOffset, result.info.abortedTransactions)}//调用回调函数responseCallback(fetchPartitionData)//如果不满足上面4个条件,那么拉取请求会进行等待} else {val fetchPartitionStatus = new mutable.ArrayBuffer[(TopicPartition, FetchPartitionStatus)]fetchInfos.foreach { case (topicPartition, partitionData) =>logReadResultMap.get(topicPartition).foreach(logReadResult => {val logOffsetMetadata = logReadResult.info.fetchOffsetMetadatafetchPartitionStatus += (topicPartition -> FetchPartitionStatus(logOffsetMetadata, partitionData))})}val fetchMetadata = FetchMetadata(fetchMinBytes, fetchMaxBytes, hardMaxBytesLimit, fetchOnlyFromLeader,fetchIsolation, isFromFollower, replicaId, fetchPartitionStatus)//构建DelayedFetch延时请求对象val delayedFetch = new DelayedFetch(timeout, fetchMetadata, this, quota, responseCallback)val delayedFetchKeys = fetchPartitionStatus.map { case (tp, _) => new TopicPartitionOperationKey(tp) }//再次尝试完成请求,如果依然不能完成,则交由Purgatory等待后续处理delayedFetchPurgatory.tryCompleteElseWatch(delayedFetch, delayedFetchKeys)}}
没有设置超时时间,说明请求发送方希望请求被处理后立即返回 拉取请求中没有携带任何要拉取分区的信息 已经拉取到了足够多的数据 拉取过程中出错
如果不满足任何一个条件,那么就会将本次的拉取请求交给管理延时拉取请求的delayedFetchPurgatory,进行对应的延时处理
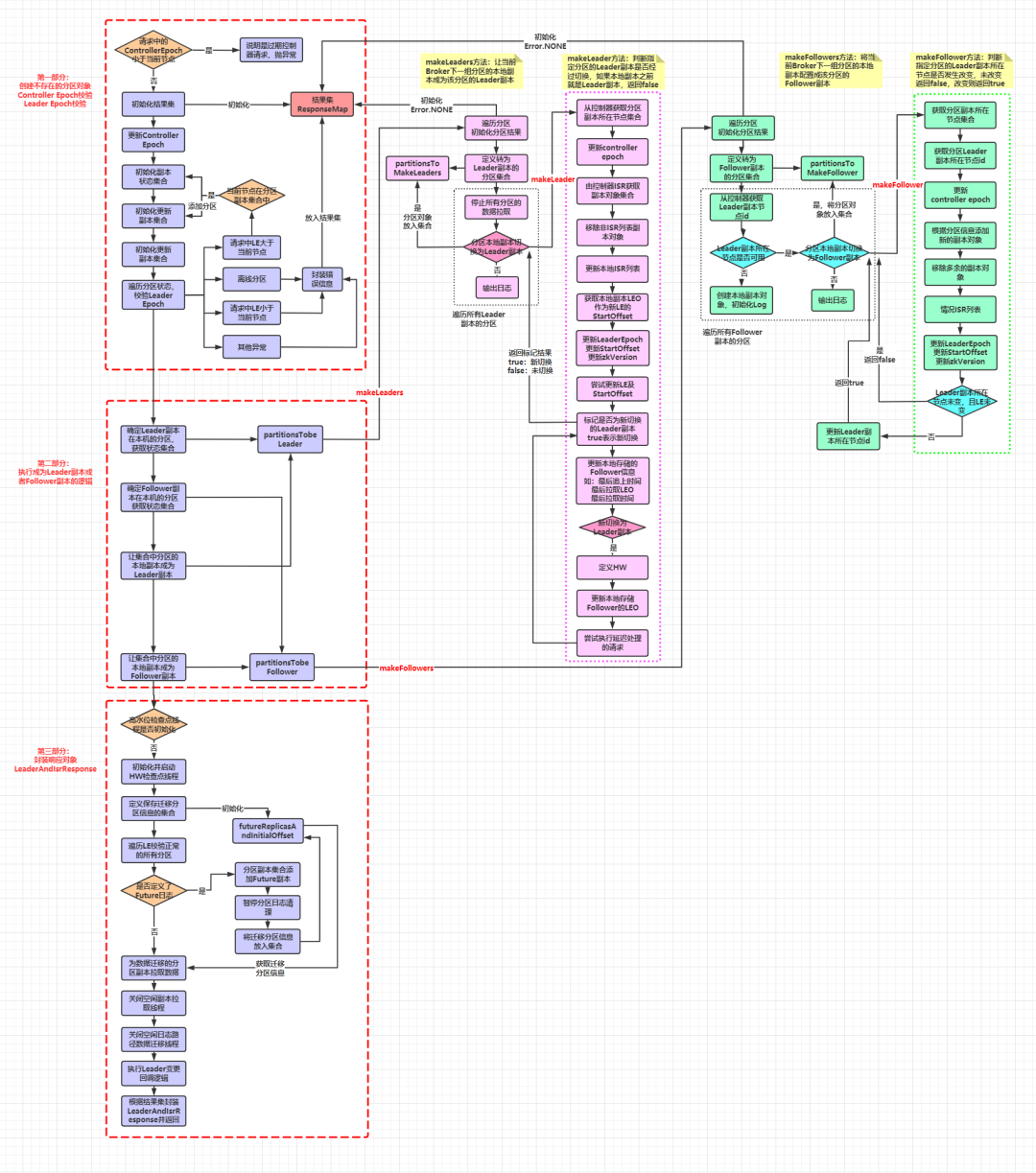
Leader 副本和 Follower 副本的角色并不是固定不变的,如果 Leader 所在的节点发生宕机,那么之前的 Follower 副本可能会被选为 Leader 副本,这些变更是通过 Controller 给 broker 发送 LeaderAndIsrRequest 请求来实现的。而 ReplicaManager 处理 LeaderAndIsrRequest 请求的方法为 becomeLeaderOrFollower() :
def becomeLeaderOrFollower(correlationId: Int,leaderAndIsrRequest: LeaderAndIsrRequest,onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): LeaderAndIsrResponse = {...replicaStateChangeLock synchronized {//如果leaderAndIsrRequest请求中携带的Controller Epoch小于当前节点的controllerEpoch,说明是过期Controller发送的请求if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from controller ${leaderAndIsrRequest.controllerId} with " +s"correlation id $correlationId since its controller epoch ${leaderAndIsrRequest.controllerEpoch} is old. " +s"Latest known controller epoch is $controllerEpoch")//抛出响应的异常leaderAndIsrRequest.getErrorResponse(0, Errors.STALE_CONTROLLER_EPOCH.exception)} else {//初始化一个结果集,保存分区和对应处理结果val responseMap = new mutable.HashMap[TopicPartition, Errors]//获取控制器节点的BrokerIdval controllerId = leaderAndIsrRequest.controllerId//更新当前的Controller Epoch 值controllerEpoch = leaderAndIsrRequest.controllerEpoch//定义存储分区信息的集合val partitionState = new mutable.HashMap[Partition, LeaderAndIsrRequest.PartitionState]()val updatedPartitions = new mutable.HashSet[Partition]// 遍历LeaderAndIsrRequest请求中的所有分区状态,进行Leader Epoch校验leaderAndIsrRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>// 从allPartitions中获取对应分区对象,如果没有则创建val partition = getOrCreatePartition(topicPartition)//获取当前分区对象的Leader Epochval currentLeaderEpoch = partition.getLeaderEpoch//获取请求中携带的Leader Epochval requestLeaderEpoch = stateInfo.basePartitionState.leaderEpoch//如果是离线分区,将该分区放入结果集,并封装一个KAFKA_STORAGE_ERROR错误if (partition eq ReplicaManager.OfflinePartition) {stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from " +s"controller $controllerId with correlation id $correlationId " +s"epoch $controllerEpoch for partition $topicPartition as the local replica for the " +"partition is in an offline log directory")responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)//如果请求中的Leader Epoch > 当前分区的Leader Epoch} else if (requestLeaderEpoch > currentLeaderEpoch) {//且分区的初始副本分配中包含当前节点if (stateInfo.basePartitionState.replicas.contains(localBrokerId)) {//将分区对象放入updatedPartitions集合updatedPartitions.add(partition)//将分区状态放入partitionState集合partitionState.put(partition, stateInfo)} else {stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from controller $controllerId with " +s"correlation id $correlationId epoch $controllerEpoch for partition $topicPartition as itself is not " +s"in assigned replica list ${stateInfo.basePartitionState.replicas.asScala.mkString(",")}")responseMap.put(topicPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION)}//如果请求中的Leader Epoch < 当前分区的Leader Epoch,说明是过期leader的请求} else if (requestLeaderEpoch < currentLeaderEpoch) {stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from " +s"controller $controllerId with correlation id $correlationId " +s"epoch $controllerEpoch for partition $topicPartition since its associated " +s"leader epoch $requestLeaderEpoch is smaller than the current " +s"leader epoch $currentLeaderEpoch")//将该分区放入结果集,并封装一个STALE_CONTROLLER_EPOCH错误responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)} else {stateChangeLogger.debug(s"Ignoring LeaderAndIsr request from " +s"controller $controllerId with correlation id $correlationId " +s"epoch $controllerEpoch for partition $topicPartition since its associated " +s"leader epoch $requestLeaderEpoch matches the current leader epoch")//将该分区放入结果集,并封装一个STALE_CONTROLLER_EPOCH错误responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)}}// 确定Broker上副本是哪些分区的Leader副本val partitionsTobeLeader = partitionState.filter { case (_, stateInfo) =>stateInfo.basePartitionState.leader == localBrokerId}// 确定Broker上副本是哪些分区的Follower副本val partitionsToBeFollower = partitionState -- partitionsTobeLeader.keys//为partitionsTobeLeader集合中的所有分区在本机的副本执行成为Leader的操作,调用makeLeaders方法val partitionsBecomeLeader = if (partitionsTobeLeader.nonEmpty)makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, correlationId, responseMap)elseSet.empty[Partition]//为partitionsToBeFollower集合中的所有分区在本机的副本执行成为Follower的操作,调用makeFollowers方法val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap)elseSet.empty[Partition]//遍历请求中的所有分区leaderAndIsrRequest.partitionStates.asScala.keys.foreach { topicPartition =>/** 如果指定了一个离线的分区路径,那么通过getOrCreatePartition方法创建分区的本地副本抛出异常之前,getOrCreatePartition方法* 可能已经创建了一个对应的分区对象了,这时在allPartitions对象池中,就会添加一个Partition对象为空的TopicPartition,* 这里将这个空的Partition对象修改为OfflinePartition*/if (localReplica(topicPartition).isEmpty && (allPartitions.get(topicPartition) ne ReplicaManager.OfflinePartition))//如果当前节点没有指定分区的本地副本,且该分区的状态为离线状态,则更新该分区为离线分区allPartitions.put(topicPartition, ReplicaManager.OfflinePartition)}if (!hwThreadInitialized) {// 启动高水位检查点专属线程// 定期将Broker上所有非Offline分区的高水位值写入到检查点文件,默认每5秒执行1次startHighWaterMarksCheckPointThread()hwThreadInitialized = true}val futureReplicasAndInitialOffset = new mutable.HashMap[TopicPartition, InitialFetchState]//遍历前面Leader Epoch校验正常的分区,看是否需要做副本迁移for (partition <- updatedPartitions) {val topicPartition = partition.topicPartition//如果已经定义了指定分区对应的Future日志对象// 这里用于做副本迁移,当用户希望将副本从一个目录迁移到另一个目录时,会将迁移后的目录定义为-future后缀的目录//然后在该目录下创建future日志,当future日志追上current日志时,来替换当前分区的日志if (logManager.getLog(topicPartition, isFuture = true).isDefined) {partition.localReplica.foreach { replica =>val leader = BrokerEndPoint(config.brokerId, "localhost", -1)partition.getOrCreateReplica(Request.FutureLocalReplicaId, isNew = false)logManager.abortAndPauseCleaning(topicPartition)futureReplicasAndInitialOffset.put(topicPartition, InitialFetchState(leader,partition.getLeaderEpoch, replica.highWatermark.messageOffset))}}}//副本修改日志路径管理器拉取指定分区的数据到future副本replicaAlterLogDirsManager.addFetcherForPartitions(futureReplicasAndInitialOffset)// 关闭空闲副本拉取线程replicaFetcherManager.shutdownIdleFetcherThreads()// 关闭空闲日志路径数据迁移线程replicaAlterLogDirsManager.shutdownIdleFetcherThreads()// 执行Leader变更之后的回调逻辑onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)//封装LeaderAndIsrResponse响应new LeaderAndIsrResponse(Errors.NONE, responseMap.asJava)}}}
这个方法代码相对较多,可以分成三个部分来看
进行Controller Epoch校验,遍历请求中的分区,创建对应的Partition分区对象,进行Leader Epoch校验
执行让当前Broker上的本地副本成为Leader副本或者Follower副本的逻辑
进行扫尾工作并封装LeaderAndIsrResponse响应返回
第一部分:
if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {...//抛出响应的异常leaderAndIsrRequest.getErrorResponse(0, Errors.STALE_CONTROLLER_EPOCH.exception)}
//初始化一个结果集,保存分区和对应处理结果val responseMap = new mutable.HashMap[TopicPartition, Errors]
//获取控制器节点的BrokerIdval controllerId = leaderAndIsrRequest.controllerId//更新当前的Controller Epoch 值controllerEpoch = leaderAndIsrRequest.controllerEpoch
//定义存储分区信息的集合val partitionState = new mutable.HashMap[Partition, LeaderAndIsrRequest.PartitionState]()//定义Leader Epoch校验通过的分区集合val updatedPartitions = new mutable.HashSet[Partition]
// 遍历LeaderAndIsrRequest请求中的所有分区状态,进行Leader Epoch校验leaderAndIsrRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>// 从allPartitions中获取对应分区对象,如果没有则创建val partition = getOrCreatePartition(topicPartition)//获取当前分区对象的Leader Epochval currentLeaderEpoch = partition.getLeaderEpoch//获取请求中携带的Leader Epochval requestLeaderEpoch = stateInfo.basePartitionState.leaderEpoch//如果是离线分区,将该分区放入结果集,并封装一个KAFKA_STORAGE_ERROR错误if (partition eq ReplicaManager.OfflinePartition) {...responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)//如果请求中的Leader Epoch > 当前分区的Leader Epoch} else if (requestLeaderEpoch > currentLeaderEpoch) {//且分区的初始副本分配中包含当前节点if (stateInfo.basePartitionState.replicas.contains(localBrokerId)) {//将分区对象放入updatedPartitions集合updatedPartitions.add(partition)//将分区状态放入partitionState集合partitionState.put(partition, stateInfo)} else {...responseMap.put(topicPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION)}//如果请求中的Leader Epoch < 当前分区的Leader Epoch,说明是过期leader的请求} else if (requestLeaderEpoch < currentLeaderEpoch) {...//将该分区放入结果集,并封装一个STALE_CONTROLLER_EPOCH错误responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)} else {...//将该分区放入结果集,并封装一个STALE_CONTROLLER_EPOCH错误responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)}}
第二部分:
a. 确定Broker上的本地副本是哪些分区的Leader副本,判断条件:请求分区信息中Leader副本的节点id = 当前broker节点id
// 确定Broker上的本地副本是哪些分区的Leader副本val partitionsTobeLeader = partitionState.filter { case (_, stateInfo) =>stateInfo.basePartitionState.leader == localBrokerId}
// 确定Broker上的本地副本是哪些分区的Follower副本val partitionsToBeFollower = partitionState -- partitionsTobeLeader.keys
//为partitionsTobeLeader集合中的所有分区在本机的副本执行成为Leader的操作,调用makeLeaders方法val partitionsBecomeLeader = if (partitionsTobeLeader.nonEmpty)makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, correlationId, responseMap)elseSet.empty[Partition]
//为partitionsToBeFollower集合中的所有分区在本机的副本执行成为Follower的操作,调用makeFollowers方法val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap)elseSet.empty[Partition]
下面重点分析一下 makeLeaders 方法和 makeFollowers 方法
private def makeLeaders(controllerId: Int,//控制器所在节点IDepoch: Int,//控制器纪元值partitionState: Map[Partition, LeaderAndIsrRequest.PartitionState],//要成为Leader副本的分区信息集合correlationId: Int,//responseMap: mutable.Map[TopicPartition, Errors]//按照分区分组的错误信息): Set[Partition] = {partitionState.keys.foreach { partition =>...}//遍历要成为Leader副本的分区信息集合for (partition <- partitionState.keys)//初始化分区结果,给每个分区添加Errors.NONE信息responseMap.put(partition.topicPartition, Errors.NONE)//定义一个集合用于存储本地副本成为Leader副本的分区对象val partitionsToMakeLeaders = mutable.Set[Partition]()try {//停止本地副本请要成为Leader副本的所有分区的数据拉取replicaFetcherManager.removeFetcherForPartitions(partitionState.keySet.map(_.topicPartition))//遍历更新所有要成为Leader副本的分区的分区信息partitionState.foreach{ case (partition, partitionStateInfo) =>try {//判断指定分区在本地的副本之前是否为Leader副本,如果之前就是Leader副本,makeLeader方法返回false,否则返回true,执行分支内容if (partition.makeLeader(controllerId, partitionStateInfo, correlationId)) {//将该副本对象放入集合partitionsToMakeLeaders += partition...} else...} catch {case e: KafkaStorageException =>...val dirOpt = getLogDir(partition.topicPartition)error(s"Error while making broker the leader for partition $partition in dir $dirOpt", e)// 把KAFKA_SOTRAGE_ERRROR异常封装到Response中responseMap.put(partition.topicPartition, Errors.KAFKA_STORAGE_ERROR)}}} catch {case e: Throwable =>...throw e}partitionState.keys.foreach { partition =>...}partitionsToMakeLeaders}
给每个分区封装一个没有错误的结果放入结果集
定义一个集合用于存储本地副本成为 Leader 副本的分区对象
停止本地副本请要成为 Leader 副本的所有分区的数据拉取
遍历要成为 Leader 副本的分区集合,判断这个分区的本地副本是否之前就是 Leader 副本,如果不是,将该分区对象放入步骤 2 创建的集合
如果过程中发生异常,根据异常信息更新结果集中对应分区的结果
其中判断给定分区的本地副本是否之前就是 Leader 副本是通过 Partition.makeLeader() 方法实现的。如果之前就是 Leader 副本,返回false;如果不在,返回true。makeLeader() 方法的逻辑如下:
def makeLeader(controllerId: Int, partitionStateInfo: LeaderAndIsrRequest.PartitionState, correlationId: Int): Boolean = {val (leaderHWIncremented, isNewLeader) = inWriteLock(leaderIsrUpdateLock) {//获取控制器发来的分区副本所在节点的集合val newAssignedReplicas = partitionStateInfo.basePartitionState.replicas.asScala.map(_.toInt)//更新controller epochcontrollerEpoch = partitionStateInfo.basePartitionState.controllerEpoch// add replicas that are new//根据控制器发来的ISR列表获取对应的副本对象集合val newInSyncReplicas = partitionStateInfo.basePartitionState.isr.asScala.map(r => getOrCreateReplica(r, partitionStateInfo.isNew)).toSet//移除本地保存的不在控制器发来的ISR列表中的副本对象(assignedReplicas.map(_.brokerId) -- newAssignedReplicas).foreach(removeReplica)//更新本地 ISR 列表inSyncReplicas = newInSyncReplicasnewAssignedReplicas.foreach(id => getOrCreateReplica(id, partitionStateInfo.isNew))//获取本地副本对象val leaderReplica = localReplicaOrException//将本地副本对象的LEO作为新的Leader Epoch的StartOffsetval leaderEpochStartOffset = leaderReplica.logEndOffsetinfo(s"$topicPartition starts at Leader Epoch ${partitionStateInfo.basePartitionState.leaderEpoch} from " +s"offset $leaderEpochStartOffset. Previous Leader Epoch was: $leaderEpoch")//更新Leader EpochleaderEpoch = partitionStateInfo.basePartitionState.leaderEpoch//更新Leader Epoch 对应的startOffsetleaderEpochStartOffsetOpt = Some(leaderEpochStartOffset)//更新zkVersionzkVersion = partitionStateInfo.basePartitionState.zkVersion// 尝试更新Leader Epoch和对应的StartOffsetleaderReplica.log.foreach { log =>log.maybeAssignEpochStartOffset(leaderEpoch, leaderEpochStartOffset)}//标记将要称为Leader的副本是否是新转换成Leader副本的//如果leaderReplicaIdOpt为当前节点id,说明不是新转换成的,该分区之前的Leader副本就在当前节点上val isNewLeader = !leaderReplicaIdOpt.contains(localBrokerId)//获取当前Leader副本的LEOval curLeaderLogEndOffset = leaderReplica.logEndOffsetval curTimeMs = time.milliseconds//遍历当前节点保存的所有的Follower副本对象(assignedReplicas - leaderReplica).foreach { replica =>val lastCaughtUpTimeMs = if (inSyncReplicas.contains(replica)) curTimeMs else 0L//更新所有Follower副本对象的_lastCaughtUpTimeMs/lastFetchLeaderLogEndOffset/lastFetchTimeMsreplica.resetLastCaughtUpTime(curLeaderLogEndOffset, curTimeMs, lastCaughtUpTimeMs)}if (isNewLeader) {//定义Leader副本的HWleaderReplica.convertHWToLocalOffsetMetadata()//更新Leader副本的id为当前broker的idleaderReplicaIdOpt = Some(localBrokerId)//更新本地存储的所有Follower副本的LEOassignedReplicas.filter(_.brokerId != localBrokerId).foreach(_.updateLogReadResult(LogReadResult.UnknownLogReadResult))}(maybeIncrementLeaderHW(leaderReplica), isNewLeader)}//如果HW修改了,尝试执行之前延迟处理的请求if (leaderHWIncremented)tryCompleteDelayedRequests()isNewLeader}
val newAssignedReplicas = partitionStateInfo.basePartitionState.replicas.asScala.map(_.toInt)
controllerEpoch = partitionStateInfo.basePartitionState.controllerEpoch
③根据控制器发来的 ISR 列表获取对应的副本对象集合。Partition对象中保存了该分区的所有副本对象,本地副本为 localReplica ,其他节点的副本为 remoteReplica,其中只有本地副本存在对应的日志文件
val newInSyncReplicas = partitionStateInfo.basePartitionState.isr.asScala.map(r => getOrCreateReplica(r, partitionStateInfo.isNew)).toSet
④移除本地保存的不在控制器发来的ISR列表中的副本对象。假设该分区有3个副本,原来保存在[0,1,2]三个节点上,如果控制器请求中ISR列表变成了[1,2,3],则需要将原来节点0对应的副本对象移除
(assignedReplicas.map(_.brokerId) -- newAssignedReplicas).foreach(removeReplica)
inSyncReplicas = newInSyncReplicas
⑥根据控制器提供的副本所在节点创建对应的副本对象。这个是为了创建那些不在ISR列表中的副本对象,比如分区有3个副本,但控制器发送请求时只有2个在ISR列表,那个不在ISR列表中的副本对象也需要被创建
newAssignedReplicas.foreach(id => getOrCreateReplica(id, partitionStateInfo.isNew))
//获取本地副本对象val leaderReplica = localReplicaOrException//将本地副本对象的LEO作为新的Leader Epoch的StartOffsetval leaderEpochStartOffset = leaderReplica.logEndOffset
//更新Leader EpochleaderEpoch = partitionStateInfo.basePartitionState.leaderEpoch//更新Leader Epoch 对应的startOffsetleaderEpochStartOffsetOpt = Some(leaderEpochStartOffset)//更新zkVersionzkVersion = partitionStateInfo.basePartitionState.zkVersion// 尝试更新Log日志对象的Leader Epoch和对应的StartOffsetleaderReplica.log.foreach { log =>log.maybeAssignEpochStartOffset(leaderEpoch, leaderEpochStartOffset)}
//标记将要称为Leader的副本是否是新转换成Leader副本的//如果leaderReplicaIdOpt为当前节点id,说明不是新转换成的,该分区之前的Leader副本就在当前节点上val isNewLeader = !leaderReplicaIdOpt.contains(localBrokerId)
//获取当前Leader副本的LEOval curLeaderLogEndOffset = leaderReplica.logEndOffsetval curTimeMs = time.milliseconds//遍历当前节点保存的所有的Follower副本对象(assignedReplicas - leaderReplica).foreach { replica =>val lastCaughtUpTimeMs = if (inSyncReplicas.contains(replica)) curTimeMs else 0L//更新所有Follower副本对象的_lastCaughtUpTimeMs/lastFetchLeaderLogEndOffset/lastFetchTimeMsreplica.resetLastCaughtUpTime(curLeaderLogEndOffset, curTimeMs, lastCaughtUpTimeMs)}
⑾如果分区的Leader副本之前不在当前节点,则定义Leader副本的HW,并更新本地存储的所有Follower副本对象的LEO值
if (isNewLeader) {//定义Leader副本的HWleaderReplica.convertHWToLocalOffsetMetadata()// mark local replica as the leader after converting hw//更新Leader副本的id为当前broker的idleaderReplicaIdOpt = Some(localBrokerId)// reset log end offset for remote replicas//更新本地存储的所有Follower副本的LEOassignedReplicas.filter(_.brokerId != localBrokerId).foreach(_.updateLogReadResult(LogReadResult.UnknownLogReadResult))}
⑿如果提高了HW值,尝试处理之前未处理的延时请求
if (leaderHWIncremented)tryCompleteDelayedRequests()
⒀返回标记值
private def makeFollowers(controllerId: Int,epoch: Int,partitionStates: Map[Partition, LeaderAndIsrRequest.PartitionState],correlationId: Int,responseMap: mutable.Map[TopicPartition, Errors]) : Set[Partition] = {partitionStates.foreach { case (partition, partitionState) =>...}//遍历所有分区,将分区的异常类型初始化为Errors.NONEfor (partition <- partitionStates.keys)responseMap.put(partition.topicPartition, Errors.NONE)//定义一个集合,用于存放在当前节点上本地副本变更为Follower副本的分区val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()try {partitionStates.foreach { case (partition, partitionStateInfo) =>//获取控制器发来的分区Leader副本的brokerIdval newLeaderBrokerId = partitionStateInfo.basePartitionState.leadertry {metadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match {//在元数据缓存中找到Leader副本的节点信息case Some(_) =>//如果给定分区的本地副本是转换成Follower副本的,makeFollower返回true,并执行一些列操作if (partition.makeFollower(controllerId, partitionStateInfo, correlationId))//将副本对象添加到本地副本新转换成Follower副本的集合partitionsToMakeFollower += partitionelse...//如果元数据缓存中没有指定Leader副本所在节点的信息,说明Leader副本所在的节点不可用case None =>...//创建一个本地副本对象,初始化日志对象partition.getOrCreateReplica(localBrokerId, isNew = partitionStateInfo.isNew)}} catch {case e: KafkaStorageException =>...val dirOpt = getLogDir(partition.topicPartition)...responseMap.put(partition.topicPartition, Errors.KAFKA_STORAGE_ERROR)}}//关闭现有的Fetcher线程replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))partitionsToMakeFollower.foreach { partition =>...}//遍历本地副本成为Follower副本的分区,尝试完成延迟请求partitionsToMakeFollower.foreach { partition =>val topicPartitionOperationKey = new TopicPartitionOperationKey(partition.topicPartition)tryCompleteDelayedProduce(topicPartitionOperationKey)tryCompleteDelayedFetch(topicPartitionOperationKey)}partitionsToMakeFollower.foreach { partition =>...}if (isShuttingDown.get()) {partitionsToMakeFollower.foreach { partition =>...}}else {val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>//找到分区Leader副本所在节点idval leader = metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get.brokerEndPoint(config.interBrokerListenerName)//获取要拉取数据的起始偏移量val fetchOffset = partition.localReplicaOrException.highWatermark.messageOffsetpartition.topicPartition -> InitialFetchState(leader, partition.getLeaderEpoch, fetchOffset)}.toMap//TODO 添加新的拉取线程,让Follower Replica 去Leader Replica 拉取数据replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)partitionsToMakeFollower.foreach { partition =>...}}} catch {case e: Throwable =>...throw e}partitionStates.keys.foreach { partition =>...}partitionsToMakeFollower}
给每个分区封装一个没有错误的结果放入结果集 定义一个集合,用于存放当前节点上本地副本变更为Follower副本的分区 遍历要成为 Follower 副本的分区,获取控制器中对应分区 Leader 副本的节点id,然后在当前节点的元数据缓存中查找该 Leader 副本的节点信息 如果元数据缓存中有该节点信息,说明 Leader 副本可用。判断该分区的本地副本之前是否为 Follower 副本,如果不是,说明是切换为 Follower 副本的,将该分区添加到步骤2创建的集合中 如果元数据缓存中没有该节点信息,说明 Leader 副本不可用。此时创建一个分区对应的本地副本,初始化一些列对应的文件 如果过程中发送异常,根据异常信息更新结果集中对应分区的结果 关闭所有切换为 Follower 副本的分区的数据拉取线程 遍历切换为 Follower 副本的分区,尝试完成延时请求 如果ReplicaManager未关闭,遍历所有切换为 Follower 副本的分区,找到其 Leader 副本所在的节点,获取拉取数据的起始偏移量,然后启动新的数据拉取线程去 Leader 副本拉取数据
def makeFollower(controllerId: Int, partitionStateInfo: LeaderAndIsrRequest.PartitionState, correlationId: Int): Boolean = {inWriteLock(leaderIsrUpdateLock) {//获取控制器发来的分区所有副本所在节点的brokerId集合val newAssignedReplicas = partitionStateInfo.basePartitionState.replicas.asScala.map(_.toInt)//获取分区Leader副本的节点idval newLeaderBrokerId = partitionStateInfo.basePartitionState.leader//获取当前分区的Leader Epochval oldLeaderEpoch = leaderEpoch//更新controller epochcontrollerEpoch = partitionStateInfo.basePartitionState.controllerEpoch//创建控制器分配的所有副本对象newAssignedReplicas.foreach(r => getOrCreateReplica(r, partitionStateInfo.isNew))//移除多余的副本对象(假设之前副本在0,1,2节点上,现在控制器要求副本在1,2,3节点上,那么就移除本地存储的节点0对应的副本对象)(assignedReplicas.map(_.brokerId) -- newAssignedReplicas).foreach(removeReplica)//清空ISR列表inSyncReplicas = Set.empty[Replica]//更新Leader EpochleaderEpoch = partitionStateInfo.basePartitionState.leaderEpoch//更新Leader Epoch对应的StartOffsetleaderEpochStartOffsetOpt = None//更新zkVersionzkVersion = partitionStateInfo.basePartitionState.zkVersion//如果控制器分配的Leader副本就是之前的Leader副本,且Leader Epoch没有改变,说明Leader副本没有切换,那么返回false// 否则更新leaderReplicaIdOpt信息,返回trueif (leaderReplicaIdOpt.contains(newLeaderBrokerId) && leaderEpoch == oldLeaderEpoch) {false} else {leaderReplicaIdOpt = Some(newLeaderBrokerId)true}}}
这个方法的流程相对简单,已经加了注释,就不逐步分析了。这里需要注意一个点:如果本地副本为 Follower 副本,那么会清空 ISR 列表,即本地副本为 Follower 副本的分区对象中不存储 ISR 列表信息,只有本地副本为 Leader 副本的分区对象才会存储 ISR 列表信息。
第三部分:
if (!hwThreadInitialized) {// 启动高水位检查点线程// 定期将Broker上所有非Offline分区的高水位值写入到检查点文件,默认每5秒执行1次startHighWaterMarksCheckPointThread()hwThreadInitialized = true}val futureReplicasAndInitialOffset = new mutable.HashMap[TopicPartition, InitialFetchState]//遍历前面Leader Epoch校验正常的分区,看是否需要做副本迁移for (partition <- updatedPartitions) {val topicPartition = partition.topicPartition//如果已经定义了指定分区对应的Future日志对象// 这里用于做副本迁移,当用户希望将副本从一个目录迁移到另一个目录时,会将迁移后的目录定义为-future后缀的目录//然后在该目录下创建future日志,当future日志追上current日志时,来替换当前分区的日志if (logManager.getLog(topicPartition, isFuture = true).isDefined) {partition.localReplica.foreach { replica =>val leader = BrokerEndPoint(config.brokerId, "localhost", -1)//在分区的副本集合中添加Future副本partition.getOrCreateReplica(Request.FutureLocalReplicaId, isNew = false)//暂停分区日志的清理logManager.abortAndPauseCleaning(topicPartition)futureReplicasAndInitialOffset.put(topicPartition, InitialFetchState(leader,partition.getLeaderEpoch, replica.highWatermark.messageOffset))}}}//对指定的分区进行日志数据的迁移replicaAlterLogDirsManager.addFetcherForPartitions(futureReplicasAndInitialOffset)// 关闭空闲副本拉取线程replicaFetcherManager.shutdownIdleFetcherThreads()// 关闭空闲日志路径数据迁移线程replicaAlterLogDirsManager.shutdownIdleFetcherThreads()// 执行Leader变更之后的回调逻辑onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)//封装LeaderAndIsrResponse响应new LeaderAndIsrResponse(Errors.NONE, responseMap.asJava)}
启动高水位检查点线程,定期将所有非离线分区的高水位值写入检查点文件 遍历Leader Epoch校验正常的分区,看是否需要进行副本迁移(就是本地副本对应日志文件的迁移),判断依据是该分区是否定义了 Future 日志对象。如果需要进行副本迁移,则在指定分区的副本集合中增加Future 副本对象,然后暂停分区的日志清理。 对指定的分区进行日志数据的迁移 关闭空闲副本拉取线程 关闭空闲日志路径数据迁移线程 执行 Leader 副本变更之后的回调逻辑 封装 LeaderAndIsrResponse 响应并返回
ReplicaManager 管理了节点上的所有分区对象,而分区对象中管理了下面的一组副本对象。ReplicaManager 通过对分区对象的直接管理实现对副本对象的间接管理 副本读写数据的操作由 ReplicaManager 管理 副本状态的切换是由控制器发送 LeaderAndISRRequest 请求来管理的 执行副本状态的切换是在 ReplicaManager 的 becomeLeaderOrFollower 方法中进行的 切换为 Leader 副本的逻辑通过 ReplicaManager 的 makeLeaders 方法实现 切换为 Follower 副本的逻辑通过 ReplicaManager 的 makeFollowers 方法实现 只有本地副本为 Leader 副本的分区对象会保存 ISR 列表信息,本地副本为 Follower 副本的分区对象是不存储 ISR 列表信息的
