




二、图示说明
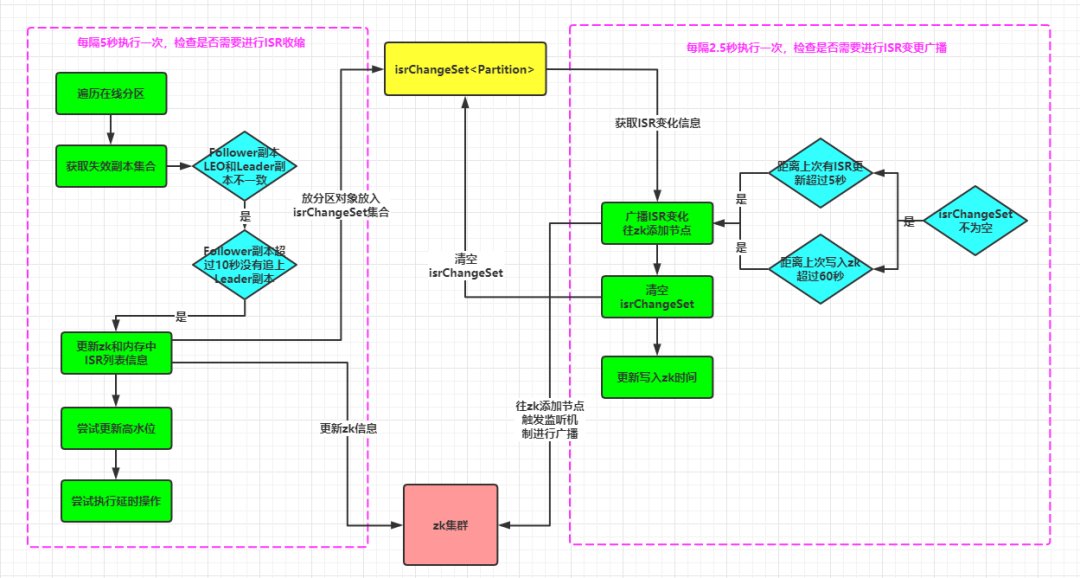
ISR 相关的定时任务
在 ReplicaManager 副本管理器启动时,会启动两个和 ISR 有关的定时任务线程:"isr-expiration" 和"isr-change-propagation"。相关的代码在ReplicaManager.startup() 方法中:
def startup() {//由参数 replica.lag.time.max.ms 配置,默认为10秒scheduler.schedule("isr-expiration", maybeShrinkIsr _, period = config.replicaLagTimeMaxMs 2, unit = TimeUnit.MILLISECONDS)scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges _, period = 2500L, unit = TimeUnit.MILLISECONDS)...}
isr-expiration:ISR 定时检查任务,检查ISR列表是否进行收缩。其执行周期为 config.replicaLagTimeMaxMs 2,其中config.replicaLagTimeMaxMs是服务端参数 replica.lag.time.max.ms 的值,默认为10秒,所以该任务的周期为:10/2 = 5 秒。
isr-change-propagation :ISR 定时广播任务,将ISR列表的收缩广播给其他节点。其执行周期默认为 2500L ,即2.5秒。
isr-expiration定时检查任务的内容,在maybeShrinkIsr方法中:
private def maybeShrinkIsr(): Unit = {trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR")//遍历ReplicaManager管理的所有在线的Partition对象,检查是否需要缩小ISR列表allPartitions.keys.foreach { topicPartition =>nonOfflinePartition(topicPartition).foreach(_.maybeShrinkIsr(config.replicaLagTimeMaxMs))}}
该方法会遍历ReplicaManager管理的所有在线的Partition对象,调用其maybeShrinkIsr方法。maybeShrinkIsr方法逻辑如下,可以归纳为四个步骤:
获取失效副本集合
更新zk节点和内存中的 ISR 列表信息
尝试更新 HW
尝试执行所有的延时操作
def maybeShrinkIsr(replicaMaxLagTimeMs: Long) {val leaderHWIncremented = inWriteLock(leaderIsrUpdateLock) {leaderReplicaIfLocal match {//如果是本地Leader副本case Some(leaderReplica) =>//获取要被移除出去的Replica集合val outOfSyncReplicas = getOutOfSyncReplicas(leaderReplica, replicaMaxLagTimeMs)if (outOfSyncReplicas.nonEmpty) {//构建一个新的ISR列表,将要移除的Replica集合从原ISR列表移除val newInSyncReplicas = inSyncReplicas -- outOfSyncReplicasassert(newInSyncReplicas.nonEmpty)info("Shrinking ISR from %s to %s. Leader: (highWatermark: %d, endOffset: %d). Out of sync replicas: %s.".format(inSyncReplicas.map(_.brokerId).mkString(","),newInSyncReplicas.map(_.brokerId).mkString(","),leaderReplica.highWatermark.messageOffset,leaderReplica.logEndOffset,outOfSyncReplicas.map { replica =>s"(brokerId: ${replica.brokerId}, endOffset: ${replica.logEndOffset})"}.mkString(" ")))//更新zk上和缓存中的ISR列表updateIsr(newInSyncReplicas)replicaManager.isrShrinkRate.mark()//尝试更新HW高水位值maybeIncrementLeaderHW(leaderReplica)} else {false}case None => false // 什么都不做}}//如果 HW 进行了修改if (leaderHWIncremented)//尝试完成所有延迟的请求tryCompleteDelayedRequests()}
第一步:调用getOutOfSyncReplicas方法获取失效副本的集合:
//获取失效的Replica集合val outOfSyncReplicas = getOutOfSyncReplicas(leaderReplica, replicaMaxLagTimeMs)
getOutOfSyncReplicas方法就包含了判定失效副本的条件:
def getOutOfSyncReplicas(leaderReplica: Replica, maxLagMs: Long): Set[Replica] = {//获取除Leader副本之外的其他副本集合val candidateReplicas = inSyncReplicas - leaderReplica//过滤失效的副本//失效副本判定条件:// 1.r.logEndOffset != leaderReplica.logEndOffset:该副本的LEO 不等于 Leader 副本的LEO// 2.(time.milliseconds - r.lastCaughtUpTimeMs) > maxLagMs (当前时间 - Follower副本最后一次追上Leader副本的时间) > 最大的延迟时间//如果一个Replica长时间(10秒)没有发送请求到Leader 副本同步数据val laggingReplicas = candidateReplicas.filter(r =>r.logEndOffset != leaderReplica.logEndOffset && (time.milliseconds - r.lastCaughtUpTimeMs) > maxLagMs)if (laggingReplicas.nonEmpty)debug("Lagging replicas are %s".format(laggingReplicas.map(_.brokerId).mkString(",")))laggingReplicas}
失效副本的判定条件:
Follower 副本的LEO 值不等于 Leader 副本的 LEO 值 当前时间 - Follower副本最后一次追上Leader副本的时间 > 10 秒
def updateLogReadResult(logReadResult: LogReadResult) {//更新最后一次追上Leader副本的时间 _lastCaughtUpTimeMs// 如果拉取结果的最大偏移量>=当前leader副本的LEO,也就是拉取到了小于LEO的所有数据,则更新_lastCaughtUpTimeMs为 max(_lastCaughtUpTimeMs,拉取到数据的时间)if (logReadResult.info.fetchOffsetMetadata.messageOffset >= logReadResult.leaderLogEndOffset)_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, logReadResult.fetchTimeMs)//如果拉取结果的最大偏移量>=上一次拉取时Leader副本的LEO,这表示Follower副本当前还没追上Leader副本// 这时更新_lastCaughtUpTimeMs为 max(_lastCaughtUpTimeMs,上一次拉取数据的时间)else if (logReadResult.info.fetchOffsetMetadata.messageOffset >= lastFetchLeaderLogEndOffset)_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, lastFetchTimeMs)//更新Follower副本的日志起始偏移量,即 _logStartOffset 变量logStartOffset = logReadResult.followerLogStartOffset//更新Follower副本的LEO元数据对象,即 _logEndOffsetMetadata 变量logEndOffsetMetadata = logReadResult.info.fetchOffsetMetadata//更新最后一次拉取时Leader副本的LEOlastFetchLeaderLogEndOffset = logReadResult.leaderLogEndOffset//更新最后一次拉取数据的时间为从leader副本拉取到数据的时间lastFetchTimeMs = logReadResult.fetchTimeMs}
如果当前拉取数据的请求拉取到了Leader副本小于LEO的所有数据,即追上了Leader副本,则更新 _lastCaughtUpTimeMs 为本次拉取到数据的时间
如果当前拉取数据的请求没有追上Leader副本,则更新 _lastCaughtUpTimeMs 为上一次追上Leader副本的拉取时间
从这里可以知道,并不是只要拉取数据就会更新 _lastCaughtUpTimeMs 。如果Leader副本写入数据的速度大于Follower副本拉取数据的速度,Follower副本迟迟追不上Leader副本,当Leader副本故障将Follower副本切换为Leader副本后,就会发生严重的数据丢失问题。所以对于迟迟追不上Ledaer副本的Follower副本要被标记为失效副本,将其剔除出ISR列表。
第二步:如果存在失效副本,则更新 zk 节点上和内存中 ISR 的列表信息。
if (outOfSyncReplicas.nonEmpty) {//构建一个新的ISR列表,是原始ISR列表剔除失效副本的结果val newInSyncReplicas = inSyncReplicas -- outOfSyncReplicas...更新zk上和缓存中的ISR列表updateIsr(newInSyncReplicas)replicaManager.isrShrinkRate.mark()
真正进行ISR列表更新的是updateIsr()方法。该方法会将ISR列表的更新信息更新到zookeeper中分区对应的节点上,只有zk更新成功了才会更新内存中的ISR列表对应的 inSyncReplicas 变量。并且会将更新成功的分区对象添加到 isrChangeSet 集合,之后让定时广播任务进行ISR列表变更信息的广播。
private def updateIsr(newIsr: Set[Replica]) {//封装一个对象,包含 当前节点id,当前leaderepoch值,新的ISR列表中副本所在节点编号集合,zk版本号val newLeaderAndIsr = new LeaderAndIsr(localBrokerId, leaderEpoch, newIsr.map(_.brokerId).toList, zkVersion)//更新ZK上指定分区的节点数据,返回两个对象://1.updateSucceeded:标识是否更新成功//2.新的版本号val (updateSucceeded, newVersion) = ReplicationUtils.updateLeaderAndIsr(zkClient, topicPartition, newLeaderAndIsr,controllerEpoch)//如果更新成功if (updateSucceeded) {//将该分区添加到isrChangeSet集合replicaManager.recordIsrChange(topicPartition)//更新ISR列表,注意这里只有在zk写成功后才会更改原来的ISR列表inSyncReplicas = newIsr//更新zk版本号zkVersion = newVersiontrace("ISR updated to [%s] and zkVersion updated to [%d]".format(newIsr.mkString(","), zkVersion))} else {replicaManager.failedIsrUpdatesRate.mark()info("Cached zkVersion [%d] not equal to that in zookeeper, skip updating ISR".format(zkVersion))}}
这里再看一下updateLeaderAndIsr方法:该方法的作用是将 ISR 列表的变更信息更新到zk对应的节点上。这里节点的路径为:/brokers/topics/<topic>/partition/<partition>/state,对应的节点信息包括:
controller_epoch:当前控制器的epoch
leader:该分区 leader 副本所在的 BrokerID
version:版本号,目前默认为 1
leader_epoch:当前分区 leader 的纪元
isr:变更后的 ISR 列表,是 BrokerID 的集合
最后将这些信息拼接成一个字符串,如:{” controller epoch " :5, ” leader ”: 1,"version" :l,”leader epoch ” : 3,”isr": [1 , 2]}
//更新指定分区在zk节点上的数据def updateLeaderAndIsr(zkClient: KafkaZkClient, partition: TopicPartition, newLeaderAndIsr: LeaderAndIsr,controllerEpoch: Int): (Boolean, Int) = {debug(s"Updated ISR for $partition to ${newLeaderAndIsr.isr.mkString(",")}")//该分区在zk上的节点路径,/brokers/topics/<topic>/partition/<partition>/state 节点val path = TopicPartitionStateZNode.path(partition)//zk节点对应的数据,包含controller_epoch,leader,version,leader_epoch,isrval newLeaderData = TopicPartitionStateZNode.encode(LeaderIsrAndControllerEpoch(newLeaderAndIsr, controllerEpoch))// use the epoch of the controller that made the leadership decision, instead of the current controller epochval updatePersistentPath: (Boolean, Int) = zkClient.conditionalUpdatePath(path, newLeaderData,newLeaderAndIsr.zkVersion, Some(checkLeaderAndIsrZkData))//如果更新成功,返回(true,newVersion)updatePersistentPath}
//尝试更新HW高水位值maybeIncrementLeaderHW(leaderReplica)
第四步:尝试执行之前不满足条件的延时操作
//如果 HW 进行了修改if (leaderHWIncremented)//尝试完成所有延迟的请求tryCompleteDelayedRequests()
ISR 定时广播任务
在进行 ISR 列表伸缩后,ReplicaManager还需要将这个操作的结果同步给集群中的其他Broker,这个就是通过 ISR 定时广播任务来完成的。
注意:如果一个分区的副本被加入到 ISR 列表,也会将该分区放入 isrChangeSet 集合,即只要 ISR 列表有变化,无论加入副本还是剔除副本,都需要进行广播。
isr-change-propagation定时广播任务的内容,在maybePropagateIsrChanges 方法中:
def maybePropagateIsrChanges() {//获取当前时间val now = System.currentTimeMillis()isrChangeSet synchronized {//广播ISR变化的条件://1.isrChangeSet不为空,即有分区更新了ISR列表// 2.1 距离上一次isrChangeSet更新的时间已经超过5秒( 上一次isrChangeSet更新的时间 + 5秒 < 当前时间)// 2.2 距离上一次写入ZK的时间已经超过60秒//IsrChangePropagationBlackOut 默认 5秒;IsrChangePropagationInterval 默认 60秒if (isrChangeSet.nonEmpty &&(lastIsrChangeMs.get() + ReplicaManager.IsrChangePropagationBlackOut < now ||lastIsrPropagationMs.get() + ReplicaManager.IsrChangePropagationInterval < now)) {//广播ISR列表的变化zkClient.propagateIsrChanges(isrChangeSet)//清空isrChangeSet集合isrChangeSet.clear()//更新写入ZK的时间lastIsrPropagationMs.set(now)}}}
这里判断是否进行 ISR 列表广播的条件除了isrChangeSet 集合不为空,即有分区进行了 ISR 列表的变更外,还需满足以下两个条件之一:
距离上一次有 ISR 列表更新的时间已经超过 5秒
距离上一次写入zk的时间已经超过 60秒
为什么要加后面两个判断条件呢?这样做的目的是:避免频繁更新zk节点信息对Kafka控制器、其他Broker节点和zk集群的影响
如果满足了广播条件,则调用zkClient.propagateIsrChanges()方法进行变更 ISR 列表的广播:
def propagateIsrChanges(isrChangeSet: collection.Set[TopicPartition]): Unit = {//在ZK的/isr_change_notification路径下创建一个"isr_change_"+ 单调递增数的顺序持久节点,并将isrChangeSet的信息保存到这个节点/ 返回节点路径,如:/isr_change_notification/isr_change_0000000000val isrChangeNotificationPath: String = createSequentialPersistentPath(IsrChangeNotificationSequenceZNode.path(),IsrChangeNotificationSequenceZNode.encode(isrChangeSet))debug(s"Added $isrChangeNotificationPath for $isrChangeSet")}
propagateIsrChanges()方法会在zk的/isr_change_notification路径下创建一个"isr_change_"+ 单调递增数的顺序持久节点,如/isr_change_notification/isr_change_0000000000,并将isrChangeSet的信息保存到这个节点。
Kafka 控制器为/isr_change_notification 节点添加了一个 Watcher ,当这个节点中有子节点发生变化时会触发 Watcher 的动作,以此通知控制器更新相关元数据信息并向它管理的 broker 节点发送更新元数据的请求,最后删除/isr_change_notification 路径下已经处理过的节点。
广播完成后会清空 isrChangeSet 集合,并更新写入 zk 的时间,以便进行下次广播条件的判断。
1. Kafka每隔5秒会检查所有在线的分区是否存在失效副本,失效副本的判定条件为:
Follower 副本的 lEO 和 Leader 副本的 LEO 不一致
Follower 副本没有追上 Leader 副本的时间超过了 10秒
除此之外,如果一个分区增加了副本因子,那么新增加的副本在追上 Leader 副本之前也是处于失效状态的;如果一个Follower副本由于某些原因(比如宕机)而下线,之后又上线,那么在追上 Leader 副本之前也处于失效状态。
isrChangeSet 集合不为空,即有分区进行 ISR 列表的变更
距离上一次有 ISR 列表更改超过了 5秒;或者距离上一次写入zk超过了60秒
获取失效副本集合
更新zk节点和内存中的 ISR 列表信息
尝试更新 HW
尝试执行所有的延时操作
