




一、场景分析
在上一篇中,分析了基于 HW 同步带来数据丢失和数据不一致问题,以及如何通过引入 Leader Epoch 机制来解决这些问题。准确来讲,两者的区别主要在日志截断操作时,截断位置的确定上。这篇详细分析如何基于 Leader Epoch 进行日志截断。
二、图示说明
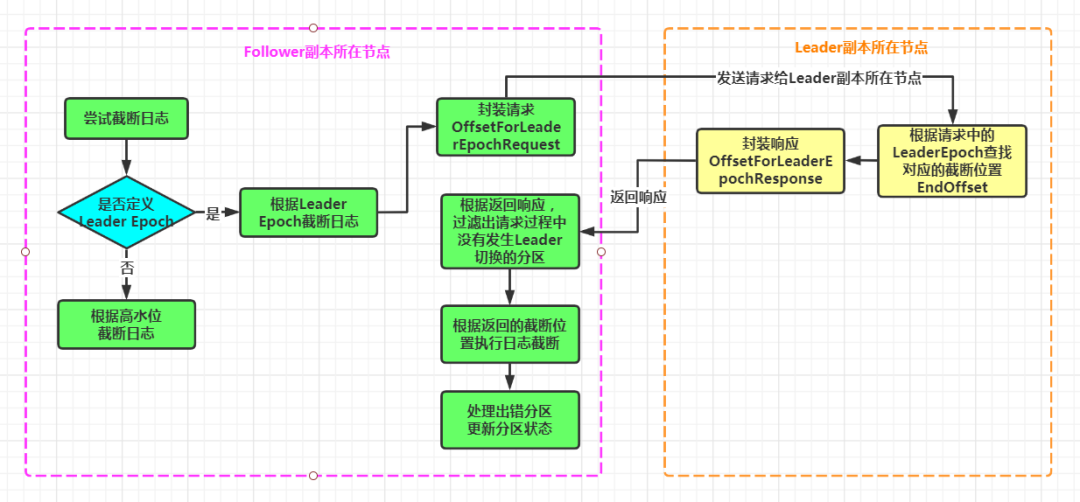
三、源码分析
首先进入到 AbstractFetcherThread 类的 doWork() 方法,关于这个类和 doWork() 方法,在《深入理解Kafka服务端之Follower副本如何同步Leader副本的数据》中已经分析过:
override def doWork() {//尝试日志截断maybeTruncate()//尝试拉取数据maybeFetch()}
这个方法的第一步就会尝试进行日志截断:
private def maybeTruncate(): Unit = {// 将所有处于截断中状态的分区依据有无Leader Epoch值进行分组val (partitionsWithEpochs, partitionsWithoutEpochs) = fetchTruncatingPartitions()// 对于有Leader Epoch值的分区,将日志截断到Leader Epoch值对应的位移值处if (partitionsWithEpochs.nonEmpty) {truncateToEpochEndOffsets(partitionsWithEpochs)}// 对于没有Leader Epoch值的分区,将日志截断到高水位值处if (partitionsWithoutEpochs.nonEmpty) {truncateToHighWatermark(partitionsWithoutEpochs)}}
maybeTruncate() 方法的逻辑为:
根据分区对应的Log对象有无 latestEpoch 值,将分区状态为isTruncating(截断中)的分区进行分组;
对于有latestEpoch值的分区,根据Leader Epoch进行日志截断
对于没有latestEpoch值的分区,根据HightWatermark进行日志截断
对于truncateToHighWatermark()方法,之前已经分析过,这里再简单看一下方法的逻辑:
private[server] def truncateToHighWatermark(partitions: Set[TopicPartition]): Unit = inLock(partitionMapLock) {val fetchOffsets = mutable.HashMap.empty[TopicPartition, OffsetTruncationState]// 遍历每个要执行截断操作的分区对象for (tp <- partitions) {// 获取分区的分区读取状态val partitionState = partitionStates.stateValue(tp)if (partitionState != null) {// 取出高水位值。val highWatermark = partitionState.fetchOffsetval truncationState = OffsetTruncationState(highWatermark, truncationCompleted = true)info(s"Truncating partition $tp to local high watermark $highWatermark")// 执行截断到高水位值if (doTruncate(tp, truncationState))//保存分区和对应的截取状态fetchOffsets.put(tp, truncationState)}}// 更新这组分区的分区读取状态updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)}
这篇重点分析truncateToEpochEndOffsets()方法,即根据Leader Epoch执行日志截断:
private def truncateToEpochEndOffsets(latestEpochsForPartitions: Map[TopicPartition, EpochData]): Unit = {//返回一组[分区 -> epoch + endOffset]val endOffsets = fetchEpochEndOffsets(latestEpochsForPartitions)inLock(partitionMapLock) {//获取一组在向Leader副本请求截断位置过程中没有发生leader副本切换的[分区 -> epoch + endOffset]val epochEndOffsets = endOffsets.filter { case (tp, _) =>//获取当前的分区状态val curPartitionState = partitionStates.stateValue(tp)//根据分区获取对应的OffsetsForLeaderEpochRequest请求对象val partitionEpochRequest = latestEpochsForPartitions.get(tp).getOrElse {throw new IllegalStateException(s"Leader replied with partition $tp not requested in OffsetsForLeaderEpoch request")}//获取请求中携带的Follower副本的LeaderEpoch值val leaderEpochInRequest = partitionEpochRequest.currentLeaderEpoch.get//如果分区状态不为null,且请求携带的LeaderEpoch和当前分区状态中的LeaderEpoch一致,即发送请求的过程中没有发生leader副本的切换curPartitionState != null && leaderEpochInRequest == curPartitionState.currentLeaderEpoch}//调用maybeTruncateToEpochEndOffsets进行日志截断,结果包含两个对象://fetchOffsets:进行正常截断的分区和对应的截断状态//partitionsWithError:出错的分区val ResultWithPartitions(fetchOffsets, partitionsWithError) = maybeTruncateToEpochEndOffsets(epochEndOffsets, latestEpochsForPartitions)//处理出错的分区,即将分区对象从集合头部移除,然后放到集合的末尾handlePartitionsWithErrors(partitionsWithError, "truncateToEpochEndOffsets")//更新分区的状态updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)}}
override def fetchEpochEndOffsets(partitions: Map[TopicPartition, EpochData]): Map[TopicPartition, EpochEndOffset] = {if (partitions.isEmpty) {debug("Skipping leaderEpoch request since all partitions do not have an epoch")return Map.empty}//封装OffsetsForLeaderEpochRequest请求val epochRequest = OffsetsForLeaderEpochRequest.Builder.forFollower(offsetForLeaderEpochRequestVersion, partitions.asJava, brokerConfig.brokerId)debug(s"Sending offset for leader epoch request $epochRequest")try {//向Leader副本所在节点发送OffsetsForLeaderEpochRequest请求并接受返回的OffsetsForLeaderEpochResponse响应val response = leaderEndpoint.sendRequest(epochRequest)//获取Leader返回的响应体val responseBody = response.responseBody.asInstanceOf[OffsetsForLeaderEpochResponse]debug(s"Received leaderEpoch response $response")//返回一组 [分区-> epoch + endOffset]responseBody.responses.asScala} catch {case t: Throwable =>warn(s"Error when sending leader epoch request for $partitions", t)val error = Errors.forException(t)partitions.map { case (tp, _) =>tp -> new EpochEndOffset(error, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)}}}
这个方法最重要的逻辑就是封装了一个 OffsetsForLeaderEpochRequest 请求,其中携带了Follower副本的 Leader Epoch值,并将请求发送给 Leader 副本所在的节点,获取 OffsetsForLeaderEpochResponse 响应。
//封装OffsetsForLeaderEpochRequest请求val epochRequest = OffsetsForLeaderEpochRequest.Builder.forFollower(offsetForLeaderEpochRequestVersion, partitions.asJava, brokerConfig.brokerId)//向Leader副本所在节点发送OffsetsForLeaderEpochRequest请求并接受返回的OffsetsForLeaderEpochResponse响应val response = leaderEndpoint.sendRequest(epochRequest)
既然是作为请求发送,那么 Leader 副本所在的节点处理该请求一定是通过KafkaApis.handle() 方法进行处理的,对应的具体方法是:handleOffsetForLeaderEpochRequest()
//处理OffsetsForLeaderEpochRequestcase ApiKeys.OFFSET_FOR_LEADER_EPOCH => handleOffsetForLeaderEpochRequest(request)
def endOffsetFor(requestedEpoch: Int): (Int, Long) = {inReadLock(lock) {val epochAndOffset =//如果请求的Leader Epoch = UNDEFINED_EPOCHif (requestedEpoch == UNDEFINED_EPOCH) {//返回的Leader Epoch 和 EndOffset为(UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)(UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)//如果请求的Leader Epoch 就是Leader副本当前的Leader Epoch,则返回LEO} else if (latestEpoch.contains(requestedEpoch)) {//返回(请求Epoch,Leader副本LEO)(requestedEpoch, logEndOffset())} else {//按照是否大于Follower请求的Epoch,将Leader端的Epoch缓存进行分组//subsequentEpochs:大于请求Epoch的Epochs集合//previousEpochs:小于等于请求Epoch的Epochs集合val (subsequentEpochs, previousEpochs) = epochs.partition { e => e.epoch > requestedEpoch}//如果Leader端缓存的Epoch都比请求的Epoch小if (subsequentEpochs.isEmpty) {//返回(UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)(UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)//如果Leader端缓存的Epoch不小于(≥)请求的Epoch} else if (previousEpochs.isEmpty) {//如果请求的epoch 比leader端保存的任何一个epoch都小,那么endOffset取最小epoch 对应的startOffset(requestedEpoch, subsequentEpochs.head.startOffset)//如果Leader端缓存的Epoch既有大于请求Epoch的,也有小于等于请求Epoch的,} else {// 针对Epoch:返回不大于请求Epoch的Epoch//针对endOffset:返回第一个大于请求Epoch的Epoch对应的StartOffset(previousEpochs.last.epoch, subsequentEpochs.head.startOffset)}}debug(s"Processed end offset request for epoch $requestedEpoch and returning epoch ${epochAndOffset._1} " +s"with end offset ${epochAndOffset._2} from epoch cache of size ${epochs.size}")epochAndOffset}}
如果Follower副本请求中的 Leade Epoch 值等于Leader副本端的LeaderEpoch,那么就返回 Leader 副本的 LEO 如果Follower副本请求中的 LeaderEpoch 值小于Leader副本端的LeaderEpoch,说明发生过leader副本的切换。 对于LeaderEpoch,返回Leader副本端保存的不大于Follower副本请求中LeaderEpoch 的最大 LeaderEpoch 对于EndOffset:返回 Leader 副本端保存的第一个比 Follower 副本请求中LeaderEpoch 大的 LeaderEpoch 对应的 StartOffset。
val epochEndOffsets = endOffsets.filter { case (tp, _) =>//获取当前的分区状态val curPartitionState = partitionStates.stateValue(tp)//根据分区获取 OffsetsForLeaderEpochRequest请求中的分区信息val partitionEpochRequest = latestEpochsForPartitions.get(tp).getOrElse {throw new IllegalStateException(s"Leader replied with partition $tp not requested in OffsetsForLeaderEpoch request")}//获取请求中携带的Follower副本的LeaderEpoch值val leaderEpochInRequest = partitionEpochRequest.currentLeaderEpoch.get//如果分区状态不为null,且请求携带的LeaderEpoch和当前分区状态中的LeaderEpoch一致,即发送请求的过程中没有发生leader副本的切换curPartitionState != null && leaderEpochInRequest == curPartitionState.currentLeaderEpoch}
第三步:根据Leader poch执行日志截断,调用的方法是 maybeTruncateToEpochEndOffsets
val ResultWithPartitions(fetchOffsets, partitionsWithError) = maybeTruncateToEpochEndOffsets(epochEndOffsets, latestEpochsForPartitions)
返回结果包含两个对象:
fetchOffsets:进行正常日志截断的分区和对应的截断状态
partitionsWithError:一组出错的分区
然后根据返回的结果,分别处理出错的分区和正常进行日志截断的分区。
如果分区出错,则将该分区对象从集合的头部移除,然后放到集合的末尾;
如果分区正常进行日志截断,则更新分区的状态
//处理出错的分区,即将分区对象从集合头部移除,然后放到集合的末尾handlePartitionsWithErrors(partitionsWithError, "truncateToEpochEndOffsets")//更新分区的状态updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)
