在上一篇分析了 Leader 副本写入消息及 Follower 副本进行同步的流程,首先回顾一下这9个步骤:
- follower 副本发送同步数据请求,携带自身的 LEO
- leader 副本更新本地保存的其它副本的 LEO
- leader 副本给 follower 副本返回数据,携带 leader 副本的 HW 值
- follower 副本接收响应并写入数据,更新自身 LEO
在 Kafka 0.11.0.0 版本之前,Follower 都是基于 HW 机制去同步数据的,但是使用中发现这种机制会导致数据丢失和数据不一致的问题,所以从 0.11.0.0 版本开始,Kafka 引入了 Leader Epoch 机制,以此来解决基于 HW 进行同步所带来的问题。
对于 Leader 副本和 Follower 副本,各自存储的 HW 和 LEO 情况如下: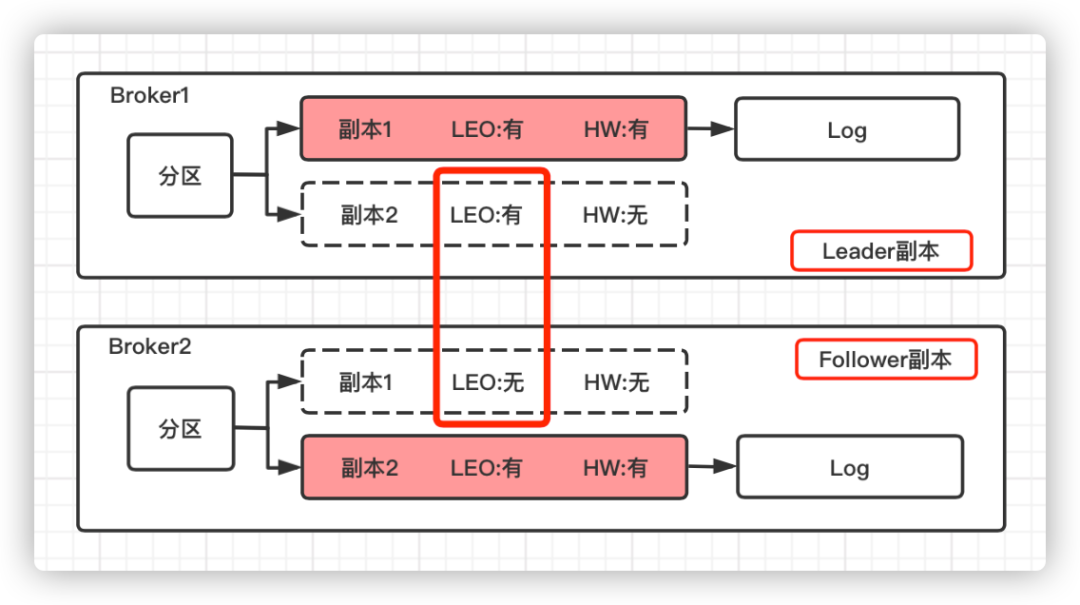
Leader 副本和 Follower 副本所在的节点均保存了该分区下所有的副本对象,但是只有本地副本(图中用红色背景标识)会保存对应的日志文件。
对于 HW 而言:Leader 副本和 Follower 副本所在节点均只保存了各自的 HW。
对于 LEO 而言:Follower 副本所在节点只保存了自己的 LEO,而 Leader 副本所在的节点则保存了该分区下所有副本的 LEO。
在 Kafka 的根目录下,有4个检查点文件,其中 recovery-point-offset-checkpoint 检查点文件用于保存 LEO 值,而 replication-offset-checkpoint 检查点文件用于保存 HW 值。
下面通过一个流程图来分析一下 Leader 副本和 Follower 副本的 HW 以及 LEO 的更新时机:
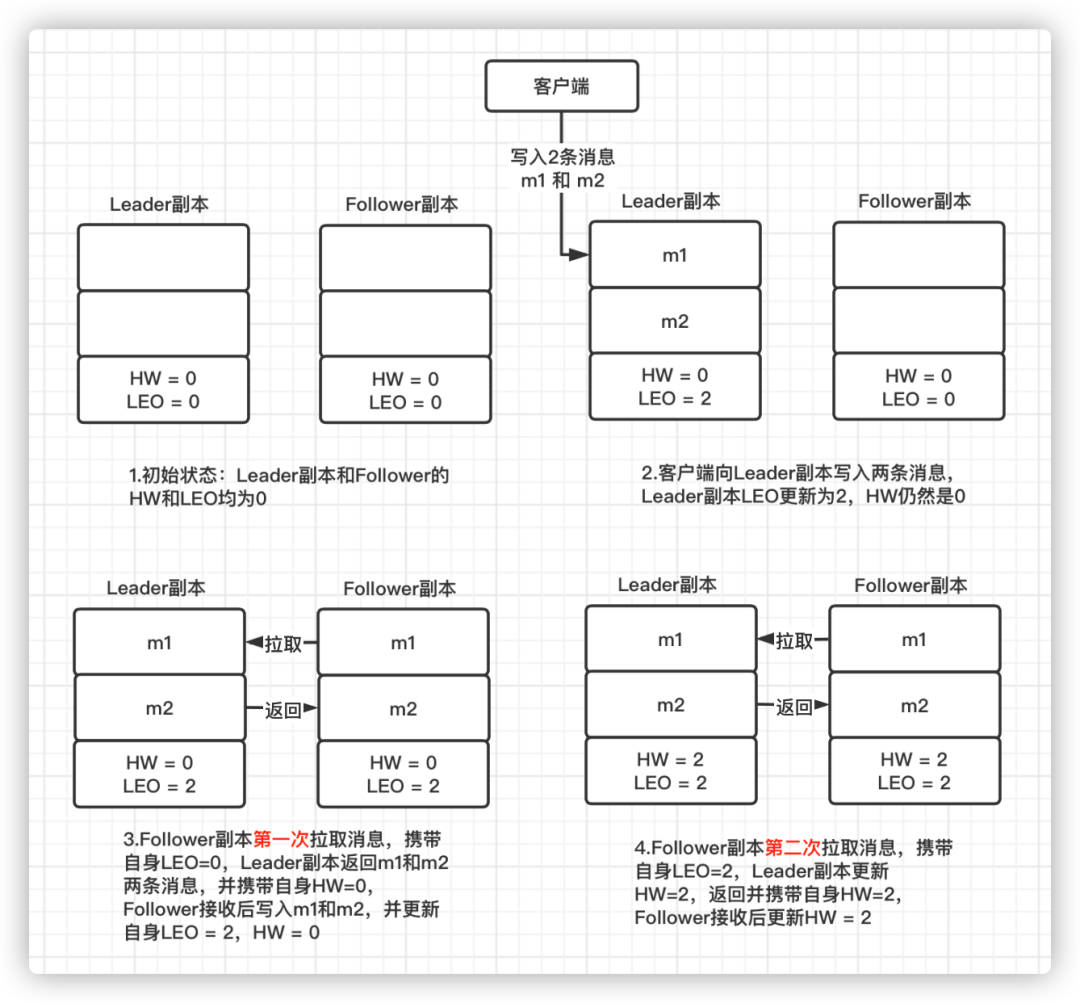
从这个流程图可以看出,Follower 副本第一轮FetchRequest/FetchResponse 拉取到消息后只更新了LEO 值,而 HW 值需要第二轮的FetchRequest/FetchResponse 才会进行更新。前提:这里假设 min.insync.replicas 配置为 1,即 ISR 列表中最少的副本数为 1
数据丢失问题分析:
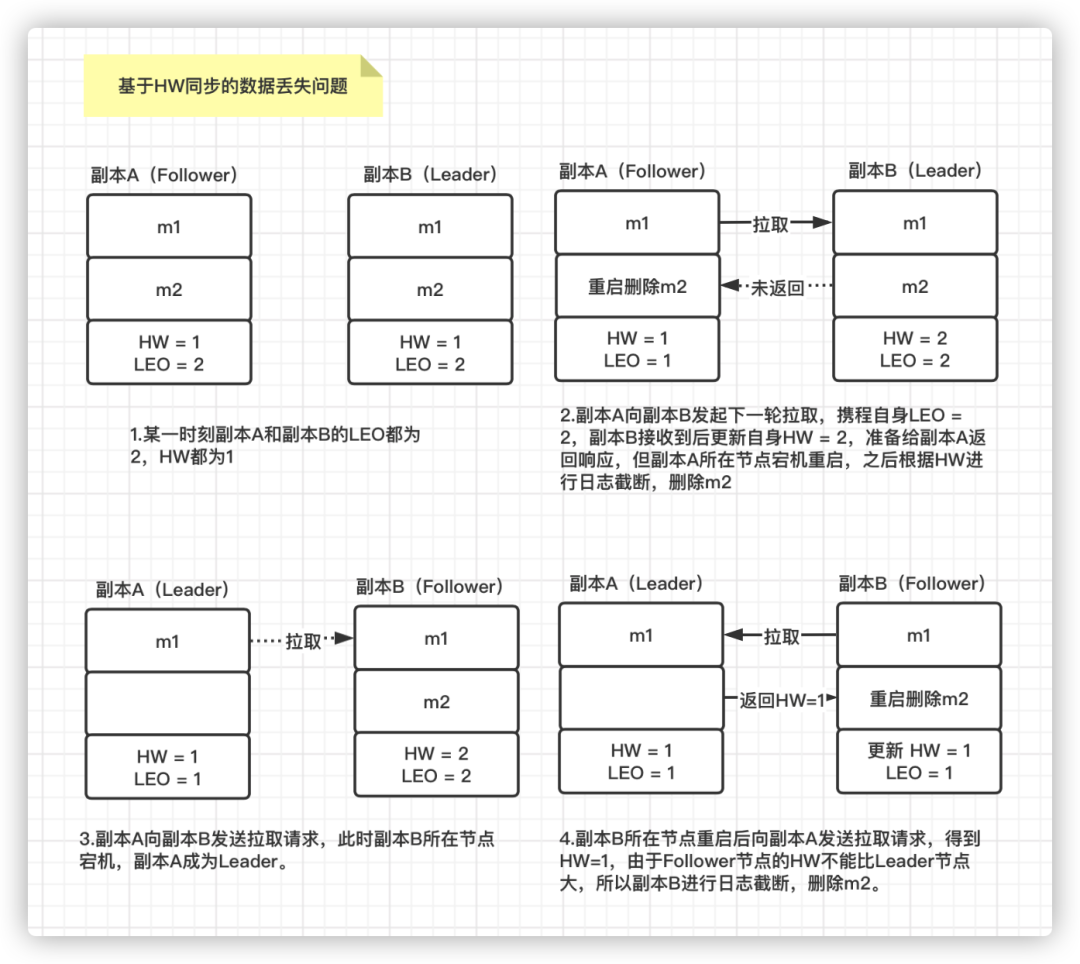
假设某一时刻:副本A(Follower)的 LEO = 2 HW = 1, 副本B(Leader)的 LEO = 2 HW =1。
此时副本A 发起再一轮的拉取,携带自身LEO = 2,副本B 接收到后更新自身 HW = 2,但是在返回给副本A 响应时,副本A 所在节点宕机。当副本A 所在节点重启时,会根据 HW = 1 进行日志截断,即删除 m2 这条数据。然后向副本B 所在节点发送拉取数据请求。
如果此时正好副本B 所在的节点也宕机了,那么原来的副本A 被选为 Leader 副本,其 HW =1。之后副本B 所在节点重启后,副本B 成为 Follower 副本,由于 Follower 副本的 HW 不能比 Leader 副本的 HW 高,所以副本B 还会进行一次日志截断,删除消息m2 并将 HW 调整为1。这就导致 m2 这条消息永远丢失了。
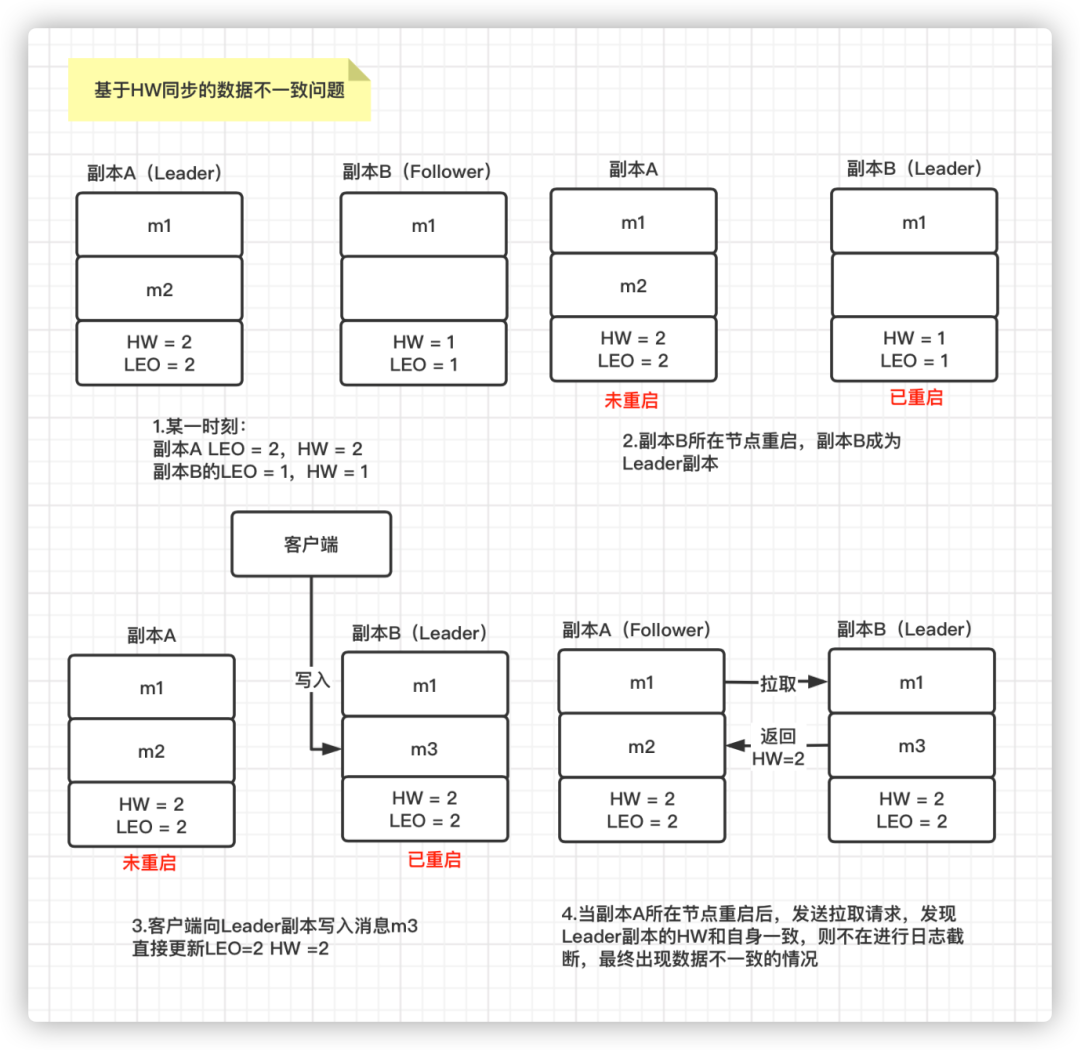
假设某一时刻:副本A(Leader)已经写入2条消息 m1 和 m2 ,其 LEO = 2 HW = 2, 副本B(Follower)只同步了1条消息 m1,其 LEO = 1 HW =1。这里解释下为什么 Follower 的 LEO = 1,而 Leader 副本的 HW 却可以为2,正常来说,Leader 副本的 HW 应该是 ISR 列表中最小的 LEO。由于配置了 min.isync.replicas = 1,所以 Follower 对应的 Replica 对象就不在 ISR 列表,该列表中只有 Leader 副本对应的 Replica 对象,所以 Leader 副本的 HW 由自身 LEO 决定。 如果此时副本A 所在的节点和副本B 所在的节点同时宕机,随后副本B 所在节点先重启,那么副本B 成为 Leader 副本,其 HW = 1,LEO =1。这时客户端往该分区又写入一条消息 m3,即写入了副本B,其 HW 和 LEO 值均更新为2。当副本A 所在节点重启时,发现其 HW 和 LEO 值都和副本B 一致,那么就不会进行日志截断操作也不会再同步m3这条数据。
此时副本A 中有2条消息 m1 和 m2,而副本B 中也有2条消息,m1 和 m3,这就导致了两个副本的数据不一致问题。
从 0.11.0.0 版本开始,引入了leader epoch 的概念,在需要进行日志截断的时候使用 leader epoch 作为参考,而不是原来的 HW。leader epoch 代表 leader 的纪元信息,初始值为0。每当 leader 变更一次,该值就会加 1 。与此同时,每个副本中还会增加一个对应关系:LeaderEpoch -> StartOffset,其中StartOffset 表示该 LeaderEpoch 下写入的第一条消息的偏移量,这个StartOffset也可以理解为上一个LeaderEpoch下副本的 LEO 值。每个副本的Log下都有一个 leader-epoch-checkpoint 文件,在发生 leader epoch 变更时,会将LeaderEpoch -> StartOffset 的对应关系追加到这个文件。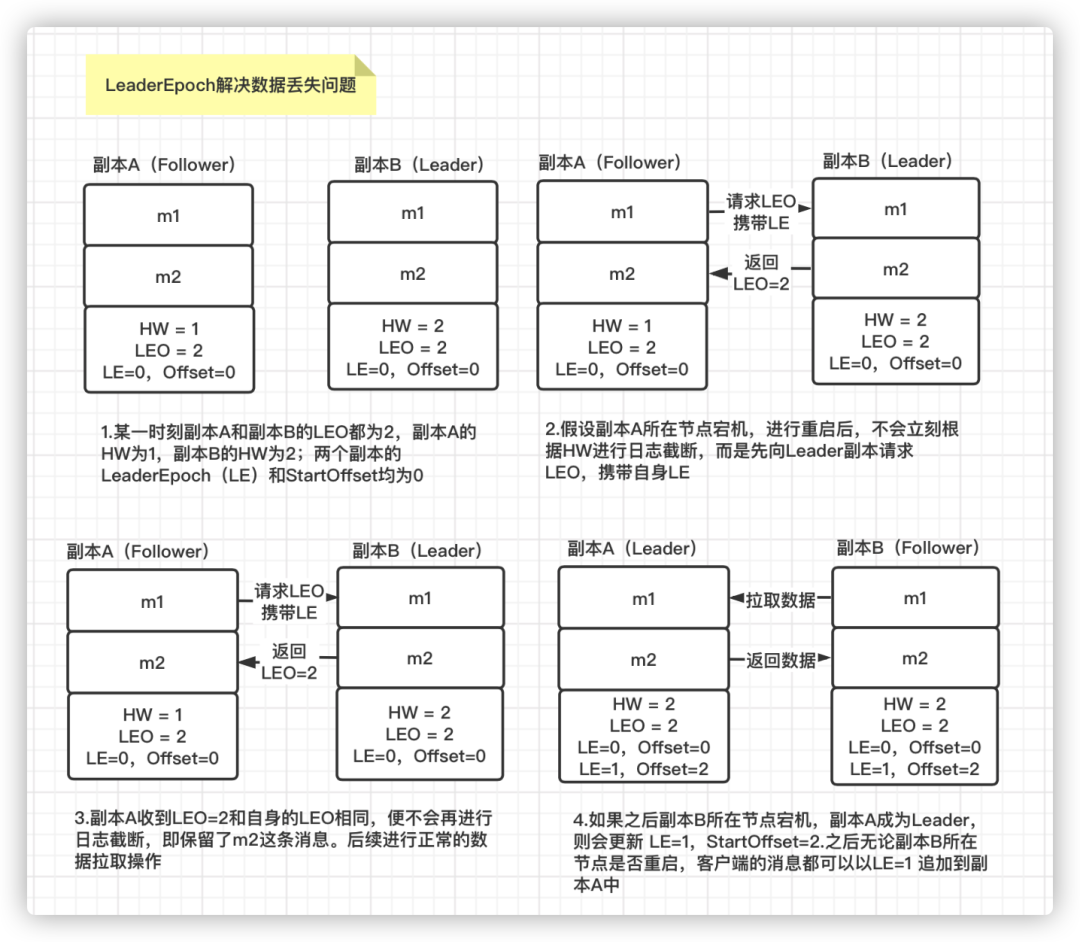
假设某一时刻,副本A和副本B的 LEO 都为2,副本A 的 HW 为1,副本B 的 HW 为2。副本A 和副本B 的LeaderEpoch(LE)和 StartOffset 均为0。
此时副本A 所在节点宕机,之后进行重启。这时不会立刻根据副本A 的HW 进行日志截断,而是先向 Leader 副本发送 OffsetsForLeaderEpochRequest 请求,携带自身的 LeaderEpoch 值。随后 Leader 副本会返回 OffsetsForLeaderEpochResponse 响应,携带当前的 LEO 值2。
副本B 接收到 Leader 副本返回的 LEO=2,和自身的 LEO 值相等,则不会再进行日志截断,也就保留了m2这条消息。
如果之后副本B所在节点宕机,副本A 被选为 Leader 副本,那么其LeaderEpoch更新为1,对应的StartOffset更新为2。后面无论副本B 所在节点是否重启,客户端的生产数据请求都可以追加到副本A 对应的日志文件中。
如何解决数据不一致问题:
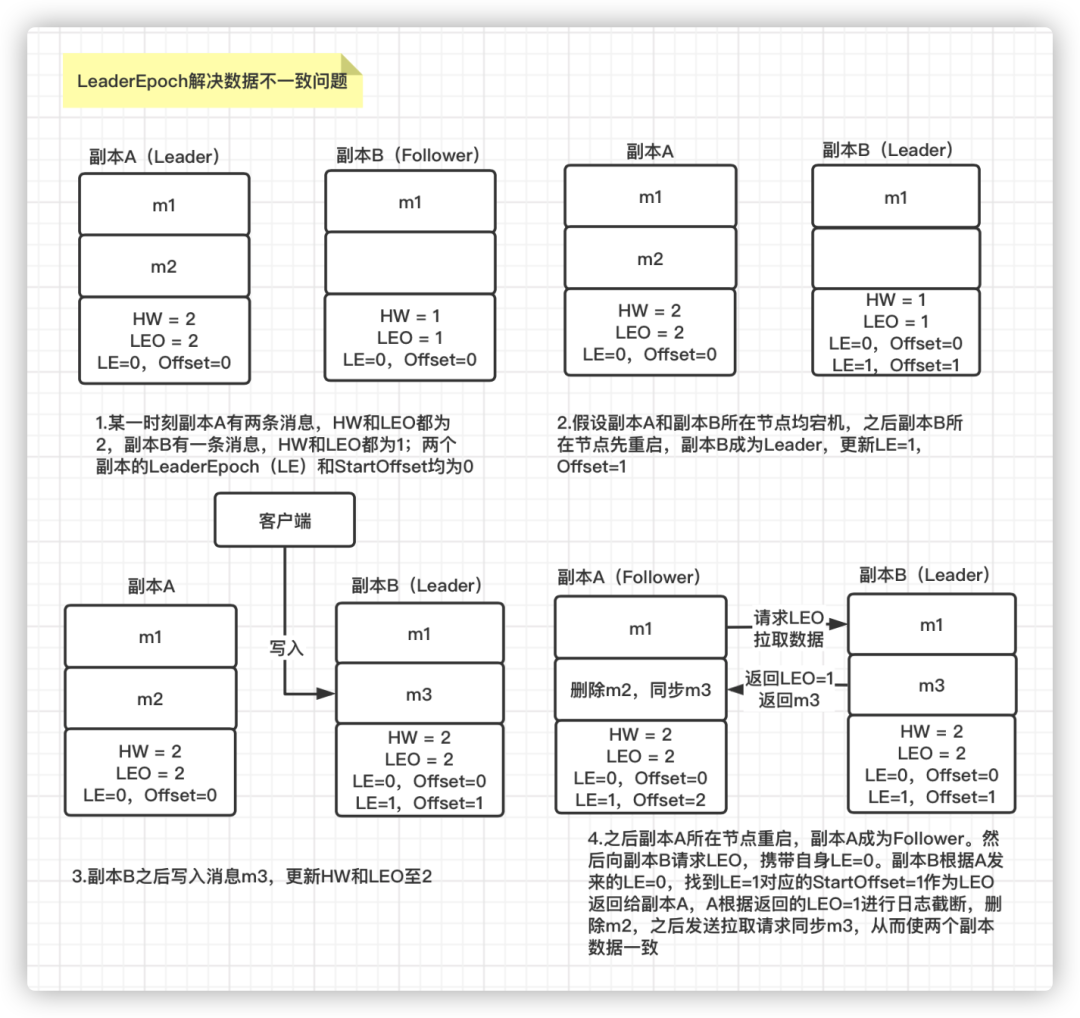
假设某一时刻,副本A 有两条消息 m1 和 m2,HW 和 LEO 均为2;副本B 有一条消息 m1,HW 和 LEO 均为1。两个副本的LeaderEpoch 和 StartOffset均为0,此时两个副本所在的节点均宕机。 随后,副本B 所在的节点先重启,副本B 成为 Leader 副本,将LeaderEpoch 和 StartOffset 更新为1。然后客户端向副本B 发送消息m3,副本B 写入后,将 HW 和 LEO 更新为2。 之后副本A 所在的节点进行重启,副本A 成为 Follower 副本。然后向副本B 发送 OffsetsForLeaderEpochRequest 请求,携带自身的LeaderEpoch=0。副本B 根据收到的副本A 的 LeaderEpoch=0,发现和当前自身的 LeaderEpoch=1 不一致,则将自身 LeaderEpoch 对应的 StartOffset = 1 作为副本A 的LEO 返回。 副本A 根据返回的 LEO =1 进行日志截断,删除消息 m2。随后副本A 正常向副本B 拉取数据,同步消息m3,更新自身 HW 和 LEO 为2。至此,通过 LeaderEpoch 机制就解决了两个副本数据不一致的问题。





