




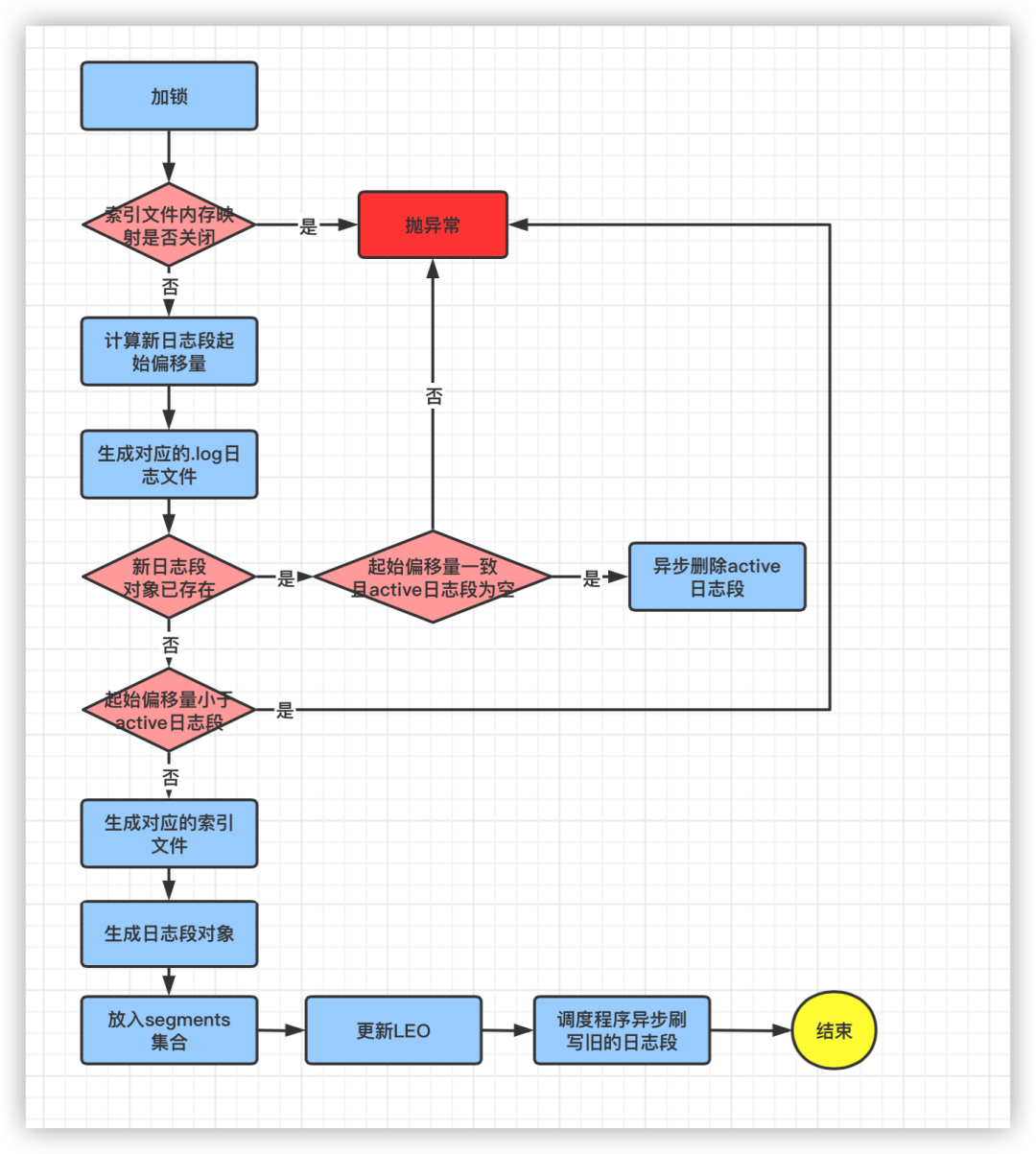
三、源码分析
由于LogSegment是由Log管理的,所以按理说,控制生成新的LogSegment的方法就应该在Log类中。这个方法就是roll()方法,它的注释如下:
* Roll the log over to a new active segment starting with the current logEndOffset.* This will trim the index to the exact size of the number of entries it currently contains.
这里要重点关注一个概念:LogEndOffset,简称LEO。是Kafka服务端十分重要的一个概念,后面还会多次提及。表示的是下一条待写入消息的偏移量。
生成新日志段的流程分析:
def roll(expectedNextOffset: Option[Long] = None): LogSegment = {maybeHandleIOException(s"Error while rolling log segment for $topicPartition in dir ${dir.getParent}") {//记录开始时间val start = time.hiResClockMs()lock synchronized {//检查索引文件的内存映射是否关闭checkIfMemoryMappedBufferClosed()//计算新日志段文件的起始偏移量baseOffsetval newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset)//生成新的日志文件val logFile = Log.logFile(dir, newOffset)//如果newOffset对应的日志段文件已存在if (segments.containsKey(newOffset)) {//如果active日志段的起始偏移量和上面计算的起始偏移量相同,且active日志段的日志文件大小为0,则删除active日志段if (activeSegment.baseOffset == newOffset && activeSegment.size == 0) {warn(s"Trying to roll a new log segment with start offset $newOffset " +s"=max(provided offset = $expectedNextOffset, LEO = $logEndOffset) while it already " +s"exists and is active with size 0. Size of time index: ${activeSegment.timeIndex.entries}," +s" size of offset index: ${activeSegment.offsetIndex.entries}.")//异步删除active日志段(先标记为.delete)deleteSegment(activeSegment)} else {//如果日志段文件已存在且不是active,则抛异常throw new KafkaException(s"Trying to roll a new log segment for topic partition $topicPartition with start offset $newOffset" +s" =max(provided offset = $expectedNextOffset, LEO = $logEndOffset) while it already exists. Existing " +s"segment is ${segments.get(newOffset)}.")}//如果计算出的baseOffset比active日志段的baseOffset还小,则抛异常} else if (!segments.isEmpty && newOffset < activeSegment.baseOffset) {throw new KafkaException(s"Trying to roll a new log segment for topic partition $topicPartition with " +s"start offset $newOffset =max(provided offset = $expectedNextOffset, LEO = $logEndOffset) lower than start offset of the active segment $activeSegment")} else {//代码走这里说明newOffset正常val offsetIdxFile = offsetIndexFile(dir, newOffset)//生成index文件名val timeIdxFile = timeIndexFile(dir, newOffset)//生成timeindex文件名val txnIdxFile = transactionIndexFile(dir, newOffset)//生成txnindex文件名//如果文件已存在则删除for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {warn(s"Newly rolled segment file ${file.getAbsolutePath} already exists; deleting it first")Files.delete(file.toPath)}Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())}producerStateManager.updateMapEndOffset(newOffset)producerStateManager.takeSnapshot()//生成新的日志段对象val segment = LogSegment.open(dir,baseOffset = newOffset,config,time = time,fileAlreadyExists = false,initFileSize = initFileSize,preallocate = config.preallocate)//将新的日志段对象添加到MapaddSegment(segment)//更新LEOupdateLogEndOffset(nextOffsetMetadata.messageOffset)// 异步刷写旧的日志段scheduler.schedule("flush-log", () => flush(newOffset), delay = 0L)info(s"Rolled new log segment at offset $newOffset in ${time.hiResClockMs() - start} ms.")//返回生成的日志段对象segment}}}
a. 检查该Log对象的索引文件内存映射是否关闭
//检查索引文件的内存映射是否关闭,默认未关闭,如果关闭了则该Log对象就不允许进行磁盘IO操作了checkIfMemoryMappedBufferClosed()
是否关闭由一个boolean类型的变量标记,默认为false
@volatile private var isMemoryMappedBufferClosed = false
b. 计算新的日志段文件的起始偏移量baseOffset
//计算新日志段文件的起始偏移量baseOffsetval newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset
c. 生成新的日志文件,即.log文件。参数dir就是该Log对象对应的分区在磁盘上的物理路径
//生成新的日志文件val logFile = Log.logFile(dir, newOffset)
如果当前active日志段的起始偏移量baseOffset和newOffset一样,且active日志段里面没有保存任何消息,则异步删除active日志段 如果不是active日志段,则抛出异常
if (segments.containsKey(newOffset)) {//如果active日志段的起始偏移量和上面计算的起始偏移量相同,且active日志段的日志文件大小为0,则删除active日志段if (activeSegment.baseOffset == newOffset && activeSegment.size == 0) {warn(s"Trying to roll a new log segment with start offset $newOffset " +s"=max(provided offset = $expectedNextOffset, LEO = $logEndOffset) while it already " +s"exists and is active with size 0. Size of time index: ${activeSegment.timeIndex.entries}," +s" size of offset index: ${activeSegment.offsetIndex.entries}.")//异步删除active日志段(先标记为.delete)deleteSegment(activeSegment)} else {//如果日志段文件已存在且不是active,则抛异常throw new KafkaException(s"Trying to roll a new log segment for topic partition $topicPartition with start offset $newOffset" +s" =max(provided offset = $expectedNextOffset, LEO = $logEndOffset) while it already exists. Existing " +s"segment is ${segments.get(newOffset)}.")}}
d2. 如果计算出的newOffset比active日志段的起始偏移量baseOffset还小,则抛异常:
else if (!segments.isEmpty && newOffset < activeSegment.baseOffset) {throw new KafkaException(s"Trying to roll a new log segment for topic partition $topicPartition with " +s"start offset $newOffset =max(provided offset = $expectedNextOffset, LEO = $logEndOffset) lower than start offset of the active segment $activeSegment")}
d3. 如果newOffset没有问题,则创建日志段对应的各种索引文件。
else {//代码走这里说明newOffset正常val offsetIdxFile = offsetIndexFile(dir, newOffset)//生成index文件名val timeIdxFile = timeIndexFile(dir, newOffset)//生成timeindex文件名val txnIdxFile = transactionIndexFile(dir, newOffset)//生成txnindex文件名//如果文件已存在则删除for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {warn(s"Newly rolled segment file ${file.getAbsolutePath} already exists; deleting it first")Files.delete(file.toPath)}Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())}
e. 生成新的日志段对象
//生成新的日志段对象val segment = LogSegment.open(dir,baseOffset = newOffset,config,time = time,fileAlreadyExists = false,initFileSize = initFileSize,preallocate = config.preallocate)
f. 将生成的日志段对象添加到集合segments中,这个集合用的就是ConcurrentSkipListMap跳表这种数据结构
//将新的日志段对象添加到MapaddSegment(segment)
g. 更新LEO
//更新LEOupdateLogEndOffset(nextOffsetMetadata.messageOffset)
h. 调度异步程序刷写旧的日志段文件
scheduler.schedule("flush-log", () => flush(newOffset), delay = 0L)
i. 返回新生成日志段对象
2.滚动生成新日志段的条件剖析:
直接查看调用roll方法的地方,在Log.maybeRoll方法中,该方法的作用是:如果有必要,滚动生成一个新的日志段对象返回;否则返回当前 active 日志段对象:
private def maybeRoll(messagesSize: Int, appendInfo: LogAppendInfo): LogSegment = {//获取当前active日志段对象val segment = activeSegment//获取当前时间val now = time.milliseconds//消息中的最大时间戳val maxTimestampInMessages = appendInfo.maxTimestamp//消息中的最大偏移量val maxOffsetInMessages = appendInfo.lastOffset//如果需要滚动生成新的日志段对象if (segment.shouldRoll(RollParams(config, appendInfo, messagesSize, now))) {debug(s"Rolling new log segment (log_size = ${segment.size}/${config.segmentSize}}, " +s"offset_index_size = ${segment.offsetIndex.entries}/${segment.offsetIndex.maxEntries}, " +s"time_index_size = ${segment.timeIndex.entries}/${segment.timeIndex.maxEntries}, " +s"inactive_time_ms = ${segment.timeWaitedForRoll(now, maxTimestampInMessages)}/${config.segmentMs - segment.rollJitterMs}).")appendInfo.firstOffset match {case Some(firstOffset) => roll(Some(firstOffset))case None => roll(Some(maxOffsetInMessages - Integer.MAX_VALUE))}} else {segment}}
其中判断是否需要滚动生成新的日志段对象调用的是LogSegment.shouldRoll方法:
segment.shouldRoll(RollParams(config, appendInfo, messagesSize, now))
LogSegment.shouldRoll方法:
def shouldRoll(rollParams: RollParams): Boolean = {//日志段等待滚动的时间 > 日志段保留的最大时间 - 扰动时间 即:如果为true,表示可以滚动了//maxTimestampInMessages:待写入消息中的最大时间戳//maxSegmentMs:日志段保留的最大时间,默认168小时,由参数 log.roll.hours 配置//rollJitterMs:扰动值,避免同一时间生成大量的日志段文件给磁盘带来的压力val reachedRollMs = timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) > rollParams.maxSegmentMs - rollJitterMs//滚动条件:①日志段大小超过maxSegmentBytes(默认1G)size > rollParams.maxSegmentBytes - rollParams.messagesSize ||//②日志段不为空,且等待滚动时间超过168h(size > 0 && reachedRollMs) ||//③偏移量索引文件或者时间戳索引文件大小超过10M ④最大偏移量和baseOffset的差值超过Int.MaxValueoffsetIndex.isFull || timeIndex.isFull || !canConvertToRelativeOffset(rollParams.maxOffsetInMessages)//判断是否可以将日志段中最大的偏移量转为相对偏移量}
a. timeWaitedForRoll方法:计算日志段等待滚动的时间:
def timeWaitedForRoll(now: Long, messageTimestamp: Long) : Long = {//加载日志段中第一个批次的最大时间戳loadFirstBatchTimestamp()rollingBasedTimestamp match {//如果 rollingBasedTimestamp不为None,则返回当前待写入消息的最大时间戳 - rollingBasedTimestamp 的值case Some(t) if t >= 0 => messageTimestamp - t//如果 rollingBasedTimestamp 为None,则返回当前时间 - 日志段的创建时间case _ => now - created}}
private def loadFirstBatchTimestamp(): Unit = {if (rollingBasedTimestamp.isEmpty) {val iter = log.batches.iterator()if (iter.hasNext)rollingBasedTimestamp = Some(iter.next().maxTimestamp)}}
//获取日志段追加数据的起始物理地址val physicalPosition = log.sizeInBytes()//如果物理地址为0,说明日志段为空,即当前为第一次写入消息if (physicalPosition == 0)//更新用于日志段切分的时间戳为当前消息集合的最大时间戳rollingBasedTimestamp = Some(largestTimestamp)
所以日志段等待滚动的时间的计算逻辑为:
如果日志段为空:当前时间 - 日志段的创建时间 如果日志段不为空:待写入消息集合的最大时间戳 - 第一次写入消息集合的最大时间戳
rollParams.maxSegmentMs:日志段时间维度的阈值,由服务端参数:log.roll.hours 和 log.roll.ms 配置,log.roll.ms 优先级高。但默认情况下只配置了 log.roll.hours ,为168,即7天。如果等待超过这个时间该日志段还未写满,则滚动生成新的日志段(如果日志段为空则不会滚动)。
rollJitterMs:扰动值。避免在同一时间生成大量的日志段文件给磁盘IO带来压力
val reachedRollMs = timeWaitedForRoll(rollParams.now, rollParams.maxTimestampInMessages) > rollParams.maxSegmentMs - rollJitterMs
reachedRollMs:Boolean值,标记时间维度是否满足滚动条件。
c. 滚动生成新日志段的条件:
c1. 日志段容量达到阈值:
size > rollParams.maxSegmentBytes - rollParams.messagesSize=>size + rollParams.messagesSize > rollParams.maxSegmentBytes即已经写入的字节 + 待写入消息字节 > 日志段最大容量
rollParams.maxSegmentBytes:日志段文件的最大容量。由服务端参数:log.segment.bytes 配置,默认为1G。
(size > 0 && reachedRollMs)
offsetIndex.isFull || timeIndex.isFull
索引文件的阈值由服务端参数:log.index.size.max.bytes 配置,默认为10M。
!canConvertToRelativeOffset(rollParams.maxOffsetInMessages)
日志段容量超过阈值:默认为1G 日志段不为空且等待滚动的时间超过阈值:默认为7天 日志段索引文件(包括偏移量索引文件和时间戳索引文件)容量超过阈值:默认为10M 待写入消息集合的最大偏移量 - 日志段起始偏移量 > Int.MaxValue,此时无法转为相对偏移量
