




一、场景分析
日志段管理:滚动生成新日志段、组织并管理分区下的所有日志段等 关键偏移量管理:如LogStartOffset、LEO等 读写操作:进行日志的读写 高水位操作管理:定义了对于高水位值的各种操作,包括更新和读取
二、图示说明
对日志段的管理主要是操作segments集合:
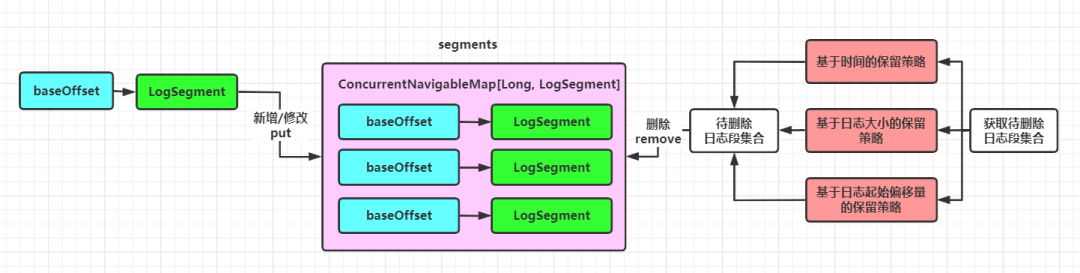
三、源码分析
1. 日志段管理:Log类定义了一个用于保存日志段对象的集合:segments
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
这里采用了ConcurrentSkipListMap这种结构来保存所有的日志段对象。其中Key是日志段的起始偏移量baseOffset,value是对应的LogSegment对象。采用这种结构的好处是:
它是线程安全的
它是键值(key)可排序的:由于日志段的起始偏移量是有序的,在查找指定offset的消息时,可以通过跳表这种结构快速定位消息所在的日志段
管理日志段的相关方法:
对于日志段滚动的相关方法在《深入理解Kafka服务端之滚动生成新日志段的条件》中已经分析过,这里不再赘述。下面主要分析针对日志段集合segments的操作:
a. 增加:addSegment
def addSegment(segment: LogSegment): LogSegment = this.segments.put(segment.baseOffset, segment)
这个方法相对简单,就是调用Map的put方法将给定的LogSegment对象添加到segments集合中
b. 删除:deleteSegment
日志删除的相关操作较复杂,在分析删除方法前,先看一下Kafka对于日志清理的相关知识点:
Kafka提供了两种日志清理的策略:
日志删除(Log Retention):按照一定的保留策略直接删除不符合条件的日志分段
日志压缩(Log Compaction):针对每个消息的key进行整合,对于有相同Key的不同的value值,只保留最后一个版本
可以通过broker端参数 log.cleanup.policy 来者之日志段的清理策略,默认为 "delete",即采用日志删除的清理策略。如果要采用日志压缩的清理策略,就需要将 log.cleanup.policy 的值设置为 "compact",并且将 log.cleaner.enable 设定为true(这个参数默认就是true)。通过设置参数 log.cleanup.policy 为 "delete,compact" 还可以同时支持日志删除和日志压缩两种策略。
对于日志删除策略,Kafka的日志管理器LogManager中会有一个专门的日志删除任务(以 "delete-file" 命名的延迟任务)来周期性地检测和删除不符合保留策略的日志段文件,这个周期通过broker端参数 log.retention.check.interval.ms 来配置,默认300000,即5分钟。
当前日志段的保留策略有三种:
基于时间的保留策略:deleteRetentionMsBreachedSegments()
private def deleteRetentionMsBreachedSegments(): Int = {if (config.retentionMs < 0) return 0//获取当前时间val startMs = time.milliseconds//删除不满足保留策略的日志段,返回删除的日志段数量//这里的不满足的日志段指:当前时间 - 日志段的最大时间戳 = 日志段未更改的持续时间(保留时间)//持续时间 > config.retentionMs(默认7天) ,则删除deleteOldSegments((segment, _) => startMs - segment.largestTimestamp > config.retentionMs,reason = s"retention time ${config.retentionMs}ms breach")}
日志删除任务会检查当前日志文件中是否有保留时间超过设定的阈值(retentionMs) 来寻寻找可删日志分段文件集合(deletableSegment)。retentionMs 可以通过 broker 端参数 log.retention.hours、log.retention.minutes 、log.retention.ms 来配置。其中 log.retention.ms 的优先级最高,log.retention.minutes 次之,log.retention.hours最低。默认情况下只配置了 log.retention.hours 参数,其值为168。 故默认情况下日志分段文件的保留时间为7天。
方法中 largestTimestamp 的获取方法是从时间戳索引文件中获取最后一条索引项,然后根据索引项对应时间戳字段的值决定:
如果最后一条索引项的时间戳字段值大于0,则直接取该值
否则,取日志分段的最近修改时间:lastModifiedTime
基于日志大小的保留策略:deleteRetentionSizeBreachedSegments()
private def deleteRetentionSizeBreachedSegments(): Int = {if (config.retentionSize < 0 || size < config.retentionSize) return 0//计算要删除的日志的字节数:diff = size(日志的总字节数)- config.retentionSize(日志大小阈值,默认为-1,即无穷大)var diff = size - config.retentionSize//判断是否需要删除的函数def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]) = {//如果需要删除的字节 - 日志段的字节 > 0 说明需要被删除if (diff - segment.size >= 0) {diff -= segment.sizetrue} else {false}}//执行删除deleteOldSegments(shouldDelete, reason = s"retention size in bytes ${config.retentionSize} breach")}
日志删除任务会检查当前的日志的总大小是否超过了设定的阈值(retentionSize)来寻找可删除的日志分段的文件集合(deletableSegments)。retentionSize 通过 broker 端参数 log.retention.bytes 来配置,默认为-1,表示无穷大。
基于日志大小的保留策略首先会计算需要删除的日志总大小,然后从日志文件中的第一个日志分段开始查找可删除的日志分段的文件集合deletableSegments,然后执行删除操作。
基于日志起始偏移量的保留策略:deleteLogStartOffsetBreachedSegments()
private def deleteLogStartOffsetBreachedSegments(): Int = {//定义是否需要删除给定的日志段def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]) =//如果给定日志段的下一个日志段的起始偏移量 <= LogStartOffset ,则删除nextSegmentOpt.exists(_.baseOffset <= logStartOffset)deleteOldSegments(shouldDelete, reason = s"log start offset $logStartOffset breach")}
注意:一般来说,日志的起始偏移量就是第一个日志分段的baseOffset,但是并不绝对,logStartOffset的值可以通过 DeleteRecordsRequest 请求、日志的清理和截断等操作进行修改。
假设logStartOffset=25,日志段1的baseOffset=0,日志段2的baseOffset=11,日志段3的baseOffset=23,日志段4的baseOffset=30,如下图,则收集可删除日志段集合deletableSegments的过程为:
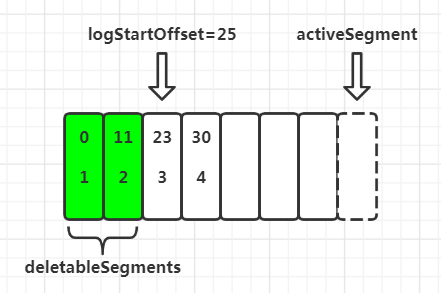
从头开始遍历每个日志段,日志段1的下一个日志段的baseOffset=11,小于logStartOffset,将日志段1放入deletableSegments
日志段2的下一个日志段的baseOffset=23,小于logStartOffset,将日志段2放入deletableSegments
日志段3的下一个日志段的baseOffset=30,大于logStartOffset,所以从日志段3开始,后面的所有日志段都不会放入deletableSegments
在上面三种保留策略对应删除日志段的方法中,都调用了 deleteOldSegments 方法:
private def deleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean, reason: String): Int = {lock synchronized {//获取可删除的日志段集合val deletable = deletableSegments(predicate)if (deletable.nonEmpty)info(s"Found deletable segments with base offsets [${deletable.map(_.baseOffset).mkString(",")}] due to $reason")//删除日志段文件deleteSegments(deletable)}}
获取可删除的日志段集合
private def deletableSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean): Iterable[LogSegment] = {//如果segments集合为空 或者 高水位为空 则返回空序列if (segments.isEmpty || replicaHighWatermark.isEmpty) {Seq.empty} else {//获取高水位值val highWatermark = replicaHighWatermark.get//定义保存可删除日志段的数组val deletable = ArrayBuffer.empty[LogSegment]//获取segments集合中的第一个key-valuevar segmentEntry = segments.firstEntry// 从具有最小起始位移值的日志段对象开始遍历,直到满足以下条件之一便停止遍历:// 1. 测定条件函数predicate = false// 2. 扫描到包含Log对象高水位值所在的日志段对象// 3. 最新的日志段对象不包含任何消息// 最新日志段对象是segments中Key值最大对应的那个日志段,也就是我们常说的Active Segment。完全为空的Active Segment如果被允许删除,后面还要重建它// 故代码这里不允许删除大小为空的Active Segment。// 在遍历过程中,同时不满足以上3个条件的所有日志段都是可以被删除的!while (segmentEntry != null) {//获取第一个键值对的value值,即LogSegment对象val segment = segmentEntry.getValue//如果存在key比segment的key还大的Entryval nextSegmentEntry = segments.higherEntry(segmentEntry.getKey)//根据是否存在key比segment的key还大的Entry,定义三元组val (nextSegment, upperBoundOffset, isLastSegmentAndEmpty) = if (nextSegmentEntry != null)//如果存在(nextSegmentEntry.getValue, nextSegmentEntry.getValue.baseOffset, false)else//不存在(null, logEndOffset, segment.size == 0)if (highWatermark >= upperBoundOffset && predicate(segment, Option(nextSegment)) && !isLastSegmentAndEmpty) {//将日志段添加到可删除数组deletable += segment//更新 segmentEntry 变量segmentEntry = nextSegmentEntry} else {segmentEntry = null}}//返回可删除的日志段数组deletable}}
测定条件函数predicate = false 扫描到包含Log对象高水位值所在的日志段对象 最新的日志段对象不包含任何消息 ,即:segment.size=0
删除日志段文件,返回删除的日志段个数
private def deleteSegments(deletable: Iterable[LogSegment]): Int = {maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {//要删除的日志段数量val numToDelete = deletable.sizeif (numToDelete > 0) {// 如果需要删除所有的日志段文件,则需要先创建一个空的日志段if (segments.size == numToDelete)//滚动生成新的日志段roll()lock synchronized {checkIfMemoryMappedBufferClosed()//便利可删除日志段数组,依次删除日志段deletable.foreach(deleteSegment)//是否更新Log日志的起始偏移量maybeIncrementLogStartOffset(segments.firstEntry.getValue.baseOffset)}}numToDelete}
最终通过deleteSegment方法将日志段删除:
private def deleteSegment(segment: LogSegment) {info(s"Scheduling log segment [baseOffset ${segment.baseOffset}, size ${segment.size}] for deletion.")lock synchronized {//将日志段对象从跳表集合中移除segments.remove(segment.baseOffset)//异步删除asyncDeleteSegment(segment)}}
删除操作分两步:
调用Map的remove方法将指定的LogSegment对象从segments集合中移除
将日志段对应的文件(日志和索引)增加 .delete 后缀,然后通过调度器调度 "delete-file" 延迟任务异步删除日志段对应的文件
c. 修改
segments通过Map的put方法实现修改,如果指定的key存在,则相当于修改,如果不存在,则是添加。
segments的查询主要通过 ConcurrentSkipListMap 的现成方法:
segments.firstEntry:获取第一个日志段对象的键值对;
segments.lastEntry:获取最后一个日志段对象,即 Active Segment 对应的键值对;
segments.higherEntry:获取第一个起始位移值≥给定 Key 值的日志段对象的键值对;
segments.floorEntry:获取最后一个起始位移值≤给定 Key 值的日志段对象的键值对。
比如 logSegments(from:Long,to:Long)方法,其中就使用了floorKey()。这个方法的作用是:返回包含偏移量 [from,to) 的所有日志段的集合。
def logSegments(from: Long, to: Long): Iterable[LogSegment] = {lock synchronized {val view = Option(segments.floorKey(from)).map { floor =>if (to < floor)throw new IllegalArgumentException(s"Invalid log segment range: requested segments in $topicPartition " +s"from offset $from mapping to segment with base offset $floor, which is greater than limit offset $to")segments.subMap(floor, to)}.getOrElse(segments.headMap(to))view.values.asScala}}
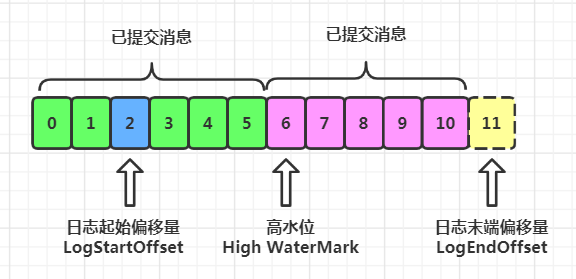
①LogEndOffset:下一条待插入消息的偏移量,简称LEO。这里注意
LEO永远指向下一条待插入消息的偏移量,所以LEO值上面始终是没有消息的
LogStartOffset为什么不是从0开始?因为同一个Topic会分成多个分区,消息通过分区器路由到不同的分区,而Log是和分区对应的,所以当前分区第一条消息的偏移量不一定为0
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
在初始化Log对象的时候,通过加载日志段来获取nextOffset值,然后封装成LogOffsetMetadata对象:
locally {...//TODO 步骤三:加载所有日志段对象,返回下一条待写入消息的偏移量val nextOffset = loadSegments()//TODO 步骤四:更新nextOffsetMetadata 和 LogStartOffsetnextOffsetMetadata = new LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))logStartOffset = math.max(logStartOffset, segments.firstEntry.getValue.baseOffset)...}
同时,Log类中还提供了更新LEO对象的方法(注意这里是通过LogOffsetMetadata实例对象来保存LEO的,而不是只保存一个Long类型的值):
private def updateLogEndOffset(messageOffset: Long) {nextOffsetMetadata = new LogOffsetMetadata(messageOffset, activeSegment.baseOffset, activeSegment.size)}
Log 对象初始化时:当 Log 对象初始化时,必须要创建一个 LEO 对象,并对其进行初始化。 写入新消息时:当不断向 Log 对象插入新消息时,LEO 值就像一个指针一样,需要不停地向右移动,也就是不断地增加。 Log 对象发生日志切分(Log Roll)时:一旦发生日志切分,说明 Log 对象切换了 Active Segment,那么,LEO 中的起始位移值和段大小数据都要被更新,因此,在进行这一步操作时,必须要更新 LEO 对象。 日志截断(Log Truncation)时:日志中的部分消息被删除了,自然可能导致 LEO 值发生变化,从而要更新 LEO 对象。
②logStartOffset:日志的起始偏移量,但这里不可以简称为LSO,LSO指Log Stable Offset,属于 Kafka 事务的概念。
logStartOffset = math.max(logStartOffset, segments.firstEntry.getValue.baseOffset)
更新logStartOffset的方法:
def maybeIncrementLogStartOffset(newLogStartOffset: Long) {// We don't have to write the log start offset to log-start-offset-checkpoint immediately.// The deleteRecordsOffset may be lost only if all in-sync replicas of this broker are shutdown// in an unclean manner within log.flush.start.offset.checkpoint.interval.ms. The chance of this happening is low.maybeHandleIOException(s"Exception while increasing log start offset for $topicPartition to $newLogStartOffset in dir ${dir.getParent}") {lock synchronized {checkIfMemoryMappedBufferClosed()if (newLogStartOffset > logStartOffset) {info(s"Incrementing log start offset to $newLogStartOffset")logStartOffset = newLogStartOffsetleaderEpochCache.foreach(_.truncateFromStart(logStartOffset))producerStateManager.truncateHead(logStartOffset)updateFirstUnstableOffset()}}}}
更新logStartOffset值的时机:
Log 对象初始化时:Log 对象初始化时要给 LogStartOffset 赋值,一般赋值为第一个日志段的起始偏移量
日志截断时:一旦日志中的部分消息被删除,可能会导致 LogStartOffset 发生变化,因此有必要更新该值。
Follower 副本同步时:一旦 Leader 副本的 Log 对象的 LogStartOffset 值发生变化。为了维持和 Leader 副本的一致性,Follower 副本也需要尝试去更新该值。
删除日志段时:这个和日志截断是类似的。凡是涉及消息删除的操作都有可能导致 LogStartOffset 值的变化。
删除消息时:这里应该是先更新logStartOffset,然后删除消息。在 Kafka 中,删除消息就是通过抬高 LogStartOffset 值来实现的,因此,删除消息时必须要更新该值。
③replicaHighWatermark:分区的高水位值。高水位值的管理比较复杂,后面单独进行分析。
这篇主要分析了Log对象对 日志段的管理 和 关键偏移量的管理:
1.日志段的管理主要是针对集合segments的操作:
新增:addSegment
删除:deleteSegment。其中日志段的保留策略有三种:
基于时间的保留策略
基于日志大小的保留策略
基于日志起始偏移量的保留策略
修改:通过 Map.put 实现,如果集合中不存在就是新增,已存在就是修改
查询:通过 ConcurrentSkipListMap 的现成方法实现。如:firstEntry、lastEntry等
2.关键偏移量的管理:
LogEndOffset:简称LEO,表示下一条待插入消息的偏移量。对应的LEO对象的更新时机有:
Log对象初始化时
写入消息时
发生日志段滚动时(roll)
日志截断时
LogStartOffset:日志的起始偏移量。更新的时机有:
Log对象初始化时
日志截断时
follower副本同步时
删除日志段时
删除日志时
参考资料:
《深入理解Kafka核心设计与实践原理》
极客时间《Kafka核心源码解读》专栏
