




一、场景分析
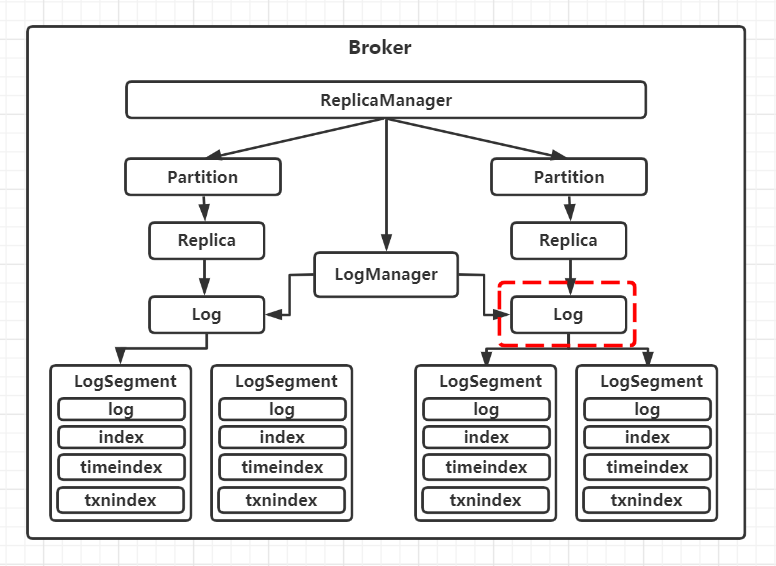
前面提到,Kafka每个分区在磁盘上对应一个物理目录,同时对应一个Log对象。在进行数据存储时,一个分区的数据会划分成多个日志段进行存储,多个日志段由分区对应的Log对象进行管理。
二、图示说明
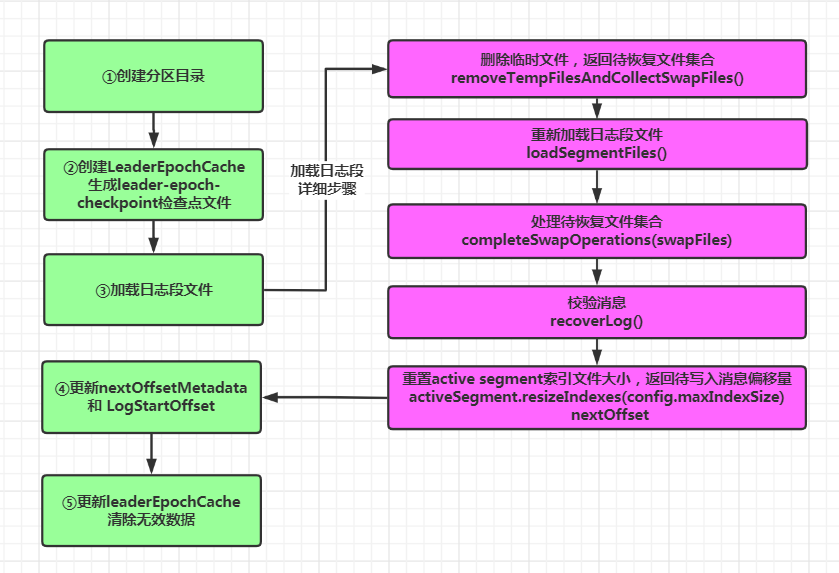
整个日志对象的初始化可以分成五个步骤,其中以第三个步骤:加载日志段文件 最为复杂
三、源码分析
LogAppendInfo(C):保存了一组待写入消息的各种元数据信息。比如:这组消息中第一条消息的偏移量、最后一条消息的偏移量、这组消息中最大的时间戳、接收消息的压缩类型、写入本地存储时的压缩类型等等
LogAppendInfo(O):伴生对象,定义了一些工厂方法,用于创建特定的LogAppendInfo实例对象
Log(C):管理服务端存储的各种操作
日志段管理:滚动生成新日志段、组织并管理分区下的所有日志段等
读写操作:进行日志的读写
关键偏移量管理:如LogStartOffset、LEO等
高水位操作管理:
Log(O):定义了Log伴生类的工厂方法、一些常量等
RollParams(C):定义用于控制日志段是否切分(Roll)的数据结构
RollParams(O):定义对应伴生类的工厂方法
LogMetricNames:定义了Log对象的监控指标
LogOffsetSnapshot:封装分区所有偏移量元数据的容器类
LogReadInfo:封装读取日志返回的数据及其元数据
CompletedTxn:记录已完成事务的元数据,主要用于构建事务索引
2. Log类的定义:
class Log(@volatile var dir: File,//即主题分区的路径,每个主题的每个分区对应一个log对象@volatile var config: LogConfig,@volatile var logStartOffset: Long,//当前分区日志的起始偏移量@volatile var recoveryPoint: Long,scheduler: Scheduler,brokerTopicStats: BrokerTopicStats,val time: Time,val maxProducerIdExpirationMs: Int,val producerIdExpirationCheckIntervalMs: Int,val topicPartition: TopicPartition,val producerStateManager: ProducerStateManager,logDirFailureChannel: LogDirFailureChannel) extends Logging with KafkaMetricsGroup {...}
这里重点关注如下几个属性:
@volatile var dir: File:分区对应的路径,当配置了log.dirs后,每个分区会在该目录下创建一个子目录。被volatile关键字修饰,说明该属性的值是易变的,且变化对其他线程可见,下同。 @volatile var logStartOffset: Long:该分区消息的起始偏移量 topicPartition:分区对象 recoveryPoint:上一次flush刷写磁盘时消息的最大偏移量
除此之外,Log内部还定义了一些关键的变量:
@volatile private var isMemoryMappedBufferClosed = false
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
@volatile private var replicaHighWatermark: Option[Long] = None
d. 保存了log下所有日志段的信息,是一个map,key是日志段的起始位移值,value是日志段对象LogSegment本身.这里使用了ConcurrentSkipListMap跳表的结构,可以利用该结构提供的线程安全以及支持排序的方法.
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
e. 是一个缓存类数据,里面保存了分区 Leader 的 Epoch 值与对应起始位移值的映射关系.Leader epoch 从0.11版本开始引入,用来判断出现 Failure 时是否执行日志截断操作(Truncation)
@volatile var leaderEpochCache: Option[LeaderEpochFileCache] = None
f. 消息格式的版本。Kafka的消息一共经历V0、V1、V2三个版本,从0.11开始使用V2版本
def recordVersion: RecordVersion = config.messageFormatVersion.recordVersion
3. Log对象的初始化流程
locally {//记录起始时间val startMs = time.milliseconds//TODO 步骤一:创建分区日志路径对应的目录Files.createDirectories(dir.toPath)//TODO 步骤二:初始化LeaderEpochCache,生成检查点文件和创建LeaderEpochCache对象initializeLeaderEpochCache()//TODO 步骤三:加载所有日志段对象,返回下一条待写入消息的偏移量val nextOffset = loadSegments()//TODO 步骤四:更新nextOffsetMetadata 和 LogStartOffsetnextOffsetMetadata = new LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))logStartOffset = math.max(logStartOffset, segments.firstEntry.getValue.baseOffset)//TODO 步骤五:更新leaderEpochCache,清除无效数据leaderEpochCache.foreach(_.truncateFromStart(logStartOffset))if (!producerStateManager.isEmpty)throw new IllegalStateException("Producer state must be empty during log initialization")loadProducerState(logEndOffset, reloadFromCleanShutdown = hasCleanShutdownFile)info(s"Completed load of log with ${segments.size} segments, log start offset $logStartOffset and " +s"log end offset $logEndOffset in ${time.milliseconds() - startMs} ms")}
①创建分区对应的目录。假如配置的log.dirs 为 data/kafka/logs ,Topic 为 test,且只有1个分区,那么该分区日志的路径就是:/data/kafka/logs/test-0,即dir=/data/kafka/logs/test-0
Files.createDirectories(dir.toPath)
②初始化LeaderEpochCache对象,并在上面生成的分区目录下创建检查点文件:leader-epoch-checkpoint。
initializeLeaderEpochCache()
private def initializeLeaderEpochCache(): Unit = lock synchronized {//创建leaderEpoch检查点文件对应的File对象。路径:分区路径/leader-epoch-checkpointval leaderEpochFile = LeaderEpochCheckpointFile.newFile(dir)//创建 LeaderEpochFileCache的方法def newLeaderEpochFileCache(): LeaderEpochFileCache = {//创建检查点文件val checkpointFile = new LeaderEpochCheckpointFile(leaderEpochFile, logDirFailureChannel)//生成LeaderEpochFileCache对象new LeaderEpochFileCache(topicPartition, logEndOffset _, checkpointFile)}//如果是低于V2版本格式的日志,leaderEpochCache最终设置为None,因为0.11版本才引入epoch,该版本对应的日志格式为V2if (recordVersion.precedes(RecordVersion.V2)) {//如果leaderEpochFile对象已存在,返回一个LeaderEpochFileCache对象,否则返回Noneval currentCache = if (leaderEpochFile.exists())Some(newLeaderEpochFileCache())elseNoneif (currentCache.exists(_.nonEmpty))warn(s"Deleting non-empty leader epoch cache due to incompatible message format $recordVersion")//如果leaderEpochFile对象对应的文件已存在,删除该文件Files.deleteIfExists(leaderEpochFile.toPath)leaderEpochCache = None//对于V2格式的日志,leaderEpochCache最终指向一个新创建的LeaderEpochFileCache对象} else {//生成LeaderEpochFileCache对象leaderEpochCache = Some(newLeaderEpochFileCache())}}
主要分为三个步骤:
创建检查点文件
//创建leaderEpoch检查点文件对应的File对象。路径:分区路径/leader-epoch-checkpointval leaderEpochFile = LeaderEpochCheckpointFile.newFile(dir)
校验日志格式,判断是否是V2的版本。precedes方法判断消息格式的版本是否是早于V2,是则返回true:
if (recordVersion.precedes(RecordVersion.V2))
如果是早于V2的版本,则leaderEpochCache变量设置为None;否则,创建一个LeaderEpochFileCache对象,并赋值给leaderEpochCache变量
//生成LeaderEpochFileCache对象leaderEpochCache = Some(newLeaderEpochFileCache())
③加载所有的日志段文件:在内存中生成对应的LogSegment对象,并返回下一条待写入消息的偏移量:
val nextOffset = loadSegments()
private def loadSegments(): Long = {//步骤一:删除临时文件(包括.cleaned、.deleted 文件等),返回待恢复的文件集合,这些文件都是 xxx.log.swap 格式val swapFiles = removeTempFilesAndCollectSwapFiles()//步骤二:retryOnOffsetOverflow {//关闭所有的日志段对应的日志和索引文件logSegments.foreach(_.close())//清理segments集合中的日志段对象segments.clear()//重新加载日志段文件loadSegmentFiles()}//步骤三:处理有效的.swap文件,即将有效的swap文件对应的日志段添加到Log 的 segments 集合中completeSwapOperations(swapFiles)if (!dir.getAbsolutePath.endsWith(Log.DeleteDirSuffix)) {val nextOffset = retryOnOffsetOverflow {//步骤四:recoverLog()}//设置active 日志段 对应的索引文件大小为 10MactiveSegment.resizeIndexes(config.maxIndexSize)//返回下一条待写入消息的偏移量nextOffset//如果目录以 -delete 结尾} else {if (logSegments.isEmpty) {addSegment(LogSegment.open(dir = dir,baseOffset = 0,config,time = time,fileAlreadyExists = false,initFileSize = this.initFileSize,preallocate = false))}0}}
val swapFiles = removeTempFilesAndCollectSwapFiles()
private def removeTempFilesAndCollectSwapFiles(): Set[File] = {// 在方法内部定义一个名为deleteIndicesIfExist的方法,用于删除日志文件对应的索引文件//该方法会在后面被调用def deleteIndicesIfExist(baseFile: File, suffix: String = ""): Unit = {info(s"Deleting index files with suffix $suffix for baseFile $baseFile")val offset = offsetFromFile(baseFile)Files.deleteIfExists(Log.offsetIndexFile(dir, offset, suffix).toPath)Files.deleteIfExists(Log.timeIndexFile(dir, offset, suffix).toPath)Files.deleteIfExists(Log.transactionIndexFile(dir, offset, suffix).toPath)}//定义几个保存不同类型文件的集合var swapFiles = Set[File]()//待恢复文件的集合var cleanFiles = Set[File]()//待删除文件的集合var minCleanedFileOffset = Long.MaxValue// 遍历分区日志路径下的所有文件for (file <- dir.listFiles if file.isFile) {// 如果不可读,直接抛出IOExceptionif (!file.canRead)throw new IOException(s"Could not read file $file")val filename = file.getName// 如果以.deleted结尾if (filename.endsWith(DeletedFileSuffix)) {debug(s"Deleting stray temporary file ${file.getAbsolutePath}")//说明是上次Failure遗留下来的文件,直接删除Files.deleteIfExists(file.toPath)// 如果以.cleaned结尾,表示在执行日志压缩过程中宕机,文件中的数据状态不明确,无法正确恢复的文件。} else if (filename.endsWith(CleanedFileSuffix)) {//判断该文件名中的偏移量和minCleanedFileOffset 的大小,如果较小,则更新 minCleanedFileOffsetminCleanedFileOffset = Math.min(offsetFromFileName(filename), minCleanedFileOffset)//将该文件加入待删除的文件集合cleanFiles += file// 如果以.swap结尾的文件,则说明日志压缩过程已完成,但是在执行交换过程中宕机// 1. 如果 swap 文件是 log 文件,则删除对应的 index 文件,稍后 swap 操作会重建索引// 2. 如果 swap 文件是 index 文件,则直接删除,后续加载 log 文件时会重建索引} else if (filename.endsWith(SwapFileSuffix)) {//去掉文件名中的.swap后缀val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))info(s"Found file ${file.getAbsolutePath} from interrupted swap operation.")// 如果该.swap文件原来是索引文件if (isIndexFile(baseFile)) {//删除原索引文件,之后会重建索引文件deleteIndicesIfExist(baseFile)//如果该.swap文件原来是日志文件} else if (isLogFile(baseFile)) {//删除原日志文件对应的索引文件,之后会重建索引文件deleteIndicesIfExist(baseFile)//加入待恢复的.swap文件集合中,这个集合中保存的都是 xxxx.log.swap 文件swapFiles += file}}}// 从待恢复swap集合中找出那些起始位移值大于minCleanedFileOffset值的文件,直接删掉这些无效的.swap文件val (invalidSwapFiles, validSwapFiles) = swapFiles.partition(file => offsetFromFile(file) >= minCleanedFileOffset)invalidSwapFiles.foreach { file =>debug(s"Deleting invalid swap file ${file.getAbsoluteFile} minCleanedFileOffset: $minCleanedFileOffset")val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))//删除日志对应的索引文件deleteIndicesIfExist(baseFile, SwapFileSuffix)//删除日志文件Files.deleteIfExists(file.toPath)}//清除所有待删除文件集合中的文件cleanFiles.foreach { file =>debug(s"Deleting stray .clean file ${file.getAbsolutePath}")Files.deleteIfExists(file.toPath)}//最后返回当前有效的.swap文件集合validSwapFiles}
deleted 文件 :标识需要被删除的 log 文件和 index 文件。 cleaned 文件 :在执行日志压缩过程中宕机,文件中的数据状态不明确,无法正确恢复的文件。 swap 文件 :完成执行日志压缩后的文件,但是在替换原文件时宕机。
这里有一段不太好理解,单独进行分析:
// 从待恢复swap集合中找出那些起始位移值大于minCleanedFileOffset值的文件,直接删掉这些无效的.swap文件val (invalidSwapFiles, validSwapFiles) = swapFiles.partition(file => offsetFromFile(file) >= minCleanedFileOffset)invalidSwapFiles.foreach { file =>debug(s"Deleting invalid swap file ${file.getAbsoluteFile} minCleanedFileOffset: $minCleanedFileOffset")val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))//删除日志对应的索引文件deleteIndicesIfExist(baseFile, SwapFileSuffix)//删除日志文件Files.deleteIfExists(file.toPath)}
在分析之前,先简单介绍一下日志压缩。日志的清理策略有delete 和 compact 两种,在进行compact日志压缩时,会将保留的消息先写到一个.cleaned文件中,如:xxx.log.cleaned。当压缩过后,会将后缀修改为.swap。最后删除原始日志文件后,再去掉.swap后缀,形成xxx.log日志文件。
那么这里代码的逻辑是,如果.swap文件名中的起始偏移量大于minCleanedFileOffset,则这些.swap文件是不合法的,需要删除。这里可能的原因是:执行日志压缩是按照偏移量顺序进行的,既然偏移量为minCleanedFileOffset的日志对应的压缩还未完成,那么后面日志文件进行压缩形成的.swap文件可能是不完整的,所以会进行删除。由于原始日志还在,可以后续继续进行压缩。
完成了对异常文件的处理,下面接着处理正常的日志和索引文件。
retryOnOffsetOverflow {//关闭所有的日志段对应的日志和索引文件logSegments.foreach(_.close())//清理segments集合中的日志段对象segments.clear()//重新加载日志段文件loadSegmentFiles()}
这里重点看loadSegmentFiles()方法:
private def loadSegmentFiles(): Unit = {//遍历分区目录下的文件for (file <- dir.listFiles.sortBy(_.getName) if file.isFile) {//如果是索引文件if (isIndexFile(file)) {//获取索引文件名中的起始偏移量val offset = offsetFromFile(file)//获取起始偏移量对应的日志文件,如果日志文件不存在,则删除该索引文件val logFile = Log.logFile(dir, offset)if (!logFile.exists) {warn(s"Found an orphaned index file ${file.getAbsolutePath}, with no corresponding log file.")Files.deleteIfExists(file.toPath)}//如果是日志文件} else if (isLogFile(file)) {//获取日志文件名中的起始偏移量val baseOffset = offsetFromFile(file)//标记日志对应的时间戳索引文件是否存在,如果存在为falseval timeIndexFileNewlyCreated = !Log.timeIndexFile(dir, baseOffset).exists()//构建对应的LogSegment对象val segment = LogSegment.open(dir = dir,baseOffset = baseOffset,config,time = time,fileAlreadyExists = true)//如果偏移量索引文件存在,看是否需要重建对应的时间戳索引文件,并创建已中止事务索引文件//如果偏移量索引文件不存在,则抛异常try segment.sanityCheck(timeIndexFileNewlyCreated)catch {case _: NoSuchFileException =>error(s"Could not find offset index file corresponding to log file ${segment.log.file.getAbsolutePath}, " +"recovering segment and rebuilding index files...")recoverSegment(segment)case e: CorruptIndexException =>warn(s"Found a corrupted index file corresponding to log file ${segment.log.file.getAbsolutePath} due " +s"to ${e.getMessage}}, recovering segment and rebuilding index files...")recoverSegment(segment)}//将这个日志段对象添加到segments集合中addSegment(segment)}}}
如果是索引文件,看对应的日志文件是否存在,不存在则删除该索引文件 如果是日志文件,则构建对应的LogSegment对象 如果对应的偏移量索引文件存在,则看是否需要重建时间戳索引文件。并创建已中止事务索引文件 如果对应的偏移量索引文件不存在,则直接抛异常 将生成的LogSegment对象放入Log对象的segments集合
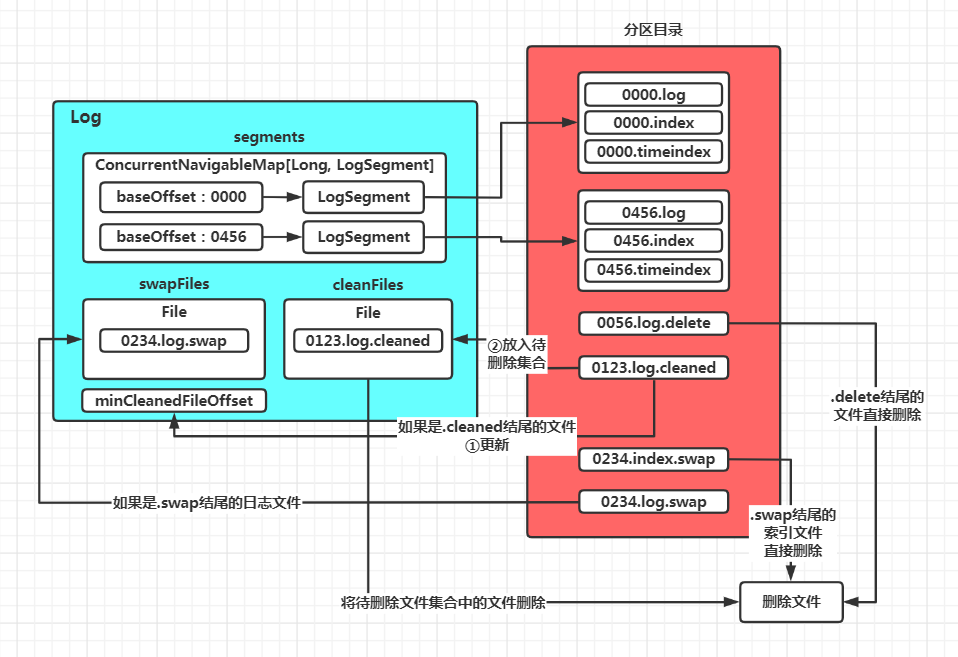
第三步:处理有效的.swap后缀的日志文件,将压缩后的LogSegment对象放入segments集合,并集合中移除压缩前的LogSegment对象和删除对应的日志和索引文件
completeSwapOperations(swapFiles)
private def completeSwapOperations(swapFiles: Set[File]): Unit = {遍历文件for (swapFile <- swapFiles) {去掉.swap 后缀val logFile = new File(CoreUtils.replaceSuffix(swapFile.getPath, SwapFileSuffix, ""))获取起始偏移量val baseOffset = offsetFromFile(logFile)/创建LogSegment对象val swapSegment = LogSegment.open(swapFile.getParentFile,baseOffset = baseOffset,config,time = time,fileSuffix = SwapFileSuffix)info(s"Found log file ${swapFile.getPath} from interrupted swap operation, repairing.")//恢复日志段,重建索引文件,并校验日志中消息的合法性recoverSegment(swapSegment)// 查找 swapSegment 获取 [baseOffset, nextOffset] 区间对应的日志压缩前的 LogSegment 集合,// 区间中的 LogSegment 数据都压缩到了 swapSegment 中val oldSegments = logSegments(swapSegment.baseOffset, swapSegment.readNextOffset).filter { segment =>segment.readNextOffset > swapSegment.baseOffset}//将压缩前的日志段对应的LogSegment对象从segments集合中移除,并删除对应的日志和索引文件// 然后将新创建的swapSegment日志段添加到Log对象的segments中,最后移除文件的.swap 后缀replaceSegments(Seq(swapSegment), oldSegments.toSeq, isRecoveredSwapFile = true)}}
第四步:校验加载的数据,并返回下一条待写入消息的偏移量:
if (!dir.getAbsolutePath.endsWith(Log.DeleteDirSuffix)) {val nextOffset = retryOnOffsetOverflow {//处理 broker 节点异常关闭导致的数据异常,需要验证 [recoveryPoint, Long.MaxValue] 中的所有消息,并移除验证失败的消息recoverLog()}//设置active 日志段 对应的索引文件大小为 10MactiveSegment.resizeIndexes(config.maxIndexSize)//返回下一条待写入消息的偏移量nextOffset//如果目录以 -delete 结尾} else {if (logSegments.isEmpty) {addSegment(LogSegment.open(dir = dir,baseOffset = 0,config,time = time,fileAlreadyExists = false,initFileSize = this.initFileSize,preallocate = false))}0}
private def recoverLog(): Long = {//判断是否存在.kafka_cleanshutdown 文件,如果存在则说明broker异常关闭//需要对recoveryPoint恢复点之后的数据进行校验,如果不完整则丢弃if (!hasCleanShutdownFile) {// okay we need to actually recover this log//获取包含恢复点之后消息的 日志段对象集合val unflushed = logSegments(this.recoveryPoint, Long.MaxValue).iteratorwhile (unflushed.hasNext) {val segment = unflushed.nextinfo(s"Recovering unflushed segment ${segment.baseOffset}")val truncatedBytes =try {//恢复日志段recoverSegment(segment, leaderEpochCache)} catch {case _: InvalidOffsetException =>val startOffset = segment.baseOffsetwarn("Found invalid offset during recovery. Deleting the corrupt segment and " +s"creating an empty one with starting offset $startOffset")segment.truncateTo(startOffset)}//如果有无效的消息,直接删除所有的未刷写日志段if (truncatedBytes > 0) {// we had an invalid message, delete all remaining logwarn(s"Corruption found in segment ${segment.baseOffset}, truncating to offset ${segment.readNextOffset}")//删除日志段unflushed.foreach(deleteSegment)}}}//执行完之后,如果日志段集合不为空if (logSegments.nonEmpty) {//获取active 日志段的LEOval logEndOffset = activeSegment.readNextOffset//如果LEO 比 日志的 LogStartOffset 还小,则删除所有日志段if (logEndOffset < logStartOffset) {warn(s"Deleting all segments because logEndOffset ($logEndOffset) is smaller than logStartOffset ($logStartOffset). " +"This could happen if segment files were deleted from the file system.")logSegments.foreach(deleteSegment)}}//执行完上面的逻辑,如果日志段集合已经为空if (logSegments.isEmpty) {//至少要有一个active 日志段,上面全部删除了,所以要创建一个新的日志段,起始位移就是日志的LogStartOffset,然后放入segments集合addSegment(LogSegment.open(dir = dir,baseOffset = logStartOffset,config,time = time,fileAlreadyExists = false,initFileSize = this.initFileSize,preallocate = config.preallocate))}//更新恢复点信息,返回恢复点recoveryPoint = activeSegment.readNextOffsetrecoveryPoint}
nextOffsetMetadata = new LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))logStartOffset = math.max(logStartOffset, segments.firstEntry.getValue.baseOffset)
leaderEpochCache.foreach(_.truncateFromStart(logStartOffset))
总结:
创建分区目录 创建LeaderEpochCache对象并生成leader-epoch-checkpoint检查点文件 加载日志段文件,在内存中构建日志段对象 删除临时文件,返回待恢复文件集合 重新加载日志段文件,生成日志段对象并放入Log对应的集合segments 处理待恢复文件集合 校验消息,如果未加载任何日志段则生成一个空的日志段对象 重置active segment 的索引文件大小为10M,返回下一条待插入消息偏移量 更新nextOffsetMetadata 和 LogStartOffset 更新leaderEpochCache,清除无效数据
