背景:最近爬取了一些网页的书籍数据,保存在MySQL,后续进行整理时,创建了一张结构相同的表,然后通过insert into new_table select ... from old_table where ...的方式批量插入(插入字段不包含自增主键id),第一次正常插入了665条数据,在进行第二次插入时,发现自增主键id的值没有从666开始,而是从1024开始,如下图:重试了一次发现结果一样。为什么会这样?
在之前的印象里,插入数据导致自增id不连续的原因有两种:- 字段设置唯一索引,插入的数据该字段重复导致插入失败,后续正常插入的数据自增主键与之前数据的自增主键不连续;
- 事务中插入数据,之后事务回滚,后续正常插入数据的自增主键与之前数据的自增主键不连续;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`b` int(11) DEFAULT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT charset = utf8;
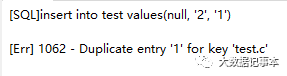
insert into test values(null, '1', '1')
然后执行 show create table test 命令,可以看到表定义里面出现了一个 AUTO_INCREMENT=2,表示下一次插入数据时,如果需要自动生成自增值,会生成 id=2。CREATE TABLE `test` (
`id` int NOT NULL AUTO_INCREMENT,
`b` varchar(10) DEFAULT NULL,
`c` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
inset into test values(null, '2', '1')
当插入第二条数据时,由于字段c设置了唯一索引,所以上面这条插入语句执行会报错,如下图:inset into test values(null, '2', '2')
begin;
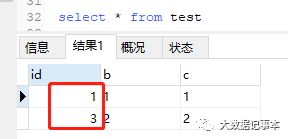
insert into test values(null, '3', '3')
select * from test;
rollback;
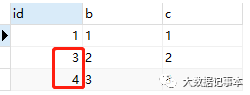
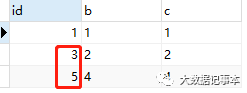
这时再插入一条新数据时,发现自增主键也是不连续的,如下图:insert into test values(null, '4', '4')
再来看我们遇到的问题,发现并不是这两种情况,那么原因到底是什么?最后在极客的《MySQL实战45讲》专栏找到了答案。 MySQL里面有一种锁叫自增锁,是在申请自增主键值的时候填加的锁,但这种锁并不是事务锁,在 MySQL 5.0 版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放。 显然,这样设计会影响并发度。MySQL 5.1.22 版本引入了一个新策略,新增参数 innodb_autoinc_lock_mode,默认值是 1。(8.x版本这个参数的默认值已经改为了2)- 这个参数的值被设置为 0 时,表示采用之前 MySQL 5.0 版本的策略,即语句执行结束后才释放锁;
- 这个参数的值被设置为 1 时:普通 insert 语句,自增锁在申请之后就马上释放;类似 insert … select 这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
- 这个参数的值被设置为 2 时,所有的申请自增主键的动作都是申请后就释放锁。
那么在上面的情况中,为什么自增主键会从665直接跳到1024呢? 这是因为,在批量插入数据时,如:insert … select、replace … select 和 load data 语句,这时不确定要插入多少条数据,所以无法一次性准确地申请对应个数的id,那么此时MySQL 有一个批量申请自增 id 的策略:- 语句执行过程中,第一次申请自增 id,会分配 1 个;
- 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
- 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
- 依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
回到我们的例子,由于第一次插入的数据为665条,该insert语句依次申请了:1,2,4,8,16,32,64,128,256,512个自增id,一共1023个,所以此时AUTO_IINCREMENT=1024,下次再插入数据时,id值就从1024开始。 注意:通过insert into table(col1,col2) values(a,b),(b,c)...这种一次插入多条数据时除外,因为这种方式插入多条数据时,申请id的个数是可以准确计算的。 我们可以通过show create table table_name 命令查看某个表当前的AUTO_IINCREMENT值,那么是不是这个自增值和表结构定义保存在一起?其实并不是,表结构定义保存在后缀为.frm的文件中,而自增值并不在。- InnoDB 引擎的自增值,其实是保存在了内存里,并且到了 MySQL 8.0 版本后,才有了“自增值持久化”的能力,也就是才实现了“如果发生重启,表的自增值可以恢复为 MySQL 重启前的值”,具体情况是:
- 在 MySQL 5.7 及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值 max(id),然后将 max(id)+1 作为这个表当前的自增值。举例来说,如果一个表当前数据行里最大的 id 是 10,AUTO_INCREMENT=11。这时候,我们删除 id=10 的行,AUTO_INCREMENT 还是 11。但如果马上重启实例,重启后这个表的 AUTO_INCREMENT 就会变成 10。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
- 在 MySQL 8.0 版本,将自增值的变更记录在了 redo log 中,重启的时候依靠 redo log 恢复重启之前的值。
在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下: 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段; 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。 如果 X≥Y,就需要把当前自增值修改为新的自增值。 新的自增值生成算法是:从 auto_increment_offset 开始,以 auto_increment_increment 为步长,持续叠加,直到找到第一个大于 X 的值,作为新的自增值。其中,auto_increment_offset 和 auto_increment_increment 是两个系统参数,分别用来表示自增的初始值和步长,默认值都是 1。 注意:这里要避免一个误区,上面提到插入数据的值如果比自增值小,那么自增值不变。这里不是自增主键,主键是不可以插入一个相同的值的。而普通int类型的字段设置自增属性,插入的值是可以重复的create table test1(
a int,
b int,
c int auto_increment,
key c(c) #(设置自增的字段必须建索引)
)engine=InnoDB default charset=utf8
当我们插入一条数据(1,1,1)时,自增值为2,当我们再次插入一条数据(2,2,1)时,由于插入数据的c的值为1,小于自增值2,自增值是不变的。 备注:在一些场景下,使用的就不全是默认值。比如,双 M 的主备结构里要求双写的时候,我们就可能会设置成 auto_increment_increment=2,让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数,避免两个库生成的主键发生冲突。 当 auto_increment_offset 和 auto_increment_increment 都是 1 的时候,新的自增值生成逻辑很简单,就是:如果准备插入的值 >= 当前自增值,新的自增值就是“准备插入的值 +1”;否则,自增值不变。 在这两个参数都设置为 1 的时候,自增主键 id 却不能保证是连续的,这是什么原因呢? 在上面演示唯一索引冲突导致插入数据失败而使自增值不连续的例子中,整个insert语句的执行流程如下:- 执行器调用 InnoDB 引擎接口写入一行,传入的这一行的值是 (null,'2','1');
- InnoDB 发现用户没有指定自增 id 的值,获取表 t 当前的自增值 2;
- 继续执行插入数据操作,由于已经存在 c='1' 的记录,所以报 Duplicate key error,语句返回。
可以看到,这个表的自增值改成 3,是在真正执行插入数据的操作之前。这个语句真正执行的时候,因为碰到唯一键 c 冲突,所以 id=2 这一行并没有插入成功,但也没有将自增值再改回去。 所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。 假设有两个并行执行的事务,在申请自增值的时候,为了避免两个事务申请到相同的自增 id,肯定要加锁,然后顺序申请。 假设事务 A 申请到了 id=2, 事务 B 申请到 id=3,那么这时候表 t 的自增值是 4,之后继续执行。 事务 B 正确提交了,但事务 A 出现了唯一键冲突。 如果允许事务 A 把自增 id 回退,也就是把表 t 的当前自增值改回 2,那么就会出现这样的情况:表里面已经有 id=3 的行,而当前的自增 id 值是 2。 接下来,继续执行的其他事务就会申请到 id=2,然后再申请到 id=3。这时,就会出现插入语句报错“主键冲突”。- 每次申请 id 之前,先判断表里面是否已经存在这个 id。如果存在,就跳过这个 id。但是,这个方法的成本很高。因为,本来申请 id 是一个很快的操作,现在还要再去主键索引树上判断 id 是否存在。
- 把自增 id 的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。
可见,这两个方法都会导致性能问题。造成这些麻烦的罪魁祸首,就是我们假设的这个“允许自增 id 回退”的前提导致的。 因此,InnoDB 放弃了这个设计,语句执行失败也不回退自增 id。也正是因为这样,所以才只保证了自增 id 是递增的,但不保证是连续的。4.为什么5.1.22引入innodb_autoinc_lock_mode参数时默认值为1,而8.0将默认值设改成了2 | |
| insert into test values(null,'1','1');insert into test values(null,'2','2');insert into test values(null,'3','3');insert into test values(null,'4','4'); |
|
| create table test2 like test; |
| insert into test2 values(null,'5','5'); | insert into test2(b,c) select b,c from test |
该例子在test表中插入了4条数据,然后创建了一个结构相同的test2表,然后两个session同时执行向表test2中插入数据的操作。 设想一下,如果 session B 是申请了自增值以后马上就释放自增锁,那么就可能出现这样的情况: session B 先插入了两个记录,(1,1,1)、(2,2,2);然后,session A 来申请自增 id 得到 id=3,插入了(3,5,5);之后,session B 继续执行,插入两条记录 (4,3,3)、 (5,4,4)。 就当前这个操作来看,似乎没有什么问题,但是binlog会怎么记录呢?由于两个 session 是同时执行插入数据命令的,所以 binlog 里面对表 t2 的更新日志只有两种情况:要么先记 session A 的,要么先记 session B 的。 但不论是哪一种,这个 binlog 拿去从库执行,或者用来恢复临时实例,备库和临时实例里面,session B 这个语句执行出来,生成的结果里面,id 都是连续的。这时,这个库就发生了数据不一致。 这个问题出现的原因是:原库 session B 的 insert 语句,生成的 id 不连续。这个不连续的 id,用 statement 格式的 binlog 来串行执行,是执行不出来的。让原库的批量插入数据语句,固定生成连续的 id 值。所以,自增锁直到语句执行结束才释放,就是为了达到这个目的。由于在5.1.22版本logbin_format参数的默认值是statement,所以对应新增的innodb_autoinc_lock_mode参数的默认值为1。
另一种思路是,在 binlog 里面把插入数据的操作都如实记录进来,到备库执行的时候,不再依赖于自增主键去生成。这种情况,其实就是 innodb_autoinc_lock_mode 设置为 2,同时 binlog_format 设置为 row。在8.x版本,由于binlog_format参数的默认值已经改为了row,所以对应innodb_autoinc_lock_mode参数的默认值也就改成了2.
MySQL插入数据导致自增主键不连续的原因有3种:插入数据和原数据唯一索引冲突导致插入失败,自增值不回滚。
事务中插入数据,事务回滚导致插入失败,自增值不回滚。
批量插入时由于不确定插入的数据条数,多次批量申请自增值导致的不连续。
https://time.geekbang.org/column/article/80531?utm_source=pinpaizhuanqu&utm_medium=geektime&utm_campaign=guanwang&utm_term=guanwang&utm_content=0511