




点击上方👆蓝字关注我们!

本文整理自火山引擎开发者社区 Meetup 第五期演讲,主要介绍了字节跳动智能音频信号处理技术在高质量音频采集、声场重建和智能语音交互等场景中的应用。
音频信号处理发展趋势
最基础的部分是算法,包括自适应滤波器、阵列信号处理以及心理声学和深度学习等算法技术。 算法基础可以保证上层关键技术组件的技术演进。比如自适应滤波器理论的发展大大加速了回声消除在各业务场景中的应用;阵列信号处理技术则确保了声源定位以及波束形成在消费电子以及音视频创作中的效果。深度学习和心理声学技术的发展也大大加速了多模态音视频信号处理技术的发展,保证了声音效果。 有了这些基础就可以为上层业务,比如声场还原、人机交互、音视频处理等提供更高质量的音频。
智能音频信号处理在高质量音频采集中的应用
音视频的录制创作 直播 VoIP
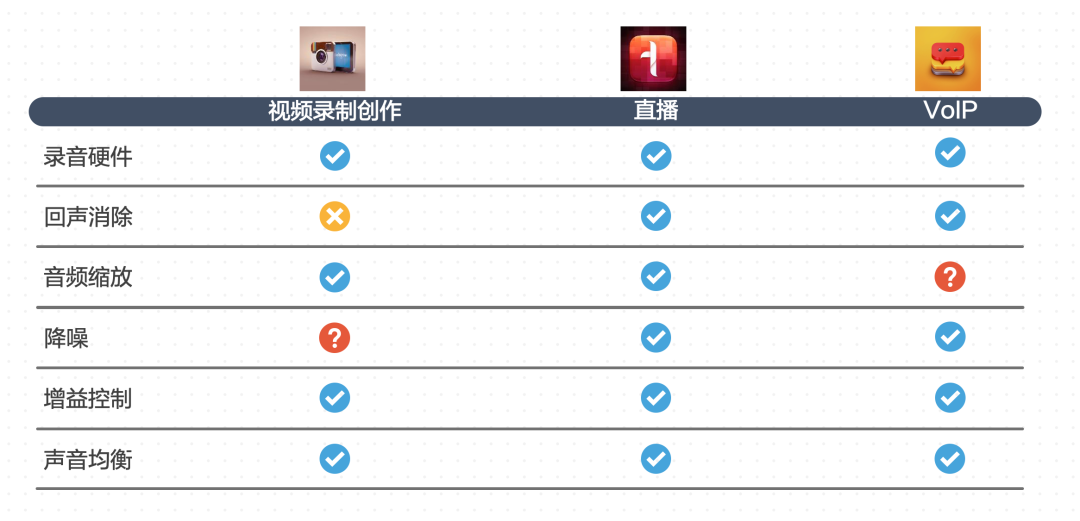
在系统稳定性方面:基于整体的硬件状态检测,实时切换音频。 在音频质量提升部分:我们研发了混响抑制、噪声消除以及增益控制等技术,可以持续改善音频质量。 在声音美化部分:可结合不同声音的特性进行动态 EQ 以及人声增强。
声场重建应用实践
首先是在视频/音频创作中,对各个声源进行声场重建,打造画面感声音引擎。网站上现有的存量视频很难获得高质量的沉浸式体验。因为音频更多的是一种单声道存在,画面中不同声源所处的方位很难从声音中体现出来。我们通过声场重建,可以对原视频的各个声源进行分离/分割,再进行融合,这样就能打造出更高质量的音视频。 其次在 AR 以及 VR 产品中,结合声场重建技术,也能打造出更沉浸式的音视频体验。
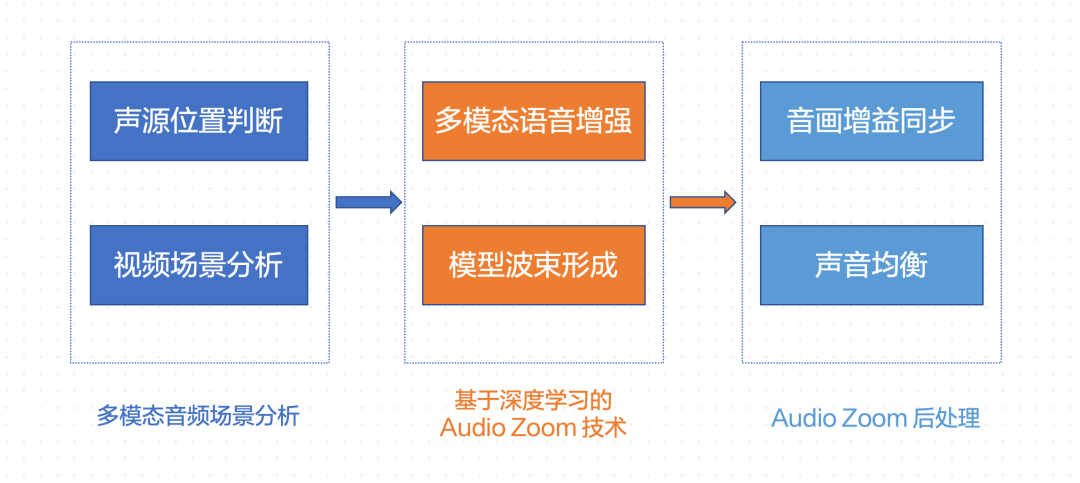
声场分析:需要对声源的相对位置、声源路径和声音种类做判断。 声源提取:需要对视频画面中的各个声源进行提取。利用声源分割/分离、波束形成、多模态语音增强等技术,对视频画面中的各个音源进行针对性的提取,然后结合声场分析出各音源对应的位置路径等信息,送入 3D 空间生成的部分,再结合多音量均衡的技术,实现最终的声音重建的效果。
背景音乐的声音 男生唱歌的声音 男生的音质。因为在声场还原的过程中,尽量要求不损失已有视频的音质。这个目前对于存量视频来说是一个很关键的技术。
智能语音交互中的音频信号处理
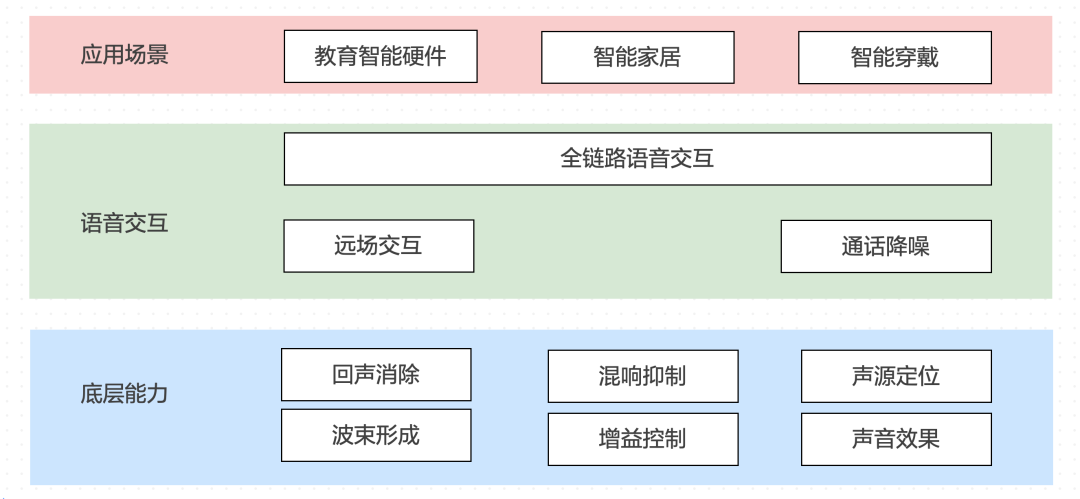
完整的底层能力,像语音交互中的回声消除、混响抑制,基于针对信号处理的声源定位、波束形成,为了解决远距离的增益控制,以及在播放侧打造更好的声音效果的 EQ 技术等等。 这些技术向上支持的是全链路语音交互,包括远场语音交互以及通话降噪。 在具体的应用场景中,目前主要在教育智能硬件、智能家居以及智能穿戴等产品中会应用到智能语音交互。
展望未来

文章转载自火山引擎开发者社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
