




我们在对oracle数据进行操作的时候,不小心操作错误,只要没有COMMIT,点击ROLLBACK恢复就好了,但有时候觉得麻烦,还得要提交。那为什么要这样设计呢?
我所观察到的有两点原因:
第一个在于可以保证数据安全,提高容错。
第二个是锁的机制,确保数据的唯一性。
假设我要更新100亿条数据,而我的电脑运行速度特别慢,一秒钟只能更新1亿条,也就是整个做完这个更新需要耗时100秒钟,如果没有commit这个步骤,相当于直接操作数据库,那么在这段时间内数据库操作到哪了,我们根本不知道,假如地震了,我们该怎么恢复都不知道。
但是有了COMMIT,数据库当前的操作写入日志文件中,一旦我们点击提交后,系统通过日志文件来操作数据库,如果发生异常,根据日志继续往下做就可以了。
在这里,commit的操作起到了一个确认提交作用,提高容错的能力。
第二个问题就是这样可以确保数据唯一准确,同时释放锁。
假如A和B同时持有一样的银行卡,都去银行取钱,卡里只有一百块,他们同时按下取钱的按钮,会不会取出两百块呢?如果没有commit这个功能的话或许真可以。但实际上这样不行,为什么?因为当你输入了密码之后,实际上你是获取了数据库中对应信息的锁,你获得了锁,别人就没有办法再去访问,相当于这行数据被锁定,其他人无法更改。只有当你做完了所有操作,点击退卡,相当于commit释放了锁,这个时候别人才有修改这条数据的权限。
这一点保证了数据的唯一性,最先操作数据的人获得该所锁,这期间其他人无法操作数据,直至释放锁。比较常见的是数据库,还有办公软件比如ppt,多人操作的时候很容易发生冲突,经常会造成死锁。
如何避免死锁呢?比较好的方法有银行家算法,评估一项贷款能不能按期还款,不能就不给贷。那用在数据库这里怎么理解呢?把我们有限的进程都标记为:已完成,正在进行中,等待中。不给正在进行中的进程安排任务,就不会发生死锁的问题。
这样的容错机制很好,我们常见的其他容错机制还有哪些呢?
数据库中故障了怎么办?切换备机。我们常用的failover测试就是通过手动关闭一台服务器,来测试系统是否能自动切换到另一台服务器上去(如下图),传统的设备中,我们将A与B之间设置心跳线,然后采用其中某个去执行业务,当发生故障,才切换到另外一台服务器。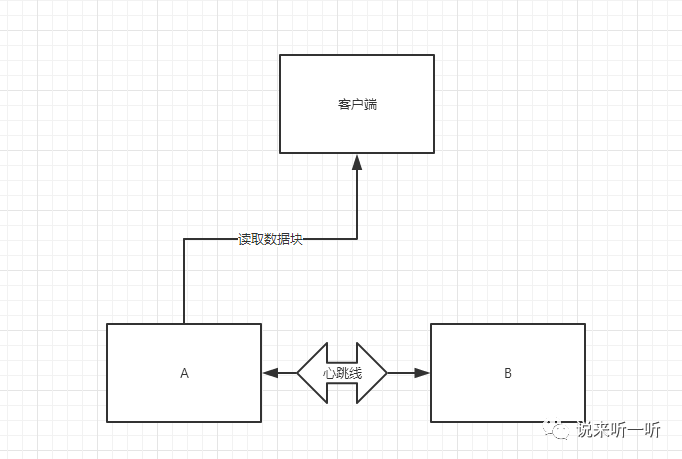
但有几个问题,备用机的数据是实时更新的吗?会不会造成数据丢失?如何替换故障服务器?这些都是要考虑的问题。
那有没有其他类似的解决方案呢?我们来看下图:
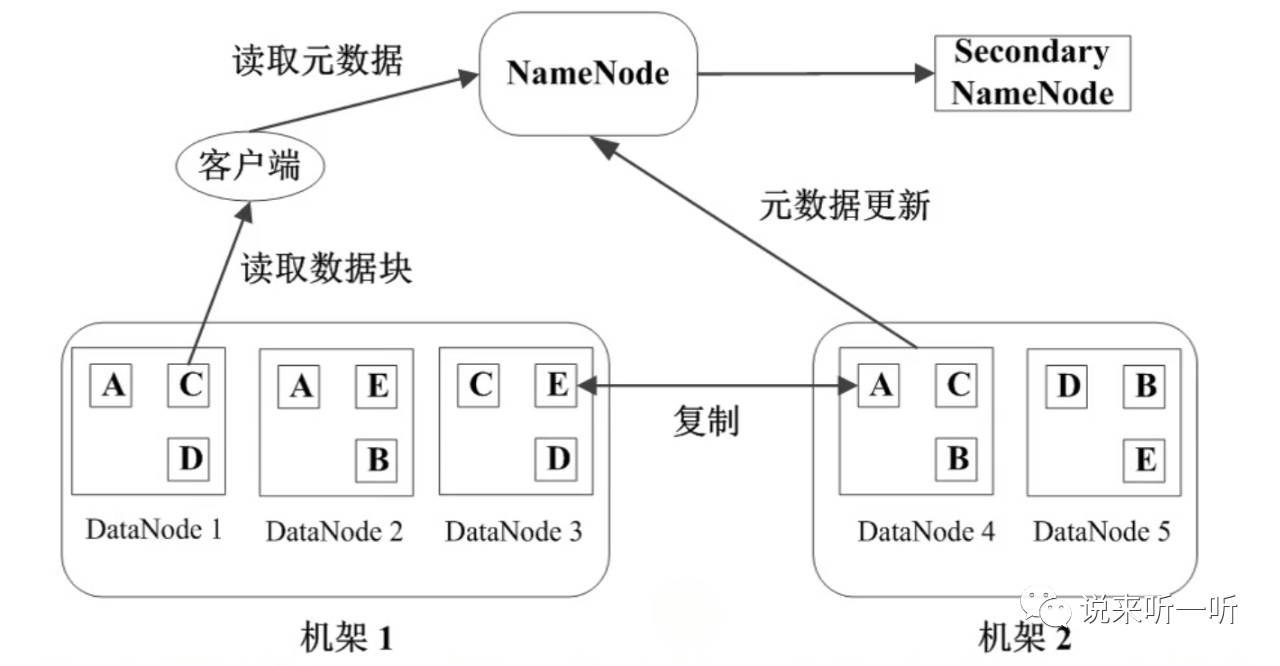
NameNode:管理节点,存放文件元数据,数据块与元数据的映射表等。
DataNode:数据节点,存放数据块。
而这种方法则是:建立NameNode与DataNode两种节点。
1.NameNode有一个二级NameNode,心跳检测到出现故障后,二级NameNode上位,备胎转正。
2.DataNode与NameNode建立心跳线,当NameNode发现DataNode出现故障,会自动将故障设备排除。
3.每份数据分别保存在两台机架的三个DataNode中,如上图数据块A,分别存在DataNode1,DataNode2与DataNode4中。假设DataNode1故障,那么可以根据DataNode2与DataNode4返回数据。假设机架1故障,那么机架2中DataNode4仍然有一套完整数据。
这就是hadoop的HDFS的核心理念,利用低成本的服务器集群来提高容错率。
今天的介绍就到这,后续和你一起了解mapreduce的相关知识。(如果那里讲错了,大神们一定要告诉我啊。)
预防
