1.4、在windows上安装
1、安装Elasticsearch
在windows上安装es比较简单,基本上解压就可以直接使用。
步1、下载解压了解es的目录结构
下载地址:https://www.elastic.co/cn/elastic-stack
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-windows-x86_64.zip
解压后的目录为:
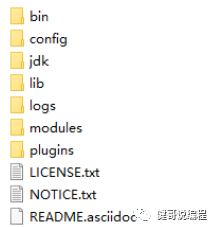
Config:为配置文件所在的目录
Bin:包含启动程序。
Jdk: es7.6里面,包含一个open-jdk13.
Lib:jar包。
Logs:日志目录
Modules:模块。
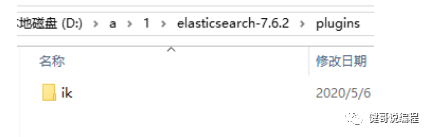
Plugins:一些其他插件,如果是新解压的es,此目录应该是空的。即没有任何的插件。如后面的IK分词器,就可以直接解压到这个目录下。注意,这些插件和版本必须要与es的版本一致。
步2、配置es
可选配置:
config/jvm.options
-Xms1g
-Xmx1g
默认启动将占用1G内存,可根据实际情况进行修改。
config/elasticseach.yml,es的配置文件:
network.host: 0.0.0.0 #配置任何客户端都可以访问。
http.port: 9200 #默认就是9200,可以不用配置。如果配置了这个选项,以下两个必须要配置
discovery.seed_hosts: ["thinkme"]
cluster.initial_master_nodes: ["thinkme"]
#以下为跨域时的必须配置,head的默认为9100端口,访问9200端口为跨域
http.cors.enabled: true #这儿再增加两条新内容,以支持跨域请求,如果使用es-head连接,必须配置。
http.cors.allow-origin: "*"
步3、启动
运行:elasticsearch.bat
[o.e.n.Node ] [THINKME] started
访问测试:http://localhost:9200
1、安装IK插件
IK是一个分词工具,在es中使用IK需要下载IK的插件,并解压到es的plugins下即可使用:
步1、下载并解压
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/tree/v7.6.2
选择与es对应的版本:
下载:
解压到plugins目录下,并修改目录名为:ik(可是以任何名称)
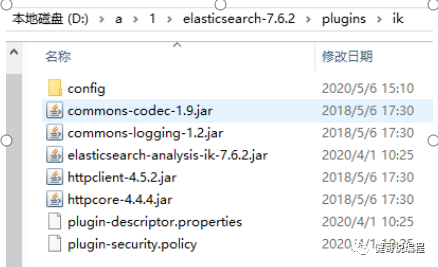
最终的目录结构:
步2、重新启动es,并查看控制台
elastaicsearch.bat
[THINKME] loaded plugin [analysis-ik]
步3、如何使用ik
ik提供两种分词算法:
1:ik_smart 最少切分。
2:ik_max_word 最小粒度。
在kibana的查询工具中输入:
2、使用命令行安装分词器插件
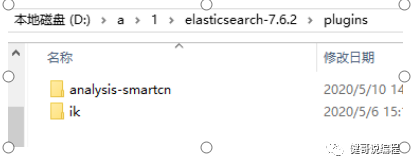
同样的也可以使用命令行来安装分词器插件。如安装中文分词器analysis-smartcn,可以在es的bin目录下执行:
Bin> elasticsearch-plugin.bat install analysis-smartcn

安装完成以后,就会在es的plugins目录下,发现此目录:
然后还可以通过命令行,查看有多少已经安装的分词插件,输入:
> elasticsearch-plugin.bat list

注意,安装完成以后,必须要重新启动es才可以使用这个分词器。
然后就可以使用smartcn了,注意analyzer输入的值为:smartcn
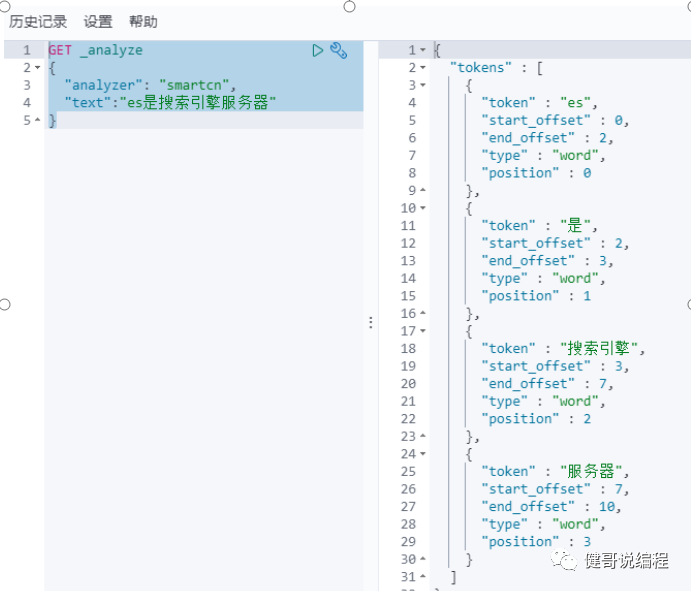
其他可以安装的分词器还有:
analysis-icu
analysis-ik
analysis-smartcn
pinyin
2、安装Elasticsearch head
Es-head是es的一个可视化工具,用于查看es集群信息。Es-head需要node10.x以上环境。所以需要先安装node环境。为了加快下载依赖的速度,建议配置node依赖taobao镜像。
步1、安装node
下载node:https://nodejs.org/dist/v12.16.3/node-v12.16.3-x64.msi
安装:直接安装,并下一步即可。
查看版本:
C:\Users\Administrator>node -v
v12.16.3
C:\Users\Administrator>npm -v
6.14.4
以下都是可选的:
配置:
#配置mudles目录
>npm config set prefix "E:\.node\node_modules"
#配置缓存目录
>npm config set cache "E:\.node\node_cache"
#配置淘宝加速
>npm config set registry=http://registry.npm.taobao.org
或在C:/users/<当前用户>目录下,直接修改 .npmrc文件:
prefix=E:\configs\.node\node_modules
cache=E:\configs\.node\node_cache
registry=http://registry.npm.taobao.org
strict-ssl=false
安装cnpm:
>npm install cnpm -g
步2、下载es-head解压
下载地址:
https://codeload.github.com/mobz/elasticsearch-head/zip/master
步3、在解压目录下执行安装并启动
> cd D:/a/1/elasticsearch-head
>npm install
>npm run start
D:\a\1\elasticsearch-head-master>npm run start
> elasticsearch-head@0.0.0 start D:\a\1\elasticsearch-head-master
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
步4、访问
http://localhost:9100
步5、使用es-head
1、查看集群信息
查看集群信息,可以通过右上边的信息按扭查看:

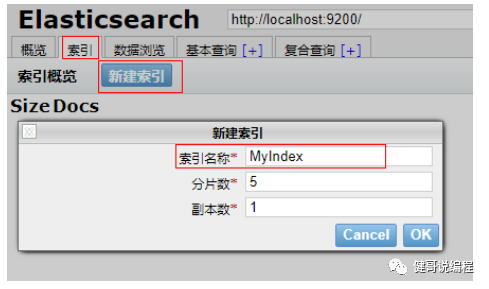
2、新创建索引
一个索引,类似于一个数据库。可以通过 索引>新建索引 创建一个新的索引。
建议索引的名称都用小写字符。
创建完成索引以后,会在概览地方查看到这个索引的信息:
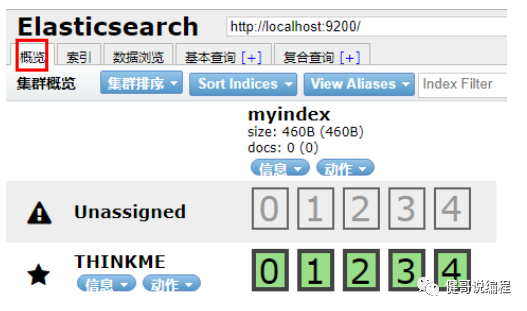
0-4为分片信息。因为在创建时,指定副本数量为1,所以上面的Unassigned为副本。
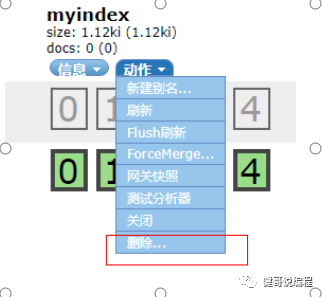
3、删除索引
创建完成索引以后,可通过 动作>删除 来删除索引:
4、查询
将在Kibana中查询。
3、安装Kibana
安装kibana需要与es的版本必须要保持一致。
步1、下载并解压
下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-windows-x86_64.zip
解压:
kibana由node开发。所以需要有node环境。
步2、配置
同时修改$KIBANA_HOME/config/kibana.yml:
server.port: 5601
server.host: "localhost"
server.name: "server101" #根据您主机的名称进行配置
elasticsearch.hosts: ["http://localhost:9200"]
I18n.locale: “zh-CN” #配置中文
步3、启动kibana
直接运行bin/kibana.bat即可以启动kibana:
http server running at http://localhost:5601
启动完成以后,访问5601端口:
初次使用,会显示一个界面,让我们选择是否使用测试数据,可以选择浏览进入即可。即不使用测试数据。
步4、使用查询工具
查询工具:
点 Dev Tools:
即可在控制台中输入代码并执行:
IK分词器
这儿这们使用ik对分词进行测试。根据上面的文档,我们已经在es中安装了ik分词器插件。
ik提供了两种分词算法:(注意以下都是小写,且都是下划线)
1、ik_smart 最少切分。
2、ik_max_word 最细粒度切分。
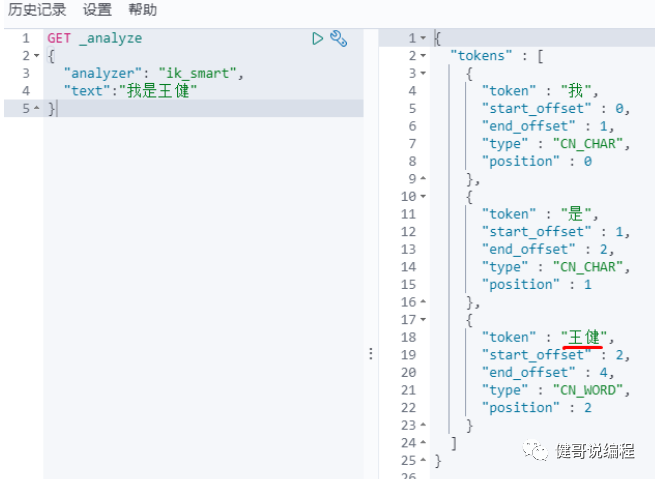
ik_smart示例:

ik_max_word示例,最细粒度会将所有可能的组合全部进行分词:
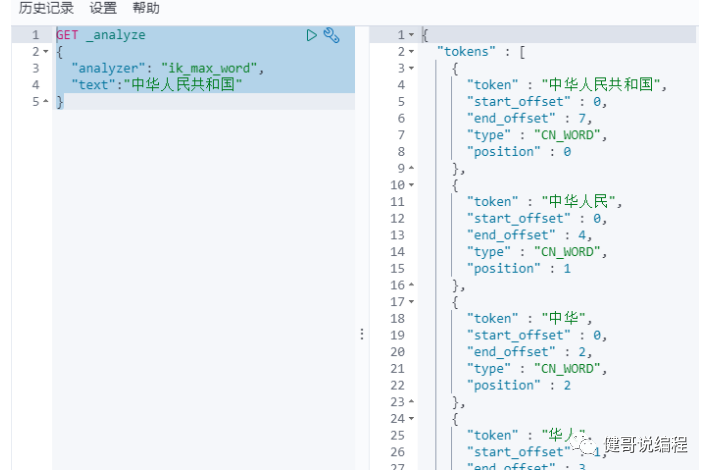
请使用两种分词算法,试验以下执行结果:
GET _analyze
{
"analyzer": "ik_max_word",
"text":"elasticsearch是一个搜索引擎服务器"
}
编辑分词器字典
对对不是词语的组成,我们可以通过编辑IK字典的方式,给它添加一个分词,如下输入我的姓名,结果为:
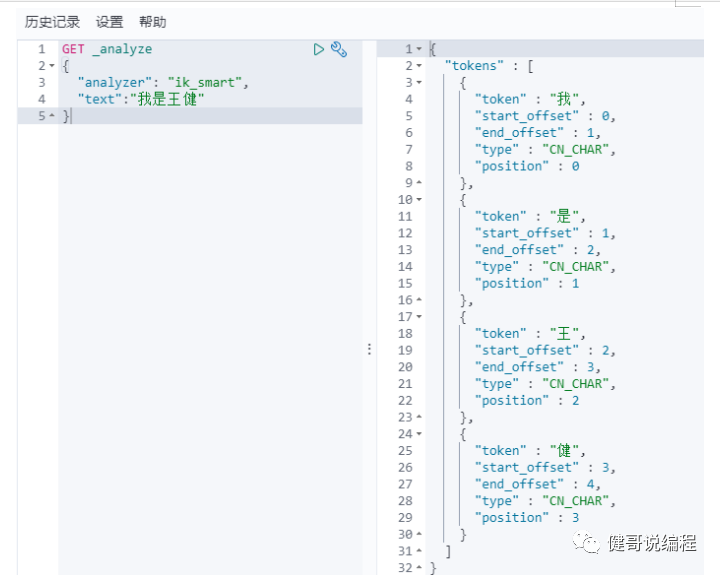
现在将将“王健”做成一个分词,添加到IK的字典中,在es的plugins下,打开ik\config目录,然后x编辑:IKAnalyzer.cfg.xml:
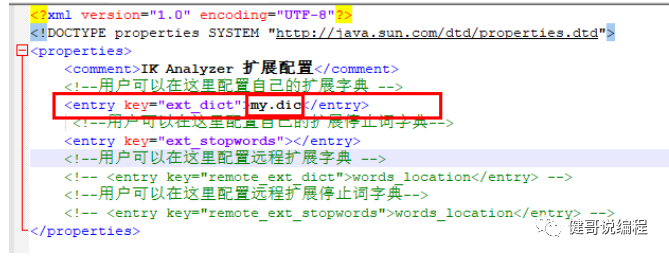
然后在my.dic中输入:
王健
必须要重新启动es。
重新启动以后,再次查询,发现“王健“已经成为一个分词了: