




配置hadoop高可靠集群
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA、YARN都可以配置HA(高可靠),在hadoop2.x时一个namenodeservice只能只多有两个namenode,而到了3.0一个nameservice可以有三个namenode或是更多。以下是官方说明:
The minimum number of NameNodes for HA is two, but you can configure more. Its suggested to not exceed 5 - with a recommended 3 NameNodes - due to communication overheads.
配置过程列表:
Ø 配置规划。
Ø 配置从一台主机到其他主机的SSH免密码登录。
Ø 关闭所有主机的防火墙。
Ø 配置所有主机的静态地址和hosts文件。
Ø 所有主机上安装JDK1.8,并配置环境变量。
Ø 至少在三台主机上安装好zookeeper并启动zookeeper集群。
Ø 在一台主机上配好hadoop的所有配置文件,并分发到所有主机。
n 这些配置文件为:hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml,workers,start-dfs.sh,stop-dfs.sh,start-yarn.sh,stop-yarn.sh。
Ø 所有主机配置hadoop环境变量。
Ø 启动JournalNode。
Ø 在某台配置了NameNode的主机上格式化NameNode。
Ø 然后将格式化后的目录copy到其他的主机(主是指配置了NameNode的主机)
Ø 格式化zkfc
Ø 格式化NameNode并copy给其他namenode节点。
Ø 启动hdfs,启动yarn。
步1、配置表
配置表:
IP/主机名 | 软件 | 进程 |
192.168.56.21 server21 | JDK1.8 Zookeeper3.4 Hadoop3.1.1 | QuorumPeerMain NameNode ZKFC QJM ResourceManager NodeManager DataNode |
192.168.56.22 server22 | JDK1.8 Zookeeper3.4 Hadoop3.11 | QuorumPeerMain NameNode ZKFC QJM ResourceManager NodeManager DataNode |
192.168.56.23 server23 | JDK1.8 Zookeeper3.4 Hadoop3.1.1 | QuourmPeerMain NameNode ZKFC QJM ResourceManager NodeManager DataNode |
步2、前期准备
所有主机关闭防火墙。
所有主机安装JDK1.8,并配置环境变量。
所有主机设置静态IP地址,修改主机名称。
设置所有主机selinux=disabled。
安装好zookeeper集群。并启动。
步3、配置hadoop-env.sh文件
此文件中只配置JAVA_HOME环境变量:
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
步4、配置core-site.xml文件
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<!-- 指定hadoop hdfs目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>server21:2181,server22:2181,server23:2181</value>
</property>
<!--可选的配置QJM日志目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journal/local/data</value>
</property>
</configuration>
3)、配置hdfs-site.xml文件,这里的配置信息比较多
<configuration>
<!--指定hdfs的nameservice为cluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- ns1下面有多个NameNode(hadoop3.0以后),分别是nn1,nn2,nn3
注意,namenodes后面为cluster即之前配置的名称
-->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!--配置每一个NameNode的rpc通信地址-->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>server21:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>server22:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn3</name>
<value>server23:8020</value>
</property>
<!--配置每一个NameNode的web http地址-->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>server21:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>server22:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn3</name>
<value>server23:9870</value>
</property>
<!--配置QJM的地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://server21:8485;server22:8485;server23:8485/cluster</value>
</property>
<!--配置QJM日志的目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/qjm/edits</value>
</property>
<!--配置为自动切换功能打开,需要在core-site.xml文件中配置ZK地址-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置自动切换的方式-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--配置SSH key,注意根据不同的用户名修改目录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
步5、配置mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
步6、配置yarn-site.xml
<configuration>
<!--配置RM高可靠-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!--配置Resourcemanager个数,hadoop3以后可以为3到5个-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!--以下配置每一个RM的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>server21</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>server22</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>server23</value>
</property>
<!--配置每一个RM的http地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>server21:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>server22:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>server23:8088</value>
</property>
<!--配置zookeeper地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>server21:2181,server22:2181,server23:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--hadoop3里面必须要添加的classpath-->
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.1.1/etc/hadoop:/opt/hadoop-3.1.1/share/hadoop/common/lib/*:/opt/hadoop-3.1.1/share/hadoop/common/*:/opt/hadoop-3.1.1/share/hadoop/hdfs:/opt/hadoop-3.1.1/share/hadoop/hdfs/lib/*:/opt/hadoop-3.1.1/share/hadoop/hdfs/*:/opt/hadoop-3.1.1/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.1.1/share/hadoop/mapreduce/*:/opt/hadoop-3.1.1/share/hadoop/yarn:/opt/hadoop-3.1.1/share/hadoop/yarn/lib/*:/opt/hadoop-3.1.1/share/hadoop/yarn/*</value>
</property>
</configuration>
步7、配置workers文件
workers是指定DataNode节点的位置。在里面添加主机的名称或是ip地址即可,一行一个
server21
server22
server23
步8、配置start-dfs.sh/stop-dfs.sh
在中间位置,找到一个空白的位置添加:
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=root
#以下是高可靠配置的
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
步9、配置start-yarn.sh/stop-yarn.sh
在两个配置文件中间位置添加以下内容:
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
步10、现在配置hadoop的环境变量
export HADOOP_HOME=/opt/hadoop-3.x
export PATH=$PATH:$HADOOP_HOME/bin
让环境变量生效,执行以下命令
$source etc/profile
步11、拷贝文件其他主机
将配置好的hadoop目录和hadoop配置文件,copy到其他主机相同的目录下使用scp命令。由于share目录下的doc里面都是文档,可以删除这个目录,以加快copy速度。
$ scp -r /opt/hadoop-3/ server22:/opt/
步12、启动journalnode
分别在在server21、server22、server23上执行。
$ ./hadoop-daemon.sh start journalnode
步13、格式化HDFS
#在server21上执行命令:
hdfs namenode -format
格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,然后将这个文件使用scp拷贝到weric12的相同目录下。因为,都是NameNode节点,必须要拥有相同的数据文件。格式化成功的标志是在输出的日志中查看是否存在以下语句:
Storage directory /opt/hadoop_tmp_dir/dfs/name has been successfully formatted
现在将格式化后的hdfs目录,拷贝到weric12主机上的相同目录下:
$ scp -r /opt/hadoop/tmp/ server22:/opt/
步14、格式化zkfc
在server21上执行
hdfs zkfc -formatZK
Successfully created hadoop-ha/cluster in ZK.
在格式化完成以后,通过zkCli.sh登录zookeeper并查看目录列表,将显示一个hadoop-ha的目录,表示初始化成功
[zk: localhost:2181(CONNECTED) 0] ls
[zookeeper, hadoop-ha]
步15、启动HDFS(在server21上执行)
在server21上启动hdfs即NameNode同时也会将server22,server23上的nameNode一并启动。
$ ./start-dfs.sh
步16、启动YARN
在server21上执行:
$ ./start-yarn.sh
在启动完成以后,根据之前的配置列表,分别检查每一个主机上的服务是否都已经启动。如果没有请查看日志错误。
步17、验证高可靠
通过浏览器访问以下是地址可以查看hdfs的信息,如图7.4.3所示:
http://192.168.56.21:9870

图7.4.3
通过图7.4.3可以看出当前NameNode为active。而通过图7.4.4所示weric12上的NameNode为Standby。
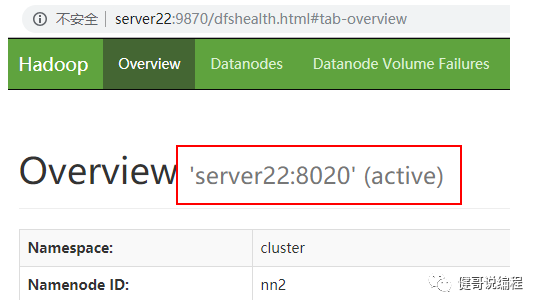
图7.4.4
也可以通过以下命令,检查NameNode和ResourceManager的状态
$ hdfs haadmin -getServiceState nn1
active
$ hdfs haadmin -getServiceState nn2
standby
$ yarn rmadmin -getServiceState rm1
active
$ yarn rmadmin -getServiceState rm2
standby
现在让我们kill掉active的NameNode,即kill掉nn1
$kill -9 <pid of NN>
然后再检查状态,这个时候weric12上的NameNode变成了active
$ hdfs haadmin -getServiceState nn2
active
手动启动那个挂掉的NameNode,即nn1,然后再检查状态,它已经成为standby的了
$./hadoop-daemon.sh start namenode
$ hdfs haadmin -getServiceState nn1
standby
使用同的样的方式,可以验证ResourceManager是否可以自动实现容灾切换。
有可能出现的问题:
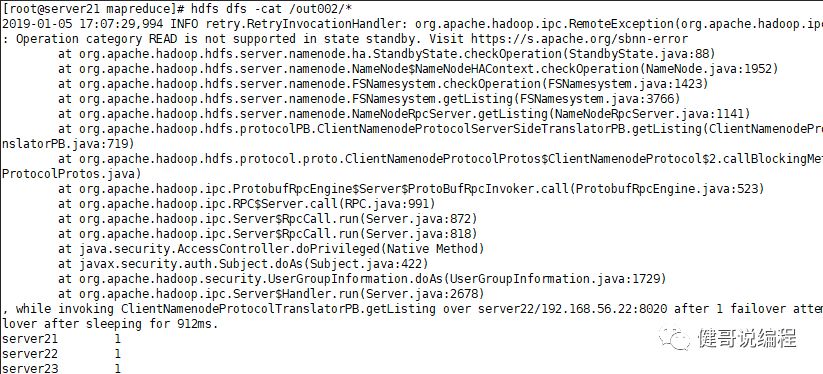
问题地址:
https://issues.apache.org/jira/browse/HDFS-3447
即:如果hadoop有多个NameNode,如果访问到第二个NameNode还是StandayBy就会出现以上的Debug信息。但不影响使用。
所以,我们还是建议配置两个NameNode,实在是没有必要配置3-5个NameNode。
【注意】
1:在集群完成以后,建议执行一个mapreduce测试,如wordcount。
2:Hadoop的高可靠集群每一次启动相对比较麻烦。但配置成功以后,下次启动就相对比较简单了。对于上面的示例而言,再次启动只要在server21主机上执行./start-dfs.sh和./start-yarn.sh即可。
【注意】
关于免密码登录的说明
要求能通过免登录包括使用IP和主机名都能免密码登录:
1) NameNode能免密码登录所有的DataNode
2) 各NameNode能免密码登录自己
3) 各NameNode间能免密码互登录
4) DataNode能免密码登录自己
5) DataNode不需要配置免密码登录NameNode和其它DataNode。6) ResourceManager必须要免密码登录所有DataNode以便于启动NodeManager。
7.5、用Java代码操作集群
用Java客户端面操作集群开发hdfs,必须要指定nameService的配置信息。以下是代码示例,以下代码显示hdfs上的文件和目录:
package cn.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* 访问HA-HDFS
* @author wangjian
* @version 1.0 2019年1月5日
*/
public class Demo01_HA {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","root");
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://cluster");
config.set("dfs.nameservices", "cluster");
config.set("dfs.ha.namenodes.cluster", "nn1,nn2");
config.set("dfs.namenode.rpc-address.cluster.nn1", "server21:8020");
config.set("dfs.namenode.rpc-address.cluster.nn2", "server22:8020");
config.set("dfs.client.failover.proxy.provider.cluster", //
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
FileSystem fs = FileSystem.get(config);
FileStatus[] fileStatus = fs.listStatus(new Path("/"));
for(FileStatus f:fileStatus) {
System.out.println(">>:"+f.getPath());
}
fs.close();
}
}
保存一个文件:
//设置用户名为root用户
System.setProperty("HADOOP_USER_NAME","root");
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://cluster");
config.set("dfs.nameservices", "cluster");
config.set("dfs.ha.namenodes.cluster", "nn1,nn2");
config.set("dfs.namenode.rpc-address.cluster.nn1", "server21:8020");
config.set("dfs.namenode.rpc-address.cluster.nn2", "server22:8020");
config.set("dfs.client.failover.proxy.provider.cluster", //
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
FileSystem fs = FileSystem.get(config);
OutputStream out = fs.create(new Path("/test/c.txt"));
out.write("JackAndMary".getBytes());
out.write("中文数据".getBytes());
out.close();
fs.close();
其他更多操示例,请自行开发。

