




1、trunc函数
--trunc函数用于直接截去数值后面的部分
--返回123
select trunc(123.98)from dual;
--返回123.23,后面的2是指截去小数点后面两位以后的所有数据,不四舍五入
select trunc(123.123,2)from dual;
--返回120,后面的-1是指截去小数点前面的一个数
select trunc(123.123,-1)from dual;
--可以用于计算时间,返回指定时间的第一天
--如:
--trunc(sysdate,'yyyy') --返回当年第一天.
--trunc(sysdate,'mm') --返回当月第一天.
--trunc(sysdate,'d') --返回当前星期的第一天,在国外,周日是第一天
select trunc(sysdate,'YYYY')from dual;
select trunc(sysdate,'MM')from dual;
select trunc(sysdate,'d')from dual;
--返回今天最开始的时间,即yyyy-MM-dd 00:00:00 凌晨12点
select to_char(trunc(sysdate),'yyyy-MM-dd HH24:mi:ss') from dual;
如:2018-11-04 00:00:00
--加8天以后的时间当前时间:2018-11-4号返回:2018-11-12 00:00:00
select to_char(trunc(sysdate)+8,'yyyy-MM-dd HH24:mi:ss') from dual;
--凌晨加1小时,因为一天为24小时,所以使用1/24即可
select to_char(trunc(sysdate)+(1/24),'yyyy-MM-dd HH24:mi:ss') from dual;
--凌晨加1小时30分钟,当前时间:2018-11-04,返回:2018-11-04 01:30:00
select to_char(trunc(sysdate)+(1/24)+(30/(24*60)),'yyyy-MM-dd HH24:mi:ss') from dual;
--在凌晨加1小时30分钟,功能同上,只是将1小时写成60分钟,然后再加上30分种
select to_char(trunc(sysdate)+(90/(24*60)),'yyyy-MM-dd HH24:mi:ss') from dual;
--早上8:30
select to_char(trunc(sysdate)+(8*60+30)/(24*60),'yyyy-MM-dd HH24:mi:ss') from dual;
--周四凌晨,使用next_day(sysdate,''),其中5表示周四
select to_char(next_day(trunc(sysdate),5),'yyyy-MM-dd HH24:mi:ss') from dual;
--功能同上,使用Thursday表示周四更直观
select to_char(next_day(trunc(sysdate),'THURSDAY'),'yyyy-MM-dd HH24:mi:ss') from dual;
5.1、next_day
NEXT_DAY(date,char)
date参数为日期型,
char:为1~7或Monday/Mon~Sunday/
指定时间的下一个星期几(由char指定)所在的日期,
char也可用1~7替代,1表示星期日,2代表星期一
星期一 Monday 星期二 Tuesday
星期三 Wednesday 星期四 Thursday
星期五 Friday 星期六 Saturday
星期日 Sunday
--从指定基本以后的下一个周1
select to_char(next_day(to_date('2019-09-10','yyyy-MM-dd'),'MON'),'yyyy-MM-dd HH24:mi:ss') from dual;
--下一个周四返回:2018/11/8 星期四 上午 9:46:58
select next_day(sysdate,'THU') from dual;
5.2、last_day最后一天
--获取一个月的最后一天
select last_day(sysdate) from dual;
5.3、extract用于截取年、月、日、小时、分、秒
语法:
extract (
{ year | month | day | hour | minute | second }
| { timezone_hour | timezone_minute }
| { timezone_region | timezone_abbr }
from { date_value | interval_value } )
示例:
--从当前时间获取年,返回2018
select extract(year from sysdate) from dual;
--从当前时间获取月份,返回11
select extract(month from sysdate) from dual;
--从指定日期获取月份,返回09
select extract(month from to_date('2018-09-10','yyyy-MM-dd')) from dual;
使用date 时间:
--使用字符串
select extract(year from date '2008-09-10') year,extract(day from date '2018-09-23') day from dual;
计算两个时间之间的间隔:
select
extract (day from dt2 - dt1) 天,
extract (hour from dt2 - dt1) 小时,
extract (minute from dt2 - dt1) 分钟,
extract (second from dt2 - dt1) 秒
from
(
select
to_timestamp ('2011-02-04 15:07:00','yyyy-mm-dd hh24:mi:ss') dt1,
to_timestamp ('2011-05-17 19:08:46','yyyy-mm-dd hh24:mi:ss') dt2
from
dual
);

或是直接串联成字符串:
select
'相差:'||(extract (day from dt2 - dt1))||'天'||(extract (hour from dt2 - dt1))||'小时'
||extract(minute from (dt2-dt1))||'分'||extract(second from dt2-dt1)||'秒' as 相差
from
(
select
to_timestamp ('2018-02-04 15:07:00','yyyy-mm-dd hh24:mi:ss') dt1,
to_timestamp ('2018-05-17 19:08:46','yyyy-mm-dd hh24:mi:ss') dt2
from
dual
);
返回:相差:102天4小时1分46秒
2、Oracle的定时任务
1、视图user_jobs
Oracle中的定义任务保存在user_jobs,all_jobs,dba_jobs表中:
User_jobs表字段说明:
-- 查询字段描述
/*
字段(列) 类型 描述
JOB NUMBER 任务的唯一标示号
LOG_USER VARCHAR2(30) 提交任务的用户
PRIV_USER VARCHAR2(30) 赋予任务权限的用户
SCHEMA_USER VARCHAR2(30) 对任务作语法分析的用户模式
LAST_DATE DATE 最后一次成功运行任务的时间
LAST_SEC VARCHAR2(8) 如HH24:MM:SS格式的last_date日期的小时,分钟和秒
THIS_DATE DATE 正在运行任务的开始时间,如果没有运行任务则为null
THIS_SEC VARCHAR2(8) 如HH24:MM:SS格式的this_date日期的小时,分钟和秒
NEXT_DATE DATE 下一次定时运行任务的时间
NEXT_SEC VARCHAR2(8) 如HH24:MM:SS格式的next_date日期的小时,分钟和秒
TOTAL_TIME NUMBER 该任务运行所需要的总时间,单位为秒
BROKEN VARCHAR2(1) 标志参数,Y标示任务中断,以后不会运行
INTERVAL VARCHAR2(200) 用于计算下一运行时间的表达式
FAILURES NUMBER 任务运行连续没有成功的次数
WHAT VARCHAR2(2000) 执行任务的PL/SQL块
CURRENT_SESSION_LABEL RAW MLSLABEL 该任务的信任Oracle会话符
CLEARANCE_HI RAW MLSLABEL 该任务可信任的Oracle最大间隙
CLEARANCE_LO RAW MLSLABEL 该任务可信任的Oracle最小间隙
NLS_ENV VARCHAR2(2000) 任务运行的NLS会话设置
MISC_ENV RAW(32) 任务运行的其他一些会话参数
*/
上面重要字段为:
JOB,NEXT_DATE,INTERVAL,WHAT。
这个表中的记录,每执行一次,就会被更新:

2、视图dba_jobs_running
管理员可执行。
create or replace view dba_jobs_running
(sid, job, failures, last_date, last_sec, this_date, this_sec, instance)
as
...
3、interval运行频率
描述 INTERVAL参数值
每天午夜12点 TRUNC(SYSDATE + 1)
每天早上8点30分 TRUNC(SYSDATE + 1) + (8*60+30)/(24*60)
每星期二中午12点 NEXT_DAY(TRUNC(SYSDATE ), ''TUESDAY'' ) + 12/24
每个月第一天的午夜12点 TRUNC(LAST_DAY(SYSDATE ) + 1)
每个季度最后一天的晚上11点 TRUNC(ADD_MONTHS(SYSDATE + 2/24, 3 ), 'Q' ) -1/24
每星期六和日早上6点10分 TRUNC(LEAST(NEXT_DAY(SYSDATE, ''SATURDAY"), NEXT_DAY(SYSDATE, "SUNDAY"))) + (6×60+10)/(24×60)
每天运行一次
'SYSDATE + 1'
每小时运行一次
'SYSDATE + 1/24'
每10分钟运行一次
'SYSDATE + 10/(60*24)'
每30秒运行一次
'SYSDATE + 30/(60*24*60)'
每隔一星期运行一次
'SYSDATE + 7'
每个月最后一天运行一次
'TRUNC(LAST_DAY(ADD_MONTHS(SYSDATE,1))) + 23/24'
每年1月1号零时
'TRUNC(LAST_DAY(TO_DATE(EXTRACT(YEAR FROM SYSDATE)||'12'||'01','YYYY-MM-DD'))+1)'
每天午夜12点
'TRUNC(SYSDATE + 1)'
每天早上8点30分
'TRUNC(SYSDATE + 1) + (8*60+30)/(24*60)'
每星期二中午12点
'NEXT_DAY(TRUNC(SYSDATE ), ''TUESDAY'' ) + 12/24'
每个月第一天的午夜12点
'TRUNC(LAST_DAY(SYSDATE ) + 1)'
每个月最后一天的23点
'TRUNC (LAST_DAY (SYSDATE)) + 23 24'
每个季度最后一天的晚上11点
'TRUNC(ADD_MONTHS(SYSDATE + 2/24, 3 ), 'Q' ) -1/24'
每星期六和日早上6点10分
'TRUNC(LEAST(NEXT_DAY(SYSDATE, ''SATURDAY"), NEXT_DAY(SYSDATE, "SUNDAY"))) + (6*60+10)/(24*60)'
4、创建Job的语法
declare
variable job number;
begin
sys.dbms_job.submit(
job => :job,
what => 'prc_name;',
next_date => to_date('22-11-2013 09:09:41', 'dd-mm-yyyy hh24:mi:ss'),
--每天86400秒钟,即一秒钟运行prc_name过程一次
interval => 'sysdate+1/86400'
);
commit;
end;
参数说明:
使用dbms_job.submit方法过程,这个过程有五个参数:job、what、next_date、interval与no_parse。
dbms_job.submit(
job OUT binary_ineger,
What IN varchar2,
next_date IN date,
interval IN varchar2,
no_parse IN booean:=FALSE)
job参数是输出参数,由submit()过程返回的binary_ineger,这个值用来唯一标识一个工作。一般定义一个变量接收,可以去user_jobs视图查询job值。
what参数是将被执行的PL/SQL代码块,存储过程名称等。
next_date参数指识何时将运行这个工作。
interval参数何时这个工作将被重执行。
no_parse参数指示此工作在提交时或执行时是否应进行语法分析——true,默认值false。指示此PL/SQL代码在它第一次执行时应进行语法分析,而FALSE指示本PL/SQL代码应立即进行语法分析。
5、快速示例
以下演示每一秒向表中插入一行记录。
创建表:
drop table books;
create table books(
id varchar(32),
name varchar(30),
create_time timestamp default sysdate
);
写入一行记录测试:
insert into books(id,name) values(sys_guid(),'Jack');
select * from books;
创建一个存储过程:
create or replace procedure PROC_INSERT_BOOK_PER_SECOND
as
begin
insert into books(id,name) values(sys_guid(),'Mary');
commit; --记得提交事务
end;
调用测试:
call PROC_INSERT_BOOK_PER_SECOND();
查询:
select * from books;

创建Job:
declare
jobid number;
begin
sys.dbms_job.submit(
job=>jobid,
--注意:按存储过程的规则必须要写入();做为结束
what=>'PROC_INSERT_BOOK_PER_SECOND();',
next_date=>sysdate,
interval=>'sysdate+(1/24*60*60)'
);
Commit;
end;
查询这个Job id
select * from user_jobs;
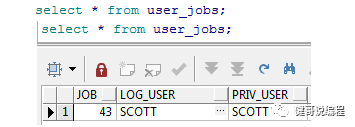
一个Job在声明以后,必须要执行一次以后,才会自动的执行,所以,先执行一个这个Job
begin
--执行这个job
sys.dbms_job.run(43);
end;
在sqlplus中执行可以直接看到这个返回的ID:
SQL> declare
2 jobid number;
3 begin
4 sys.dbms_job.submit(
5 job=>jobid,
6 --注意:按存储过程的规则必须要写入();做为结束
7 what=>'PROC_INSERT_BOOK_PER_SECOND();',
8 next_date=>sysdate,
9 --以下设置为每10秒执行一次
10 interval=>'sysdate+(10/(24*60*60))'
11 );
12 --也必须要commit一下
13 commit;
14 dbms_output.put_line('创建的JOB ID为:'||jobid);
15 end;
16 /
创建的JOB ID为:46
PL/SQL procedure successfully completed
知识了JOBID就可以直接使用run来启动这个job了。
--查看表中的数据,一直在增加,但发现,虽然设置为1秒执行一次,但好像是5秒执行一次。难道5秒是最小的时间?
--停止这个Job但不删除
begin
--停止这个Job的执行
sys.dbms_job.broken(43,true);
commit;
end ;
--根据JOB ID删除某个JOB,并提交
begin
sys.dbms_job.remove(44);
commit;
end ;
6、关于执行执行总是延长的解决方案
使用以下语句,每一次时间都会向后延长,是因为sysdate是一个变化的值
interval=>'sysdate+(10/(24*60*60))'
可以使用:trunc只取mi(最小就是mi)以下设置为每一分钟执行一次:
interval=>'trunc(sysdate,''mi'')+1/(24*60)'
7、向存储过程中传递参数
--创建一个有参数的存储过程,如接收当前时间
create or replace procedure PROC_INSERT_BOOK(pd date)
as
begin
insert into books(id,insert_time,create_time)
values(sys_guid(),pd,sysdate);
end;
在Job中向存储过程传递参数:
declare
jobid number;
begin
sys.dbms_job.submit(
jobid,
'PROC_INSERT_BOOK(sysdate);',
sysdate,
'trunc(sysdate,''mi'')+1/(24*60)'
);
dbms_output.put_line('job is:'||jobid);
end;
