




搭建Hadoop HA集群
1、HA(high Available)高可靠。
2、使用JournalNode来同步多个NaneNode之间的元数据。
3、一个nameservice里面最多可以包含两个namenode。
4、使用zookeeper实现namenode主备之间的切换。
5、使用QJM即Quorum Journal Manager。
6、QJM用于在Active NameNode(主namenode)和Standby NameNode(备NameNode)之间同步日志数据,即edits log数据。
7、QJM的守护进程为JournalNode。这个进程是一个非常轻量级别的。JournalNode的配置数量应该为奇数,即3,5,7等。
8、在HA的环境下,由Standby NameNode执行检查点工作。从而合并fsimage和edits日志。所以,没有必要再运行一个Secondary NameNode。
参考地址:
HDFS HA的配置参考:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
Yarn HA配置参考:
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
步1、进程规划
假设我们只有三台机器,现在规划如下:
主机/ip | 软件 | 进程 |
Hadoop61 192.168.56.61 | JDK Hadoop zookeeper | NameNode(1) zkfc(DFSZKFailoverController)
DataNode NodeManager
ResourceManager(1)
JournalNode QuorumPeerMain |
Hadoop62 192.168.56.62 | Jdk Hadoop zookeeper | NameNode(2) zkfc(DFSZKFailoverController)
DataNode NodeManager
ResourceManager(2)
JournalNode QuorumPeerMain |
Hadoop63 192.168.56.63 | Jdk Hadoop zookeeper | DataNode NodeManager
JournalNode QuorumPeerMain |
1、由于zookeer要求机器数量为奇数台,所以,最少为3台,所以,在每台机器上都必须要配置QuorumPeerMan。
2、JournalNode也必须要是奇数,所以,上面仅有三台机器的情况下,只能每台都配置一个JournalNode的守护进程。
3、Zkfc即DFSZKFailoverController与nameNode在同一个节点上,用于时时监控NameNode的状态。当namenode变得不可用时,通知zookeeper进行主备切换。
步2、前提条件
1:安装JDK并配置环境变量。
2:配置静态ip地址。
3:配置主机名。Centos7-> sudo hostnamectl set-hostname xxxxx
Centos6->sudo hostname xxxxx - > sudo vim etc/hostname
4:配置ip地址和主机名影射。/etc/hosts
5:配置ssh免密码登录。
要配置两个namenode到所有dataNdoe的ssh。
要配置两个ResourceManager到所有NodeManager的ssh。
建议使用ssh-agent并使用带密码的key。
6:在多台机器上配置好zookeeper集群。
步3、配置hadoop
1、解压
$ tar -zxvf ~/hadoop-2.7.6.tar.gz -C app/
2、配置
Hadoop-env.sh文件:
export JAVA_HOME=/usr/jdk1.8.0_171
core-site.xml文件:
<configuration>
<!--配置nameservice-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!--指定zookeeper的地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop61:2181,hadoop62:2181,hadoop63:2181</value>
</property>
</configuration>
hdfs-site.xml文件:
<configuration>
<!--配置nameservice与hdfs://ns1保持相同,可以配置多个,ns1,ns2-->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!--配置ns1下同有几个namenode,一个nameservice下最多只能有两个namenode-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!--配置第一个namenode的信息之rpc-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop61:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop62:8020</value>
</property>
<!--配置每一个namenode之http.可以省略-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop61:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop62:50070</value>
</property>
<!--配置两个namenode元数据保存的目录,可以指定两个或更多,没有指定某个具体的namenode ,这两目录下的保存的数据将会完全一样-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/app/hadoop/disk1/dfs/name,/app/hadoop/disk2/dfs/name</value>
</property>
<!--配置data数据保存的目录,可以指定多个,数据分散保存到不同的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/app/hadoop/disk1/dfs/data,/app/hadoop/disk2/dfs/data</value>
</property>
<!--配置journalnode保存edits的目录,最后的ns1不一定要与nameservice的名称一样
因为,它会在${dfs.journalnode.edits.dir}/ns目录下
-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop61:8485;hadoop62:8485;hadoop63:8485/ns</value>
</property>
<!--指定journal日志保存的目录,这个目录只能是一个,不能是多个只能是一个目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/app/hadoop/journal</value>
</property>
<!--有了上面的目录,还需要为每一个namenode配置日志目录吗,以下两个目录下保存的数据完全一样-->
<property>
<name>dfs.namenode.edits.dir</name>
<value>/app/hadoop/disk1/edits,/app/hadoop/disk2/edits</value>
</property>
<!--开启namenode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置自动切换的方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--配置切换时免密码登录的key-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/wangjian/.ssh/id_rsa</value>
</property>
</configuration>
mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml文件:
<configuration>
<!--配置nodemanager处理数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--开启高可靠-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--配置一个集群的名称,虽然不用,但还是要配置一下-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hadoop</value>
</property>
<!--配置resourcemanager两个-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--指定第一个resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop61</value>
</property>
<!--配置第二个resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop62</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop61:2181,hadoop62:2181,hadoop63:2181</value>
</property>
<!-- 配置Mapper数据本地溢出缓存目录-->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/app/hadoop/nm-local-dirs/1,/app/hadoop/nm-local-dirs/2</value>
</property>
</configuration>
slaves文件:
hadoop61
hadoop62
hadoop63
步4、配置hadoop环境变量
$ sudo vim etc/profile.d/hadoop.sh
export HADOOP_HOME=/app/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
配置好以后,检查hadoop的版本:
$ hdfs version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r
085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using app/hadoop-2.7.6/share/hadoop/common/hadoop-common-2.7.6.jar
步5、分发文件到其他主机
拷贝hadoop目录:
$ scp -r hadoop-2.7.6/ hadoop63:/app/
拷贝hadoop环境变量文件:
$ scp etc/profile.d/hadoop.sh root@hadoop63:/etc/profile.d/
步6、启动zookeeper
$ app/zookeeper-3.4.12/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: app/zookeeper-3.4.12/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
检查zookeeper进程:
[wangjian@hadoop61 app]$ jps
1536 Jps
1518 QuorumPeerMain
检查zookeeper角色:
$ app/zookeeper-3.4.12/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: app/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: follower
步7、启动journalnode
在本机启动:
$ /app/hadoop-2.7.6/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to
/app/hadoop-2.7.6/logs/hadoop-wangjian-journalnode-hadoop61.out
使用ssh命令,分别启动其他两台服务器的JournalNode:
[wangjian@hadoop61 app]$ ssh hadoop62 '/app/hadoop-2.7.6/sbin/hadoop-daemon.sh start journalnode'
starting journalnode, logging to
/app/hadoop-2.7.6/logs/hadoop-wangjian-journalnode-hadoop62.out
[wangjian@hadoop61 app]$ ssh hadoop63 '/app/hadoop-2.7.6/sbin/hadoop-daemon.sh start journalnode'
starting journalnode, logging to
/app/hadoop-2.7.6/logs/hadoop-wangjian-journalnode-hadoop63.out
检查启动JournalNode的主机,是否已经都启动了JournalNode进程。
步8、格式化hdfs
在某台设置了namenode的服务器上执行以下命令格式化namenode:
$ hdfs namenode -format
将格式化的目录,同步copy到另一个namenode服务器上:
$ scp -r hadoop hadoop62:/app/
步9、格式化zkfc
在某个namendoe服务器上,执行格式化zkfc的工作:
$ hdfs zkfc -formatZK
格式化完成以后,查看zookeeper的目录:
[zk: localhost:2181(CONNECTED) 0] ls /
[zoo, zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[ns1]
其中hadoop-ha就是hadoop-ha目录。
步10、启动hdfs
使用命令:start-dfs.sh启动hadoop:
[wangjian@hadoop61 app]$ /app/hadoop-2.7.6/sbin/start-dfs.sh
Starting namenodes on [hadoop61 hadoop62]
hadoop62: starting namenode, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-namenode-hadoop62.out
hadoop61: starting namenode, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-namenode-hadoop61.out
hadoop63: starting datanode, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-datanode-hadoop63.out
hadoop61: starting datanode, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-datanode-hadoop61.out
hadoop62: starting datanode, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-datanode-hadoop62.out
Starting journal nodes [hadoop61 hadoop62 hadoop63]
hadoop62: journalnode running as process 1427. Stop it first.
hadoop63: journalnode running as process 1423. Stop it first.
hadoop61: journalnode running as process 1624. Stop it first.
Starting ZK Failover Controllers on NN hosts [hadoop61 hadoop62]
hadoop61: starting zkfc, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-zkfc-hadoop61.out
hadoop62: starting zkfc, logging to /app/hadoop-2.7.6/logs/hadoop-wangjian-zkfc-hadoop62.out
启动以后,包含以后进程:
[wangjian@hadoop61 app]$ jps
2646 DFSZKFailoverController
1624 JournalNode
2713 Jps
2218 NameNode
2317 DataNode
1518 QuorumPeerMain
步11、启动yarn
在所有的yarn.resourcemanager指定的机器上启动yarn:
$ /app/hadoop-2.7.6/sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/app/hadoop-2.7.6/logs/yarn-wangjian-resourcemanager-hadoop61.out
hadoop63: starting nodemanager, logging to
/app/hadoop-2.7.6/logs/yarn-wangjian-nodemanager-hadoop63.out
hadoop62: starting nodemanager, logging to
/app/hadoop-2.7.6/logs/yarn-wangjian-nodemanager-hadoop62.out
hadoop61: starting nodemanager, logging to
/app/hadoop-2.7.6/logs/yarn-wangjian-nodemanager-hadoop61.out
检查所有服务器上进程是否和规划的进程一样。
步12、检查网页状态
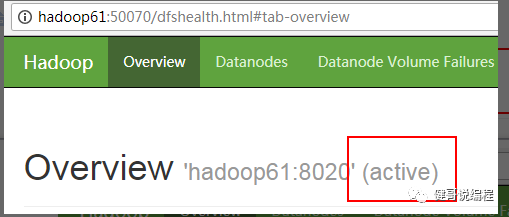
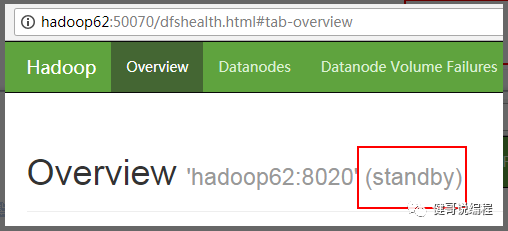
也可以通过命令来判断:
[wangjian@hadoop63 app]$ hdfs haadmin -getServiceState nn1
active
[wangjian@hadoop63 app]$ hdfs haadmin -getServiceState nn2
standby
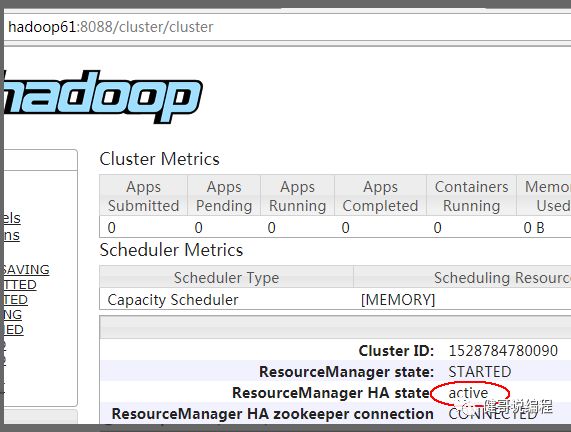
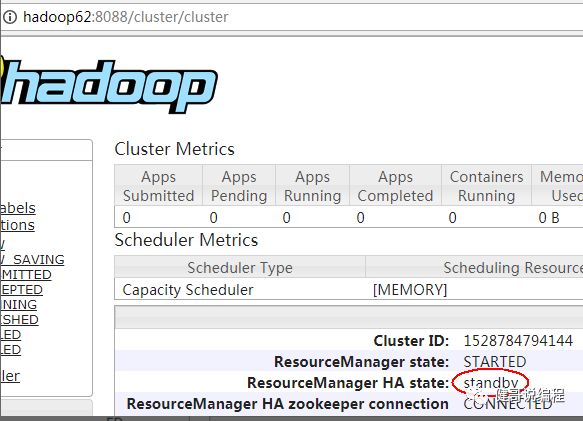
也可以通过命令来获取状态:
[wangjian@hadoop63 app]$ yarn rmadmin -getServiceState rm1
active
[wangjian@hadoop63 app]$ yarn rmadmin -getServiceState rm2
standby
步13、保存数据测试
向hdfs保存数据测试。
在ha环境下,测试mapreudce程序测试。
步13、切换测试
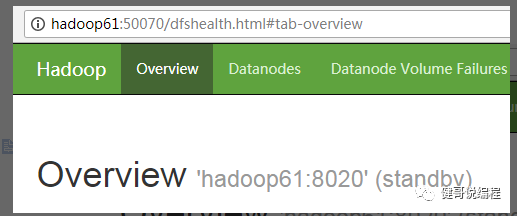
现在将hadoop61上的namenode进程使用kill -9杀死。然后再查看hadoop62上的namenode状态,可见已经成为active:
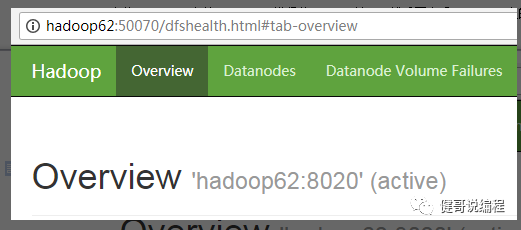
再重新启动hadoop61,它会成为standby:
$ hadoop-deamon.sh start namenode
同样的方法,测试ResourceManager:
小结:
1:可以在一台进程不是很多的机器上启动mapreduce的JobHistoryServer。
2:再次启动时,请先启动zookeeper,然后再启动hdfs和yarn即可。只有第一次启动时,必须要手工的启动JournalNode。
步14、Java代码操作ha集群
在windows的idea环境下,将配置集群配置文件:core-site.xml,hdfs-site.xml,mapred-site.xml和yarn-site.xml文件,放到项目的classpath目录下,然后就可以在eclipse中读写hdfs上的文件了:
项目的结果如下:
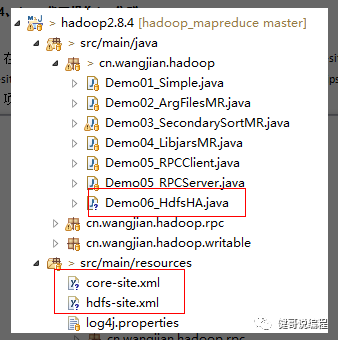
以下是完整代码:
package cn.wangjian.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 操作HA的hdfs文件示例
* @author wangjian
* @version 1.0 2018年6月12日
*/
public class Demo06_HdfsHA extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration config = getConf();
FileSystem fs = FileSystem.get(config);
RemoteIterator<LocatedFileStatus> it = fs.listFiles(new Path("/"),true);
while(it.hasNext()) {//读取根目录下的文件
LocatedFileStatus file = it.next();
System.out.println(">>:"+file.getPath());
}
boolean boo = fs.mkdirs(new Path("/abc"));
System.out.println("创建成功:"+boo);
fs.close();
return 0;
}
public static void main(String[] args) throws Exception {
int code = ToolRunner.run(new Demo06_HdfsHA(),args);
System.exit(code);
}
}
步15、停止集群
停止hdfs:
[wangjian@hadoop61 ~]$ /app/hadoop-2.7.6/sbin/stop-dfs.sh
Stopping namenodes on [hadoop61 hadoop62]
hadoop62: stopping namenode
hadoop61: stopping namenode
hadoop63: stopping datanode
hadoop61: stopping datanode
hadoop62: stopping datanode
Stopping journal nodes [hadoop61 hadoop62 hadoop63]
hadoop62: stopping journalnode
hadoop63: stopping journalnode
hadoop61: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [hadoop61 hadoop62]
hadoop62: stopping zkfc
hadoop61: stopping zkfc
停止yarn:
[wangjian@hadoop61 ~]$ /app/hadoop-2.7.6/sbin/stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
hadoop62: stopping nodemanager
hadoop61: stopping nodemanager
hadoop63: stopping nodemanager
hadoop62: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
hadoop61: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
hadoop63: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
停止zookeeper:
$ zkServer.sh stop
欢迎关注-共同交流技术:

