




1、剖析MapReduce的工作机制
1、提交MapReduce作业的方式:
(1) 调用Job对象的submit。
(2) 调用waitForComplete(true),它用于提交之前没有提交过的作业,并等待它的完成。
2、MapReduce作业的工作原理图解
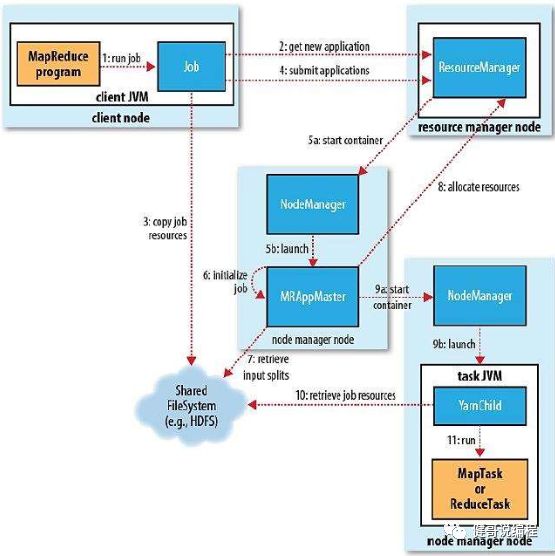
1. 提交作业后,waitForCompletion()每秒轮询作业的进度。如果发现自上次报告有改变,便将进度报告输出到控制台。
2. 作业完成后,如果成功,就显示计数器。如果失败显示作业失败的信息。
3. 运行作业所需要的资源(包含jar文件,配置文件和计算所需得到的输入分片)复制到一个以作业ID命名的目录下的共共享文件系统中(图中步3)。作业Jar的副本较多(由mapreduce.client.submit.file.replication属性控制,默认为10份),因此在运行作业时,集群中有很多个复本可供节点管理器访问。
4. MapRecude作业的application master是一个java应用程序,它的主类是:MRAppMaster。
5. mapreduce.job.reduces用于设置reduce的数量,默认值为每一个job只有1个。也可以通过作业的setNumReduceTasks()来设置。
6. 哪些作业是小作业?默认情况下,小作业就是少于10个mapper且只有一个reducer,且输入大小小于一个hdfs块的作业。
7. Reduce任务可以在集群的任意位置运行,但map任务的请求有着本地化局限。
8. 在默认的情况下,每个map和reduce任务都分配到1024MB的内存和一个虚拟的内核。可以进行配置:mapreduce.map.memory.mb、mapreduce.reduce.memory.mb、mapreduce.map.cpu.vcores、mapreduce.reduce.cpu.vcorse。
9. 在map和reduce任务运行时,子进程和自己的父application master通过umbilical接口通信。每3秒一次。子进程向app master报告进程和状态,包含计数器。
10. 在作业期间,客户端每一秒轮询一次application master,以接收最新的状态。轮询的时间可以通过mapreduce.client.progressmonitor.pollinterval来设置。客户端也可以通过Job的getStatus方法得到一个JobStatus的实例。JobStatus包含作业的所有详细信息。
11. 运行MapReduce application master的最多尝试次数由mapreduce.am.max-attempts属性来控制,默认为2次。即如果两次启动app master失败,则将作业定义为失败。
12. 任务运行超时的时间默认为10分钟,即app master 如果在10(600000毫秒)分钟内没有接收到yarn child心跳信息。则app maste将某个task标记为失败。可以通过mapreduce.task.timeout修改默认时间。
13. Application master向资源管理器Resource Manager发送周期性心跳,当application master失败时,资源管理器将检查到该失败的信息,并在一个新的容器中开始一个新的master实例。
14. 如果节点管理器NodeManager由于崩溃或运行非常缓慢而失败,就会停止向资源管理器发送心跳信息(或发送频率特别低)。如果10分钟(yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms)内没有收到一条心跳,资源管理器将会通知停止发送心跳信息的节点管理器,并将它从自己的节点池中移除。
15. 资源管理器ResourceManager失败,是非常严重的问题,为获得高可可用(HA),在双机热备配置下,运行一对资源管理器是必要的。
16. 资源管理器从备机到主机的切换是由故障转移控制器(failover Controller)处理的。故障转移控制器必须是一个独立的进程,为配置方便,默认情况下嵌入在资源管理器中。
3、Shuffle与排序
1. MapReduce确保每个reducer的输入(即Map的输出都是已经经过排序的)都是按键排序的。系统执行排序、将Map输出做为输入传递给reducer的过程叫shuffle。
2. Shuffle是MapReduce的心脏。
3. Map函数开始产生数据时,并不是简单的将数据写到磁盘。它利用缓冲区的方式写到内在并排序。如下图:
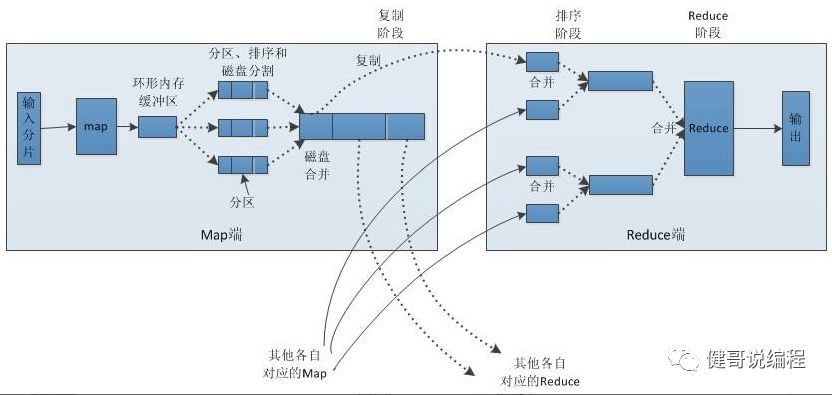
4. 每一个map任务都有一个环形内在缓冲区用于存储任务输出。缓冲区默认大小为100M。可以通过mapreduce.task.io.sort.mb来配置。一旦缓冲区内容达到阀值(mapreduce.map.sort.spill.percent=0.8),一个后台线程,就会将内容溢写(spill)到磁盘。溢写目录通过mapreduce.cluster.local.dir配置,默认值为:${hadoop.tmp.dir}/mapred/local。
5. mapreduce.task.io.sort.factor控制着一次最多合并多少个文件,默认为10。
6. 如果至少存在至少3个溢出文件(mapreduce.map.combine.minspills:没有在官网上找到这个配置),Combiner会在输出文件写到磁盘之前多次运行,但不影响最终的结果。
7. 在map输出数据时,进行数据压缩是一个很好主意。因为这样将减少写磁盘的频率、节省磁盘空间,并且减少传递给reducer的数据量。Mapeduce.map.out.compress=true及mapreduce.map.out.compress.codes来设置。
8. Reduce通过http协议获取输出文件的分区信息。
4、溢写
关于溢写,见上面的3.4中所述。
其中有三个相关的配置:
mapreduce.task.io.sort.mb : 用于指定内存缓存区的大小。默认为100M。
mapreduce.map.sort.spill.percent :内在缓存区的阀值。默认为0.8。
mapreduce.cluster.local.dir :本地溢写目录。默认为${hadoop.tmp.dir}/mapred/local。
