





Spark的运行模式
参考:http://blog.csdn.net/gamer_gyt/article/details/51833681
Spark有三种运行模式:
1:Local本地模式。
2:伪分布式模式,即使用Standalone集群管理器。
3:Yarn分布式模式或是mesos。即Spark运行在Yarn或是mesos上。
2.1.1、Local本地模式
Spark on Locak也叫本地模式。在这种情况下,不需要安装Hadoop hdfs及yarn。只要将Spark安装程序解压到某个目录下,并运行pyspart或是spark-shell,即启动一个RDD Driver即为本地模式。
如运行:
$SPARK_HOME/bin/spark-shell
或是
$SPART_HOME/bin/spark-shell --master local[1]
如果使用maven导入spark-core的依赖包,也可以通过Scala或是Java代码开始一个本地模式的运行。后面你将会见到这些代码。
1、Local模式的安装
步1:下载Spark
下载地址:
http://spark.apache.org/downloads.html
选择Spark的版本,建议使用*.*.2版本的,选择支持的hadoop版本。注意支持的hadoop后面有一个 2.7 and later 即支持2.7及2.7以后版本,如2.8。

步2:安装Spark
local模式安装Spark非常简单,甚至不需要修改任何的配置文件。
只要将Spark解压然后启动一个RDD即可。
在linux根目录下,创建spark目录,用于安装spark:(也可以是你喜欢的其他目录)
$sudo mkdir spark
修改这个目录的拥有者:(如果你的root用户,此步忽略,但本人真不建议你使用root用户)。本人姓名王健,使用的用户名的组名均为wangjian。
$cd spark
$sudo chown wangjian:wangjian .
上传spark-2.1.2-hadoop2.7.x.tar.gz到这个目录下:(使用rz可以实现快速上传,如果没有请先安装:yum install lrzsc)
$rz
解压
$ tar -zxvf spark-2.1.2-hadoop2.7.tar.gz
修改目录,由于spark目录太长,为了方便使用,所以修改目录名称
$ mv spark-2.1.2-bin-hadoop2.7 spark
$ ls
spark
查看spark的目录结构:
$ ls
bin conf data examples jars LICENSE licenses NOTICE python R README.md RELEASE sbin yarn
步3:启动一个Spark-Driver
就是启动一个Spark Shell。Spark Shell有两种分为是:Python shell和Scala shell。
默认为Spark shell。要打开 Python 版本的 Spark shell,只要进入你的 Spark/bin 目录然后输入:
bin/pyspark
如果要打开 Scala 版本的 shell,输入:
bin/spark-shell
由于Spark的底层为Scala写的,所以,默认spark-shell将使用Scala的Shell。
启动独立模式的Spack Driver可以使用以下命令:
./spark-shell
./spark-shell --master local[2] 其中--master是指定连接的主机,local则是指本地,里面的数字为核数。
$ ./spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/12/06 08:27:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://192.168.56.201:4040
Spark context available as 'sc' (master = local[*], app id = local-1512566869755).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ __
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ _/\_\ version 2.1.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
启动以后,将打开一个交互式的界面。
通过上面的信息,分析得到:
1:设置默认的日志级别为WARN。如果需要修改,可以修改/spark/log4j.properties,如果没有这个日志文件,可以自行创建,这对于JAVAEE的程序员来说,不是什么难事。
2:启动一个Web UI 地址为:http://192.168.56.201:4040做为UI的管理界面。
3:创建SparkContext对象,变量名为sc。可以通过这个变量,与spark进行交互。
4:Spark版本及Spark内部Scala的版本为2.11.8。
5:最后将显示一个scala>的命令行。做为交互。
步4:命令示例
读取本地文件,以下不会检查这个文件是否存在,只有在使用这个文件时,才会去检查这个文件是否存在,即懒加载。如果使用file://将会读取Linux系统文件,如果直接输入某个文件,则读取的为hdfs上保存的文件:
scala> val rdd1 = sc.textFile("file:///spark/spark/README.md");
rdd1: org.apache.spark.rdd.RDD[String] = file:///spark/spark/README.md MapPartitionsRDD[1] at textFile at <console>:24
可以直接输出rdd1 , 根据Scala语法,rdd1为一个常量,它表示一个文件对象
scala> rdd1
res0: org.apache.spark.rdd.RDD[String] = file:///spark/spark/README.md MapPartitionsRDD[1] at textFile at <console>:24
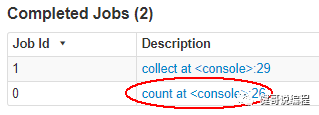
统计数据集中的行数,如果不记得它的命令,可能按两次Tab,则会显示帮助。以下将会执行一个Job。
scala> rdd1.count();
res1: Long = 104
上面的语法,将会执行一个Job任务,在执行完成以后,可以通过4040端口查看到这个任务的情况:
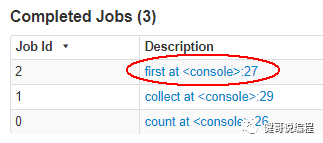
显示这个数据集中的第一行
scala> rdd1.first();
res2: String = # Apache Spark
也会执行一个任务。通过4040端口的UI可以查看到这个任务:
过虑每一行中,包含Spark的行,注意区分大小写
scala> val rdd2 = rdd1.filter(line=>line.contains("Spark"));
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:26
注意,由于Spark大量使用了懒加载,所以,上面的语句,如果在没有使用结果的情况下,不会执行,即在UI界面上,查看不到这个Job。
显示过虑的结果
scala> rdd2.collect();
res3: Array[String] = Array(# Apache Spark, Spark......
此时即是要显示filter执行的结果,此时才会去执行过虑任务,从而会显示一个collect的Job:
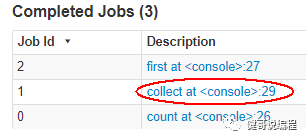
#显示rdd2第一行
scala> rdd2.first();
res4: String = # Apache Spark
单词统计
scala> var r1 = arr.flatMap(line=>line.split(" ")).map(word=>(word,1)).groupBy(value=>value._1).map(t=>(t._1,t._2.size)).foreach(println);
(Jack,1)
(Hello,3)
(Mary,1)
(Rose,1)
r1: Unit = ()
Spark-Shell默认使用Scala语言,所以,之前学习的Scala语法,可以在命令行中,尽情的输入。这也是之前所说的交互式编程。
步5:查看UI
在启动一个Driver/RDD之后,可以通过4040查看WebUI从而获取这个RDD的运行信息:
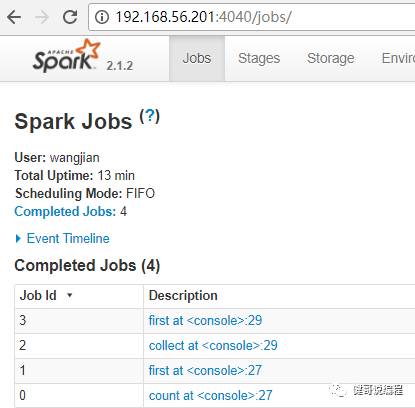
在Completed Jobs中,可以看到执行过的Scala任务。
步6:后台进程
启动独立的Spark以后,会发现一个Spark的进程:SparkSubmit,如下所示。
[wangjian@hadoop201 ~]$ jps
1079 SparkSubmit
关于SparkSubmit进程的说明:/TODO:
参考文章:http://blog.csdn.net/UUfFO/article/details/78419299?locationNum=10&fps=1
步7:Scala代码本地模式
使用IDEA或Eclipse添加依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.2</version>
</dependency>
如果在IDEA中创建的是一个Maven项目,为了支持Scala应该添加Scala的支持:
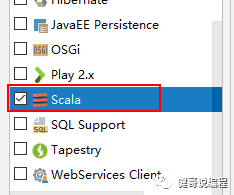
在弹出的界面上,选择Scala即可:
键入以下代码:
package cn.wang
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 本地模式
*/
object SparkDemo01 {
/**
* Scala的入口程序
*
* @param args
*/
def main(args: Array[String]): Unit = {
//定义SparkConfig对象
val config: SparkConf = new SparkConf();
//设置为本地模式,注意最后的local
config.setAppName("MyFirstName").setMaster("local");
//声明SparkContext对象
val sc: SparkContext = new SparkContext(config);
//通过读取文件获取一个RDD,其中:RDD即变量类型可以省略,[String]可以理解为Java中的泛型
val rdd: RDD[String] = sc.textFile("D:/b/HelloWorld.scala");
//统计行数
val count: Long = rdd.count();
println("Count is:" + count);
//单词统计
val wordlist = rdd.flatMap(line => line.split("\\s+")) //行处理,根据空格分开
.filter(word => word.matches("[,}]").!=(true)) //可以去除,}之类的单词
.map(word => (word, 1)) //每一个单词算1
.groupBy(keyValue => keyValue._1) //根据key进行分组输出:hello,Comparable(1,1,1,1,)
.map(obj => (obj._1, obj._2.size)); //第二个值的size即为个数
//显示所有单词,遍历显示所有单词
wordlist.foreach(m => {
println("统计信息:" + m._1 + "," + m._2);
});
println("阻塞以便于查看UI界面....")
Thread.sleep(1000 * 60 * 5); //直接使用Java的阻塞就可以
sc.stop(); //停止
println("程序在5分钟以后停止")
}
}
运行的结果如:
统计信息:,13
统计信息:object,1
统计信息:println("HelloWorld");,1
统计信息:main(args:Array[String]){,1
统计信息:HelloWorld{,1
统计信息:def,1
步8:Java代码本地模式
同上面一样,需要添加spark-core的依赖库。
现在键入以下代码:
package cn.wang.java;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.rdd.RDD;
import scala.Function1;
import scala.collection.TraversableOnce;
/**
* 使用java代码,操作本地模式的Spark
*/
public class SparkDemo01 {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf();
conf.setAppName("JavaTest").setMaster("local");//本地模式
SparkContext sc = new SparkContext(conf);
//Scala中返回的是RDD[T]可以将这个T理解为Java的泛型
RDD<String> rdd = sc.textFile("D:/b/HelloWorld.scala", 1);
Long count = rdd.count();
System.err.println("行数为:"+count);
sc.stop();
}
}
Java代码大量使用内部类实现单词的统计,本人没有去研究这些内部类,请自行处理。
步9:使用spark-submit运行
也可以使用spark-submit运行一个jar文件。spark-submit命令的基本语法为:
./bin/spark-submit \ 命令
--class <main-class> \ 入口程序所在的类
--master <master-url> \local或是spark://ip:7077
--deploy-mode <deploy-mode> \ 部署Driver在本地Client还是集群cluster,默认为client --conf <key>=<value> \ 使用key=value的形式指定的参数
<application-jar> \ jar文件
[application-arguments] \ 入口程序接收的参数
在SPARK_HOME/examples/jar目录下,有一个spart-example-2.1.2.jar,里面有很多的示例程序如SparkPI就是求 PI的精确值,运行这个程序的示例如下:
[wangjian@hadoop201 sparkshell]$ spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master local[2] \
> spark/spark/examples/jars/spark-examples_2.11-2.1.2.jar 10
由于参数比较多,也可以创建一个Linux Shell脚本文件如:
spart-pi.sh。并给这个文件添加执行权限:
chmod +x spark-pi.sh
或是:
chmod 775 spark-pi.sh
使用vim编辑器输入以下内容:
#!/bin/bash
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
/spark/spark/examples/jars/spark-examples_2.11-2.1.2.jar 100
现在,就可以执行这个文件,查看输出的结果了:
./spart-pi.sh
上面的jar包是spark中官方示例,我们也可以自己将开发的程序打开jar包,然后通过spark-submit方式来执行这个driver :
步1:创建一个maven项目并添加Scala支持
在创建成功以后,建议在main目录下,创建一个scala目录,并设置耿RootSource如下:

步2:开发Scala Class
现在添加一个最简单的Scala的类:
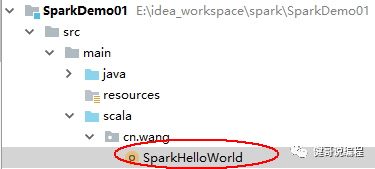
并添加最简单的一行代码:
package cn.wang
object SparkHelloWorld {
def main(args: Array[String]): Unit = {
println("Spark-Submit Hello World测试。")
}
}
步3:使用IDEA打包
使用IDEA打包,可以设置包含哪些依赖,设置的步骤如下:
进行设置:
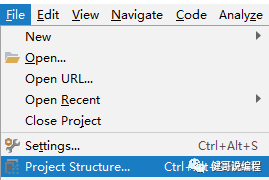
现在可以Build了:
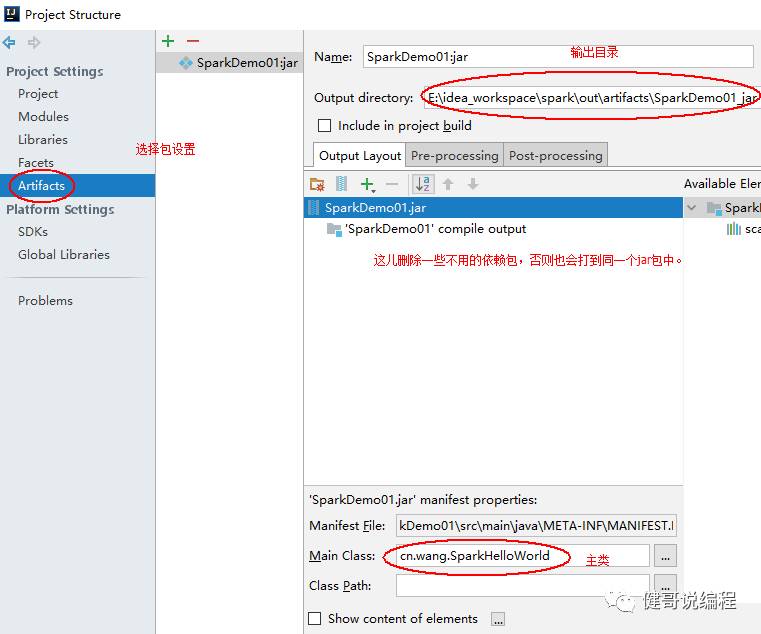
在弹出的界面上,选择Build即可:
在指定的目录下,将打包完成以后的jar文件,上传到安装有Spark的linux os上,并编写以下的shell脚本,假设名称为:submit_02.sh
#!/bin/bash
spark-submit \
--class cn.wang.SparkHelloWorld \
--master local[1] \
SparkDemo01.jar
添加x执行权限,并执行:
$ ./submit_02.sh
Spark-Submit Hello World测试。
也许上面的程序太过简单了,现在你可以写的更加复杂的程序:
步4:更复杂的程序
现在你可以开发一个更复杂的程序,如统计单词的个数:
package cn.wang
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* WordCount示例,使用Submit运行测试
* @author wangjian 王健
* @since 2017-12-09 1.0
*/
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
if (args.length <= 0) {
println("请输入文件名");
return;
}
//接收读取的文件,与java不同,通过apply获取指定下标的值
val fileName: String = args.apply(0);
//可以接收参数
val config: SparkConf = new SparkConf();
config.setAppName("MyWordCount");
//由于在spart-submit中已经传递了--master所以,这儿是可以省略的。
config.setMaster("local[2]");
//通过Config获取SpackContext
val sc: SparkContext = new SparkContext(config);
//读取用户传递的文件
val textFile: RDD[String] = sc.textFile(fileName);
//获取行数
val lineCount: Long = textFile.count();
println("文件中的数据的行数为:" + lineCount);
//进行字符分割
var wordCount: RDD[String] =
textFile.flatMap(str => str.split("\\s+"));
println("******Split之后的数据是********")
wordCount.foreach(str => {
println(str);
});
println("******Split数据显示完成*********" + wordCount + "," + wordCount.getClass);
println("\n*********开始进行单词统计***************")
val rdd: RDD[(String, Int)] = wordCount.map(word => (word, 1)).reduceByKey(_ + _);
rdd.foreach(kv => {
println("统计结果:" + kv._1 + " 个数 " + kv._2);
});
println("***********统计完成*********" + rdd + "," + rdd.getClass);
sc.stop();
}
}
然后开发一个shell脚本,用于启动这个RDD:
#!/bin/bash
if [ $# -eq 0 ]; then
echo "请输入读取的文件名"
else
echo "开始处理文件:$1"
spark-submit \
--class cn.wang.Spark02_WordCount \
--master local[2] \
SparkDemo01.jar $1
fi
现在就可以运行这个脚本并查看输出结果了。
【注意】:
shell脚本的开发有很多的限制,如if后面的格式必须是:
if空格[空格$#空格-eq空格0空格];空格then。请开发时多加注意。
步10:在local模式下操作hdfs
这种方式下,使用本地内存Dataset集,只是从HDFS中获取数据而已。
package cn.wang
import org.apache.spark.{SparkConf, SparkContext}
/**
* Local模式下操作HDFS上的文件
*/
object Spark04_WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf();
conf.setMaster("local[1]");
conf.setAppName("Local2HDFS");
val sc: SparkContext = new SparkContext(conf);
val rdd = sc.textFile("hdfs://192.168.56.201:8020/wang/a.txt");
val count = rdd.count();
println("行数:" + count);
println("*********第一种方式输出单词统计*****************")
rdd.flatMap(str => str.split("\\s+")).map(word => (word, 1)).reduceByKey(_ + _)
.collect().foreach(kv => (println(kv._1 + "," + kv._2)));
println("*********第二种方式输出单词统计******************")
rdd.flatMap(str => str.split("\\s+")).map((_, 1)).reduceByKey(_ + _)
.collect().foreach(kv => {
println(kv._1 + "," + kv._2);
});
println("********也可以将数据保存到hdfs************")
rdd.flatMap(str => str.split("\\s+")).map((_, 1))
.reduceByKey(_ + _)
//直接保存到hdfs上,保存以后的格式为:(Hello,1)
.saveAsTextFile("hdfs://192.168.56.201:8020/out001");
rdd.flatMap(_.split("\\s+")).map((_, 1)).reduceByKey((a, b) => (a + b))
.map(kv => {//再使用一次map以便于去掉()
val keyvalue = kv._1 + "\t" + kv._2;
keyvalue;//必须要独立的写上此句,但不能使用return关键字
}).saveAsTextFile("hdfs://192.168.56.201:8020/out002");
sc.stop();
}
}
检查hdfs上的数据:
[wangjian@hadoop201 hadoop]$ hdfs dfs -cat /out001/*
(Hello,3) //默认是带有( )的
(Alex,1)
(Mary,1)
(Jack,1)
[wangjian@hadoop201 hadoop]$ hdfs dfs -cat /out002/*
Hello 3 //通过 map去掉( )之后的情况
Alex 1
Mary 1
Jack 1
小结:
1:Local模式,就是直接使用spart-shell启动一个驱动器。
2:使用Scala或Java在集成环境如IDEA/Eclipse中运行Local模型,本质上就是在当前环境下开启一个Local模式。
