




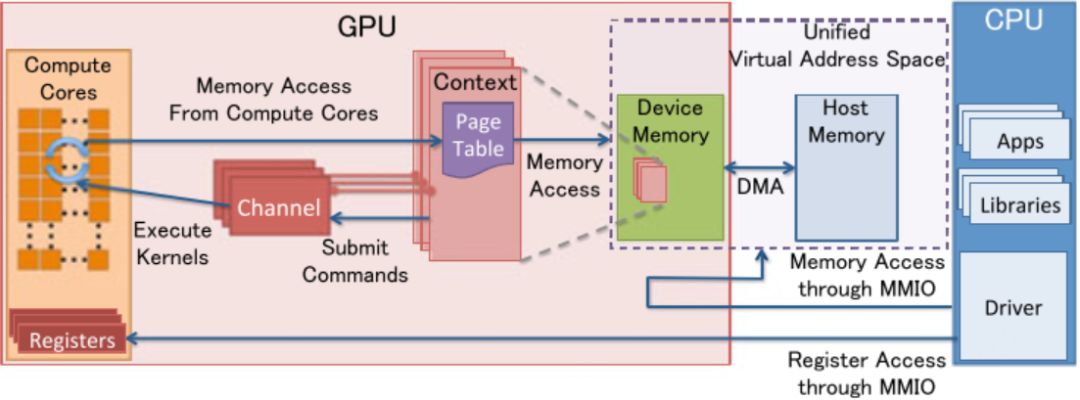
GPU模型
1.1 MMIO
CPU和GPU之间的通信,使CPU对GPU寄存器的访问同内存访问一样容易;通过配置MMIO,使得DMA引擎可以传输大量数据。
1.2 GPU Context
GPU计算状态的表示,分配了GPU内部的虚拟地址空间,支持多状态共存。
1.3 GPU Channel
GPU执行的所有操作都是host端提交(issue)到具体的GPU channel(同DMA Engine的channel相似);一个context(session)可以对应多个channel;channel处理的单位是channel page descriptor;Page descriptor中的command buffer通过MMIO配置或描述;page table负责将虚拟地址翻译成物理地址。
1.4 PCIe Bar
1.4 PCIe Bar
host给GPU分配的PCIe基地址。配置PCIe的BARs(MMIO映射的寄存器窗口),GPU初始化时配置,在host访问时使用。
1.5 PFIFO Engine
与提交操作有关,组织来自host的命令缓冲的处理命令并提交给PGRAPH(内存拷贝,2D、3D rendering engine,“渲染或表现”引擎)和PVPE(encoding/decoding)引擎。
编程模型
2.1 kernels,核函数
Kernel function是并行的运行在GPU上的函数,上一章中介绍的dim3和hello函数都是关于kernel的描述:Dim3用于描述kernel在GPU上的布局(通过grid、block以及thread如何并发的执行kernel function),hello是kernel的实现。每一个用于执行kernel function的thread都会分配一个全局唯一的thread id(唯一的thread id会在kernel中做一些同步或保护),关于不同dim3下的thread id的计算请参考:Cuda编程(四):Thread Index的计算。
以下代码是一段涉及host和device的通信的kernel function实现,
// Kernel definition__global__ void VecMultiply(float *pDataA, float *pDataB, float *pResult){// We already set it to 256 threads per block, with 128 thread blocks per grid row.int tid = (blockIdx.y * 128 * 256) + blockIdx.x * 256 + threadIdx.x; // This gives every thread a unique ID.pResult[tid] = sqrt(pDataA[tid] * pDataB[tid] 12.34567) * sin(pDataA[tid]);}int main(){...// Kernel invocation with N threadsVecMultiply<<<1, N>>>(A, B, R);...}
“__global__”标明该kernel既可以在host调用也可以在device端执行。
2.2 Thread Hierarchy,线程层次
Grid和block可以各自为1维、2维和3维的,通过将多维的grid、block和thread及各自的索引计算出全局唯一的thread index,grid和block的映射参考图2。
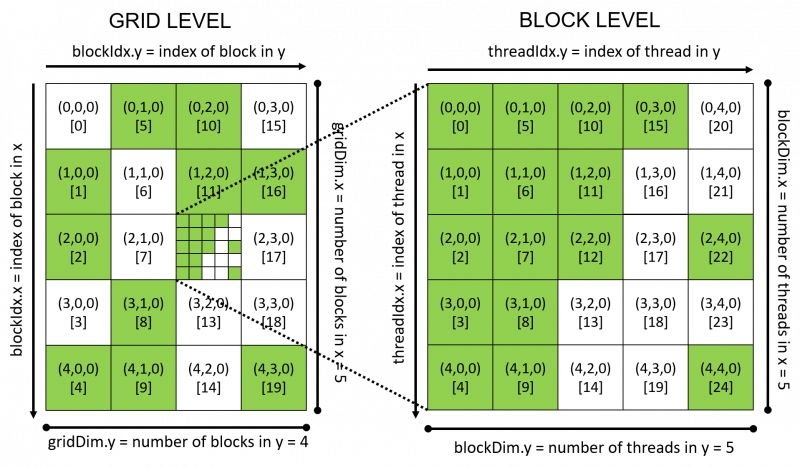
当我们配置GPU的核函数计算网络时要根据GPU的硬件限制合理配置硬件允许的每个grid中block数目和block内允许的thread的最大数目,以免超出硬件计算能力,超出后要重新设计grid和block的维数。
同一个block中的thread间的共享内存依赖__syncthreads()进行同步(类似于barrier()的行为)。
2.3 Memory Hierarchy,内存层次
如图2所示,每个thread都有自己/私有的本地内存,每个thread block的共享内存对该block内的所有thread可见并保持一致的生命周期,全局内存对所有的thread(kernel0/kernel1或grid0/grid1内的)可见。
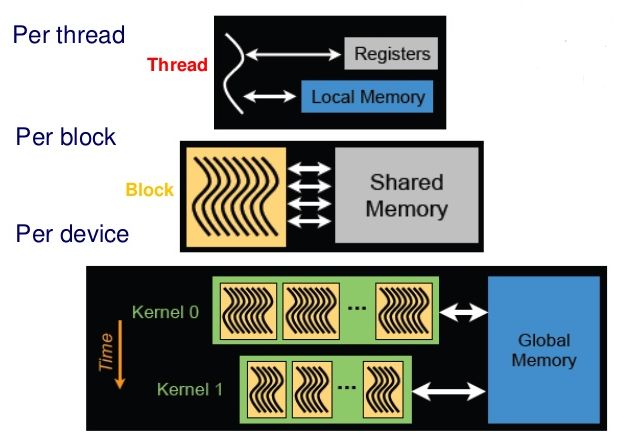
图3 CUDA内存模型
2.4 异构编程
在CUDA编程里异构计算指host部分代码运行在CPU侧,kernel function运行于GPU(device端),两部分代码相互独立(可参考:Cuda编程(二):GPU架构基础中的host和device修饰符部分),如图3所示:
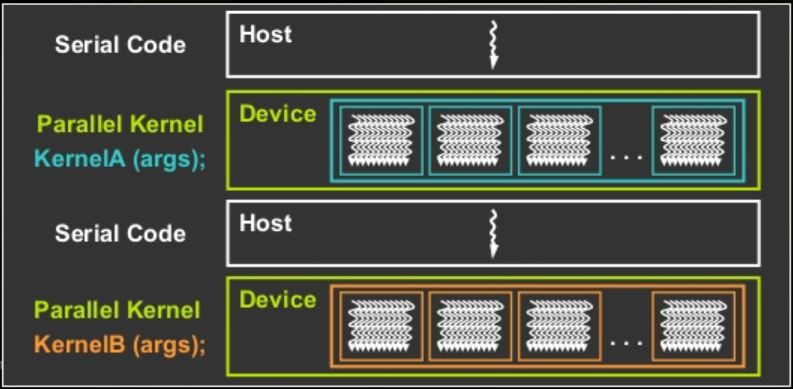
Serial Code执行在CPU侧,当kernel<<<g, b>>>(args...)执行后,kernel将运行在Device侧的不同thread内以实现并行性。
2.5 内存拷贝
基于2.4节的异构计算,CPU负责初始化数据、配置GPU工作模式、核函数的分配等工作,然后将初始数据交给GPU不同的thread计算出结果,host等待device计算完成后将核函数的计算结果汇总给host呈现出来。那么host端的数据是如何同device进行同步呢?我们首先明确CPU和GPU之间的内存并不互相可见,即CPU无法直接操作GPU的内存,GPU也无法直接看到CPU初始化后的数据。CUDA为我们提供了专门用于CPU和GPU间数据同步的接口:cudaMemcpy(…, direction),direction:cudaMemcpyHostToDevice和cudaMemcpyDeviceToHost为控制数据拷贝的方向:从CPU->GPU和GPU->CPU。同时增加的还有用于内存分配和释放的CUDA接口:cudaMalloc和cudaFree。
依赖于以上接口,我们继续完成我们的float型数相乘的kernel function,CPU侧代码如下:
////////////////////////////////////////////////////////////////////////////////// Main program////////////////////////////////////////////////////////////////////////////////int main(int argc, char **argv) {float *h_dataA, *h_dataB, *h_resultC;float *d_dataA, *d_dataB, *d_resultC;int i;printf("Initializing data...\n");h_dataA = (float *)malloc(sizeof(float) * MAX_DATA_SIZE);h_dataB = (float *)malloc(sizeof(float) * MAX_DATA_SIZE);h_resultC = (float *)malloc(sizeof(float) * MAX_DATA_SIZE);CUDA_SAFE_CALL(cudaMalloc( (void **)&d_dataA, sizeof(float) * MAX_DATA_SIZE));CUDA_SAFE_CALL(cudaMalloc( (void **)&d_dataB, sizeof(float) * MAX_DATA_SIZE));CUDA_SAFE_CALL(cudaMalloc( (void **)&d_resultC , sizeof(float) * MAX_DATA_SIZE));srand(123);for(i = 0; i < MAX_DATA_SIZE; i++) {h_dataA[i] = (float)rand() (float)RAND_MAX;h_dataB[i] = (float)rand() (float)RAND_MAX;}for (int dataAmount = MAX_DATA_SIZE; dataAmount > 128*256; dataAmount /= 2) {int blockGridWidth = 128;int blockGridHeight = (dataAmount 256) blockGridWidth;dim3 blockGridRows(blockGridWidth, blockGridHeight);dim3 threadBlockRows(256, 1);// Copy the data to the deviceCUDA_SAFE_CALL( cudaMemcpy(d_dataA, h_dataA, sizeof(float) * dataAmount, cudaMemcpyHostToDevice));CUDA_SAFE_CALL( cudaMemcpy(d_dataB, h_dataB, sizeof(float) * dataAmount, cudaMemcpyHostToDevice));// Do the multiplication on the GPUVecMultiply<<<blockGridRows, threadBlockRows>>>(d_dataA, d_dataB, d_resultC);CUT_CHECK_ERROR("VecMultiply() execution failed\n");CUDA_SAFE_CALL(cudaThreadSynchronize());// Copy the data back to the hostCUDA_SAFE_CALL(cudaMemcpy(h_resultC, d_resultC, sizeof(float) * dataAmount, cudaMemcpyDeviceToHost));// We discard the results of the first run because of the extra overhead incurred// during the first time a kernel is ever executed.dataAmount *= 2; // reset to first run value}printf("Cleaning up...\n");CUDA_SAFE_CALL(cudaFree(d_resultC));CUDA_SAFE_CALL(cudaFree(d_dataB));CUDA_SAFE_CALL(cudaFree(d_dataA));free(h_resultC);free(h_dataB);free(h_dataA);CUT_SAFE_CALL(cutDeleteTimer(hTimer));}
CUDA_SAFE_CALL宏定义参考:https://docs.nvidia.com/cuda/nvrtc/index.html
