





什么是数据仓库?
数据仓库是将多个数据源的数据,经过ETL处理之后,按照一定的主题集成起来,提供决策支持和联机分析应用的结构化数据环境。
举个栗子了解数据仓库
以银行业务为例。数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来。这里我们可以简单地理解为用数据库记帐。
银行会综合事务系统的这些数据,对他们进行汇总、加工。比如,计算某银行某分行一个月发生多少交易,该分行当前存款余额是多少。如果存款又多,消费交易又多,那么该地区就有必要设立ATM了。
事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。
分析系统是事后的,它要提供关注时间段内所有的有效数据。这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就达到目的。
以上我们就可以看出数据库和数据仓库的区别,数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库”。
我们在面试的时候也会经常被问到数据库和数据仓库的区别、OLTP和OLAP的区别等等,进而延伸出数据仓库设计、优化等等相关的题目。
OLTP也叫联机事务处理 它是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易
OLAP是联机分析处理,是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
数据仓库中的数据流程
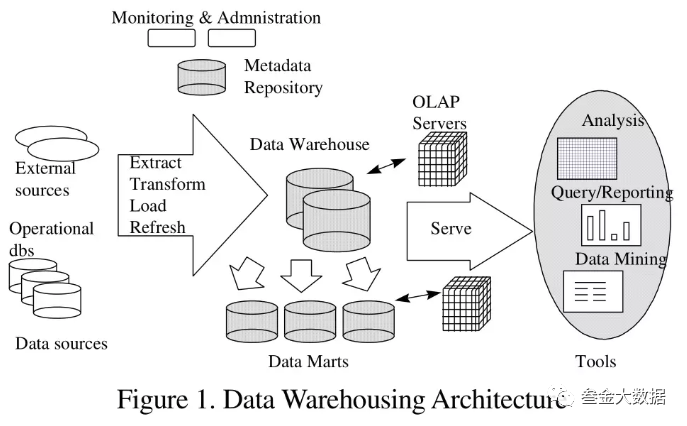
从左往右大家可以看到,我们的DataSource分为业务数据库和外部数据源 (多种数据源),然后通过中间的ETL流程,将数据落入数据仓库,这个过程中需要对其进行监控和权限控制,这部分在图片上方有所体现,具备数据的数据仓库可以直接对外提供OLAP分析,也可以对数据进行分类,按主题或者业务分割成一个一个的Data Marts 也就是数据集市,为各种查询分析引擎提供数据。比如各种数据查询分析应用、数据报表、BI工具等等。可以说,数据仓库就是我们的数据平台的中心,它的建设是大数据平台建设过程中最重要的一个环节。
前面的文章提到了我们面临的问题,包括各个业务的数据格式不统一,数据关系混乱等等。我们可以通过数据仓库集中的管理数据,针对业务构建对应的数据集市,提供一致的,结构清晰的数据。
数据仓库是多源的复杂环境,可以帮助我们摆脱多种数据源、异构数据库、n种数据格式等等问题,基于数据仓库可以做到对多个业务数据进行统一分析, 发挥数据的最大价值。
所以我们需要构建一个数据仓库,我们要实现集成多源数据,记录数据来源和去向,并梳理各个数据的血缘关系,帮助我们追溯数据生成过程。通过对数据进行可控的冗余,用空间换时间,避免重复计算。
最终的目标就是屏蔽底层业务逻辑,对外提供一致的、结构清晰的数据。
数据仓库的分层建设
在早些时候,大数据领域还没有现在广为人知的一些规范,在进行数据建设的时候,很多的数据经过粗暴的数据接入之后就存储到数据仓库当中,然后直接提供给业务。
数据建设发展到一定阶段,发现数据的使用杂乱无章,我们满心期待的数据仓库变成了制约数据建设的数据沼泽。
各种业务都是从原始数据直接计算而得,存在大量重复计算,严重浪费了计算资源,需要优化性能。
所以提出了数据仓库的数据分层概念:
屏蔽原始数据的异常:通过数据分层管控数据质量
屏蔽业务的影响:不必改一次业务就需要重新接入数据
复杂问题简单化:将复杂的数仓架构分解成多个数据层来完成
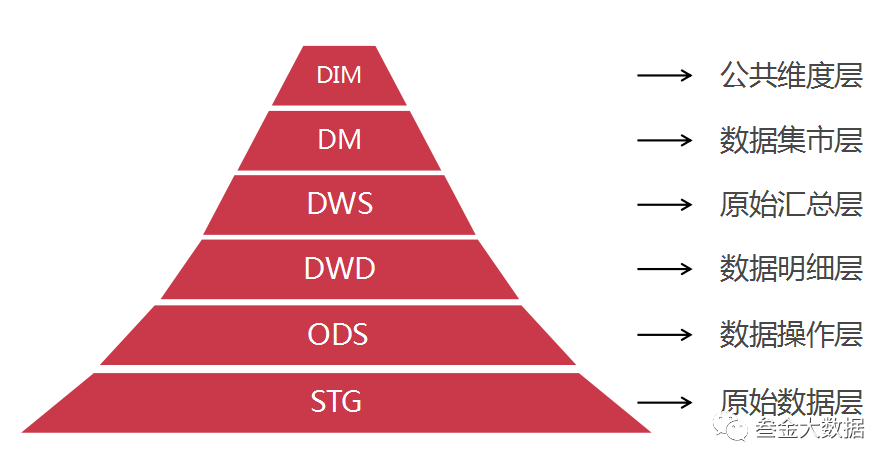
图中列出了常见的一些层次,这些层次的定义也不是完全规定好的, 大家参考的同时也可以根据自己工作中的实际需求适当的增删数据层次。
分层的好处:
清晰数据结构:每个数据分层都有对应的作用域
数据血缘追踪:对各层之间的数据表转换进行跟踪,建立血缘关系
减少重复开发:规范数据分层,开发通用的中间层数据
通过数据分层,我们明确了各个层次的作用域,减弱甚至屏蔽了数据和业务之间的强依赖。在数据在各个层次流转的过程当中,可以对数据进行一定规则的处理,满足各类业务的需求。
有了数据分层,即使有小伙伴在某一分层删库跑路了,我们通过上游或者下游的数据也可以快速的恢复。~~
关注关注我~

