




数据中存在的问题和处理方法:
数据预处理是数据挖掘中的重要一环,而且必不可少。要更有效地挖掘出知识,就必须为其提供干净,准确,简洁的数据;但是现实世界中数据常常是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘结果差强人意
1.原始数据存在的问题:
(1)数据的不一致:各系统间的数据存在较大的不一致性
(2)噪声数据:数据中存在着错误或异常(偏离期望值),收集数据的时候难以得到精确的数据,主要原因:
收集数据的设备可能出现故障;
数据输入时可能出现错误;
数据传输过程中可能出现错误;
存储介质有可能出现损坏等
(3)缺失值:由于实际系统设计时存在的缺陷以及使用过程中的一些人为因素,数据记录可能会出现数据值的丢失或不确定
引起缺失值的原因:
有些属性的内容有时没有(家庭收入,参与销售事务数据中的顾客信息);
有些数据当时被认为是不必要的;
由于误解或检测设备失灵导致相关数据没有记录下来;
与其它记录内容不一致而被删除;
忽略了历史数据或对数据的修改
2.数据质量的要求:
准确性:数据记录的信息是否存在异常或错误。
完整性:数据信息是否存在缺失。
一致性:指数据是否遵循了统一的规范,数据集合是否保持了统一的格式
时效性:某些数据是否能及时更新
可信性:用户信赖的数据的数量
可解释性:指数据自身是否易于人们理解
3.数据预处理的主要任务:
数据清理(清洗):去掉数据中的噪声,纠正不一致。
数据集成:将多个数据源合并成一致的数据存储,构成一个完整的数据集,如数据仓库。
数据归约(消减):通过聚集、删除冗余属性或聚类等方法来压缩数据。
数据变换(转换):将一种格式的数据转换为另一格式的数据(如规范化)
<1>数据清理就是对数据进行重新审查和校验的过程。其目的在于纠正存在的错误,并提供数据一致性。主要包括:缺失值的处理;噪声数据;不一致数据
缺失值的处理:空缺值要经过推断而补上
引起空缺值的原因:
设备异常
与其他已有数据不一致而被删除
因为误解而没有被输入的数据
在输入时,有些数据因为得不到重视而没有被输入
对数据的改变没有进行日志记载
a.缺失值的处理:
1)忽略元组:若一条记录中有属性值被遗漏了,则将该记录排除在数据挖掘之外
,但是,当某类属性的空缺值所占百分比很大时,直接忽略元组会使挖掘性能变得非常差
2)忽略属性列:若某个属性的缺失值太多,则在整个数据集中可以忽略该属性
3)人工填写空缺值:工作量大,可行性低
4)使用属性的中心度量值填充空缺值:
如果数据的分布是正常的,就可以使用均值来填充缺失值
如果数据的分布是倾斜的,可以使用中位数来填充缺失值
5)使用一个全局变量填充空缺值:
对一个所有属性的所有缺失值都使用一个固定的值来填补(如“Not sure”或∞)。
6)使用可能的特征值来替换空缺值(最常用):
生成一个预测模型,来预测每个丢失值
如可以利用回归、贝叶斯计算公式或判定树归纳确定,推断出该条记录特定属性最大可能的取值
b. 噪声的处理:
噪声(noise) :被测量的变量产生的随机错误或误差
产生噪声的原因:
数据收集工具的问题;
数据输入错误;
数据传输错误;
技术限制;
命名规则的不一致;
检测噪声数据:
1)基于统计的技术:使用距离度量值(如马氏距离)来实现
2)基于距离的技术:计算n维数据集中所有样本间的测量距离
c.不一致数据的处理
数据的不一致性,就是指各类数据的矛盾性、不相容性;
数据库系统都会有一些相应的措施来解决并保护数据库的一致性,可以使用数据库系统来保护数据的一致
<2>数据集成:把不同来源、格式、特点和性质的数据合理地集中并合并起来。这些数据源可以是关系型数据库、数据立方体或一般文件。
数据集成需要统一原始数据中的所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致等
a.集成过程中需要注意的问题:
1)集成的过程中涉及的实体识别问题:
整合不同数据源中的元数据;
进行实体识别:匹配来自不同数据源的现实世界的实体
数据库的 数据字典和数据仓库的 元数据,可帮助避免模式集成中的错误
2)冗余问题:
同一属性在不同的数据库或同一数据库的不同数据表中会有不同的字段名;
一个属性可以由另外的属性导出;
b.检测冗余的方法:
1)相关性分析
数值属性:采用相关系数和协方差进行相关性分析
标称属性:采用卡方检验进行相关性分析


<3>数据归约:
数据归约(data reduction):数据消减或约简,是在不影响最终挖掘结果的前提下,缩小所挖掘数据的规模;
数据归约技术可以用来得到数据集的归约表示,它小得多,但仍接近保持原数据的完整性;
对归约后的数据集进行挖掘可提高挖掘的效率,并产生相同(或几乎相同)的结果。
数据归约的标准:
用于数据归约的时间不应当超过或“抵消”在归约后的数据集上挖掘节省的时间。
归约得到的数据比原数据小得多,但可以产生相同或几乎相同的分析结果。
数量归约:直方图
直方图(Histogram)是一种常见的数据归约的形式。属性X的 直方图将X的
数据分布划分为不相交的子集或桶。通常情况下,子集或 桶表示给定属性的
一个连续区间。单值桶表示每个桶只代表单个属性值/频率对(单值桶对于存放那些高频率的离群点,非常有效)
划分桶和属性值的方法有两种:
①等宽:在等宽直方图中,每个桶的宽度区间是一致的。
②等频(或等深):在等频直方图中,每个桶的频率粗略地计为常数,即每个桶大致包含相同个数的邻近数据样本。
数量归约:数据立方体
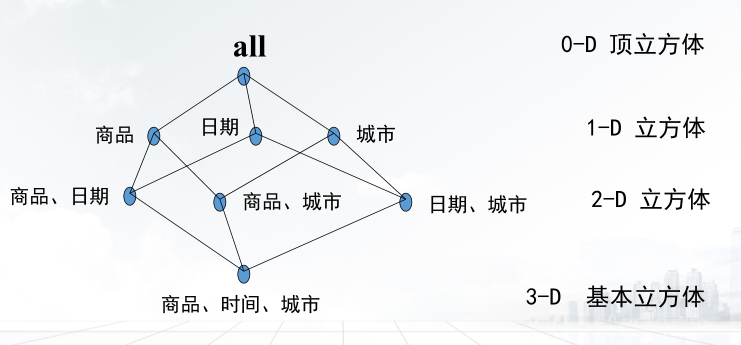
数据立方体是一类多维矩阵,可以使用户从多个角度探索和分析数据集,它的数据是已经处理过的,并且聚合成了立方形式。
数据立方体的基本概念:
①方体:不同层创建的数据立方体。
②基本方体:最低抽象层创建的立方体。
③顶方体:最高层抽象的立方体。
④方体的格:每一个数据立方体。
数据归约:属性子集选择:检测并删除不相关、弱相关或冗余的属性。
属性子集选择的基本启发式方法包括逐步向前选择、逐步向后删除、逐步向前选择和逐步
数据归约:抽样:允许用数据的较小随机样本(子集)表示大的数据集。
取样方法:
不放回简单随机取样 (Simple Random Sampling Without Replacement, SRSWOR)
放回简单随机取样(Simple Random Sampling With Replacement, SRSWR)
聚类取样(Clustered Sampling):首先将大数据集D划分为M个互不相交的聚类,然后再从M个类中的数据对象分别进行随机抽取,可最终获得聚类采样的数据子集
分层取样(Stra;fied Sampling):首先将大数据集D划分为互不相交的层,然后对每一层简单随机选样得到D的分层选样。
<4>数据变换:将数据转换成适合数据挖掘的形式
包括:
平滑:去掉数据中的噪声,将连续的数据离散化(分箱、回归、聚类)
聚集:对数据进行汇总和聚集,如avg(), count(), sum(), min(), max(),…
数据变换:将数据转换成适合数据挖掘的形式
数据泛化:使用概念分层,用更抽象(更高层次)的概念来取代低层次或数据层的数据对象
规范化:把属性数据按比例缩放,使之落入一个特定的小区间,以消除数值型属性因大小不一而造成的挖掘结果的偏差。常用的方法:小数定标规范化;最小-最大规范化;零-均值规范化(z-score规范化)。
属性构造:通过已知的属性构建出新的属性,然后放入属性集中,有助于挖掘过程。
离散化:数值属性的原始值用区间标签或概念标签替换。
连续变量的离散化,就是将具体性的问题抽象为概括性的问题,即是将它取值的连续区间划分为小的区间,再将每个小区间重新定义为一个唯一的取值。
数据离散化的基本方法主要有分箱法和直方图分析法。
对连续变量进行离散化处理,一般经过以下步骤:
①对此变量进行排序。
②选择某个点作为候选断点,根据给定的要求,判断此断点是否满足要求。
③若候选断点满足离散化的要求,则对数据集进行分裂或合并,再选择下一个候选断点。
④重复步骤②和③,如果满足停止准则,则不再进行离散化过程,从而得到最终的离散结果。
小数定标规范化:

最小—最大规范化:
假定minA和maxA分别为属性A的最小和最大值,则将A的值映射到区间[a,b]中的v’

其中 :𝑣↓𝑖 表示对象i的原属性值, 𝑣↓𝑖 ′ 表示规范化的属性值, a为规范化后的最小值,b为规范化后的最大值。
z-score规范化(零均值规范化):将属性A的值根据其平均值和标准差进行规范化;常用于属性最大值与最小值未知,或使用最小最大规范化方法会出现异常数据的情况。

其中 𝑣↓𝑖 表示对象 的原属性值, 𝑣↓𝑖 ′ 表示规范化的属性值, 𝐴 表示属性A的平均值,σA表示属性A的标准差 。
规范化将原来的数据改变很多,特别是上述的后两种方法。有必要保留规范化参数(如平均值和标准差,如果使用z-score规范化)以便将来的数据可以用一致的方式规范化
数据离散化—分箱
分箱的步骤:
首先排序数据,并将它们分到等深(等宽)的箱中;然后可以按箱的平均值、或中值或者边界值等进行平滑。
按箱的平均值平滑:箱中每一个值被箱中的平均值替换
按箱的中值平滑:箱中的每一个值被箱中的中值替换
按箱的边界平滑:箱中的最大和最小值被视为箱边界,箱中的每一个值被最近的边界值替换
① 等深分箱 :按记录数进行分箱 , 每箱具有相同的记录数 , 每箱的记录数称为箱的权重 , 也称箱子的深度
②等宽分箱 (binning):在整个属性值的区间上平均分布,即每个箱的区间范围设定为一个常量,称为箱子的宽度。


数据离散化 — 直方图分析法 :
直方图也可以用于数据离散化 。它能够递归的用于每一部分 ,可以自动产生多级概念分层 , 直到满足用户需求的层次水平后结束
