





1. 基本数据结构
双向链表的应用十分广泛,InnoDB中的LRU list,free list,flush list等成员都是通过双向链表来组织起来的,InnoDB为了统一代码实现,通过类模版来实现了一套双向链表的数据结构和算法。这部分代码主要在如下文件中:
mysql-source/storage/innobase/include/ut0lst.h
mysql-source/storage/innobase/include/ut0dbg.h
双向链表的类模版定义如下:
template <typename Type>
struct ut_list_node {
Type* prev; /*!< pointer to the previous
node, NULL if start of list */
Type* next; /*!< pointer to next node,
NULL if end of list */
void reverse()
{
Type* tmp = prev;
prev = next;
next = tmp;
}
};
可以看到它包含了prev,next两个指针,分别代表了前驱节点和后继节点。在类模版的实现中,并不包含节点本身的数据或者指向自身数据的指针。这说明用户在使用此类模版来实现双向链表时,必须在每一个数据节点中定义一个自身类型的模版类对象。比如free list中的数据节点是buf_page_t类型,则在buf_page_t的定义中,可以看到如下成员:
UT_LIST_NODE_T(buf_page_t) list;
它就像一个对自身结构的延伸,负责串联前后的数据节点。如下图所示:
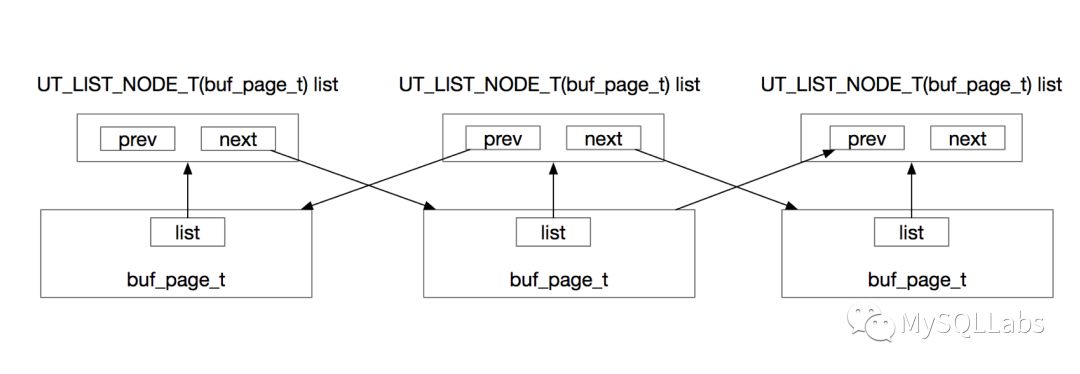
所以无论是什么样的数据类型,你都可以通过定义一个这样的成员,来实现双向链表。
只通过ut_list_node已经可以构建一个双向链表了,但是它缺乏了一些链表相关的信息,比如链表当前的头尾节点,或者它们的指针,还有链表中的元素个数等信息,所以InnoDB又定义了另外一种类模版,如下:
template <typename Type, typename NodePtr>
struct ut_list_base {
typedef Type elem_type;
typedef NodePtr node_ptr;
typedef ut_list_node<Type> node_type;
ulint count; /*!< count of nodes in list */
elem_type* start; /*!< pointer to list start,
NULL if empty */
elem_type* end; /*!< pointer to list end,
NULL if empty */
node_ptr node; /*!< Pointer to member field
that is used as a link node */
#ifdef UNIV_DEBUG
ulint init; /*!< UT_LIST_INITIALISED if
the list was initialised with
UT_LIST_INIT() */
#endif * UNIV_DEBUG */
void reverse()
{
Type* tmp = start;
start = end;
end = tmp;
}
};
并且使用宏UT_LIST_BASE_NODE_T来表示双向链表的根节点
#define UT_LIST_BASE_NODE_T(t) ut_list_base<t, ut_list_node<t> t::*>
用来初始化一个双向链表对象,比如buf_pool_t中的free list,定义如下:
UT_LIST_BASE_NODE_T(buf_page_t) free;
/*!< base node of the free
block list */
亦或者LRU list,flush list等。
UT_LIST_BASE_NODE_T(buf_page_t) LRU;
/*!< base node of the LRU list */
UT_LIST_BASE_NODE_T(buf_page_t) flush_list;
/*!< base node of the modified block
list */
2. 双向链表的相关操作
2.1 双向链表的初始化
通过宏定义UT_LIST_INIT来实现双向链表的初始化,比如缓冲中的各种链表
UT_LIST_INIT(buf_pool->LRU, &buf_page_t::LRU);
UT_LIST_INIT(buf_pool->free, &buf_page_t::list);
UT_LIST_INIT(buf_pool->withdraw, &buf_page_t::list);
buf_pool->withdraw_target = 0;
UT_LIST_INIT(buf_pool->flush_list, &buf_page_t::list);
UT_LIST_INIT(buf_pool->unzip_LRU, &buf_block_t::unzip_LRU);
2.2 双向链表的插入 它提供了多种插入方式,最常用的是尾部插入
UT_LIST_ADD_LAST(buf_pool->free, &block->page);
也可以进行头部插入
UT_LIST_ADD_FIRST(buf_pool->flush_list, &block->page);
还可以在中间的某个位置进行插入
if (prev_b == NULL) {
UT_LIST_ADD_FIRST(buf_pool->flush_list, &block->page);
} else {
UT_LIST_INSERT_AFTER(buf_pool->flush_list, prev_b, &block->page);
}
2.3 双向链表的移除
比如从flush_list中移除已经刷盘的脏页
UT_LIST_REMOVE(buf_pool->flush_list, bpage);
2.4 双向链表的销毁
并不直接提供销毁的方法,而是需要用户将某个节点从链表移除后,自行销毁和内存释放。当然,如果双向链表中所有节点的内存是连续的,可以统一释放,无需单个移除,比如销毁一个缓冲池中一大块的内存。
buf_pool->allocator.deallocate_large(
chunk->mem, &chunk->mem_pfx);
还提供了其他的一些操作,如下:
3. 拿来主义
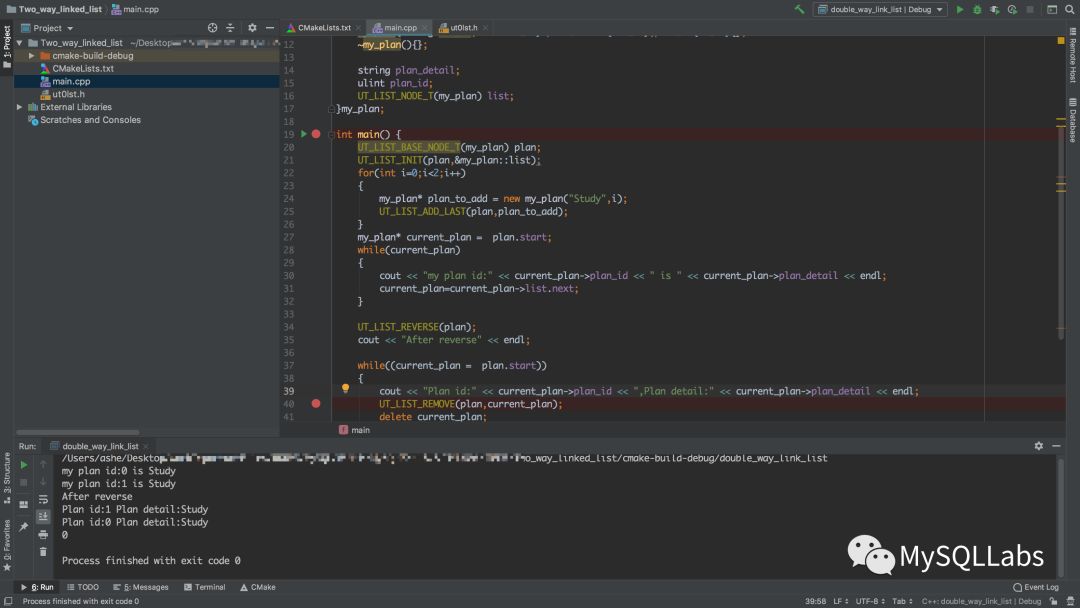
把InnoDB的双向链表的实现拿到自己的项目中来使用,是一件非常简单的事情,将头文件引入后稍加修改即可,当然在今天,除了一些数据库相关的项目,还有多少人会亲自去实现链表相关的逻辑呢。
本文并没有介绍InnoDB中双向链表过多的实现细节,感兴趣的话可以阅读源码,深入研究。
本文分享自微信公众号 - MySQLLabs,如有侵权,请联系 service001@enmotech.com 删除。
