




scrapy是为持续运行设计的专业爬虫框架,scrapy的很多操作都用命令行实现
1.scrapy -h
2.scrapy命令行格式:>scrapy <command> [options][args]
3.scrapy常用命令:
startproject---创建一个新工程---scrapy startproject <name> [dir]
genspider---创建一个爬虫---scrapy genspider [options] <name> <domains>
settings---获得爬虫配置---scrapy settings [options]
crawl---运行一个爬虫---scrapy crawl <spider>
list---列出工程中所有爬虫---scrapy list
shell---启动url调试命令行---scrapy shell [url]
在scrapy框架下,一个工程是一个最大的单元,一个工程相当于一个大的scrapy框架,在scrapy框架中可以有多个爬虫,每个爬虫相当于框架中的一个spider模块
scrapy为什么使用命令行而不是图形界面?
因为scrapy不是给用户操作使用的,它更多地是后台的一个爬虫框架,命令行更容易自动化,适合脚本控制,对爬虫的控制和访问还有数据的操作更加灵活,并且,在本质上scrapy是给程序员使用的,而不是给最终用户使用的,它的功能更重要
scrapy爬虫的使用:
步骤:
1.建立一个scrapy工程,选一个目录,在目录中执行建立爬虫工程的命令
命令:scrapy startproject python123demo
结果:生成工程目录:


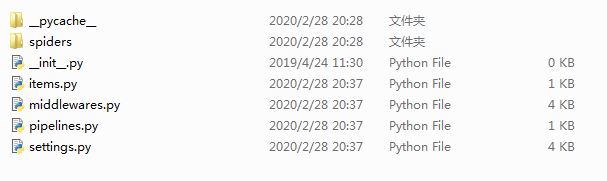

python123demo/---外层目录
(1)scrapy.cfg--部署scrapy爬虫的配置文件,将爬虫放到特定服务器,并为服务器配置好相关的接口
(2)python123demo/---scrapy框架对应的所有文件所在的目录,其中彪包含很多Python文件
(2).1 __init__.py:初始化脚本,用户不需要编写
(2).2 items.py:对于items类的代码模块(继承scrapy提供的类),一般不需要用户编写
(2).3 middlewares.py:Pipelines代码模块
(2).4 settings.py:scrapy爬虫的配置文件(若要优化爬虫,则需要修改settings里对应的配置项)
(2).5 spiders/:存放Python123demo这个工程中所建立的爬虫,它内部的文件有:
<1>__init__.py:初始文件,无需修改
<2>__pycache__/:缓存目录,无需修改
2.在工程中创建一个scrapy爬虫(注意路径)
命令:scrapy genspider demo python123.io
结果:在外层目录python123demo里生成一个demo.py文件

文件中allowed_domains:最开始用户提交给命令行的域名,所以这个域名在爬取网站时只能爬取这个域名以下的相关连接
start_urls:以列表形式包含的一个或多个url,就是scrapy框架所要爬取的初始页面
def parse()函数:解析页面的函数,parse():用于处理响应,解析从网络中爬取的内容并且形成字典类型,并且还能从爬取的内容中发现新的url爬取请求
3.配置产生的spider爬虫,修改demo.py,使之满足需求


爬取方法的两个参数:self:面向对象类所属关系的标记,response:从网络中返回内容所对应的对象
4.运行爬虫,获取页面
命令:scrapy crawl demo

过程中涉及的三个类:
Requests:向网络上提交请求的内容
Response:从网络中爬取的内容的封装的类
Items类:由spider产生的信息封装的类
Requests类表示一个Request对象,Request对象表示一个HTTP请求,Requests类由spider生产,最终由DOWNLOADER执行
Response对象表示一个HTTP响应,封装在Response类里,由DOWNLOADER生产,由spider处理
Item对象表示一个从HTML页面中提取的信息内容,由spider生成,由Item Pipelines处理,Item类似字典类型,可以按照字典类型操作
Requests类的六个常用属性:
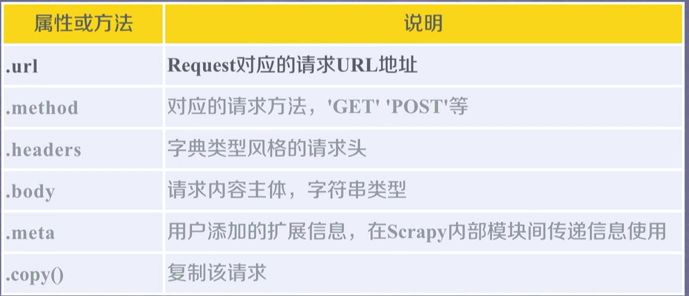
Response类的六个常用属性:

scrapy爬虫支持多种HTML信息提取方法:BeautifulSoup、lxml、re、XPath Selector、CSS Selector等
