




大家好,我是砖家小胖,好久没有更新文章了,之前我们搭建了HBase集群,今天我们来梳理一下HBase的相关内容。
1.概念
HBase是一个分布式具有高可靠性、可伸缩扩展且面向列的高性能开源NoSQL数据库(底层由K-V组成)。谷歌的三篇论文分别为:GFS(HDFS)、MapReduce、BigTable,其中BigTable就是HBase数据库的前身。HBase的最大特点是数据的列字段可以动态增加,并且弥补了HDFS无法随机读写的缺陷,同时可以达到在几十亿条数据中达到秒级别的查询。
2.数据存储结构(Conceptual View)
首先看下数据存储在MySql中表的样子:

MySql适合存储结构化数据,表非常规整,在存储数据前,我们需要在建表时设计好每列的字段并定义好其数据类型,然后插入数据,没有数据则值为Null或默认值。
接下看下数据存储在HBase中表的样子:
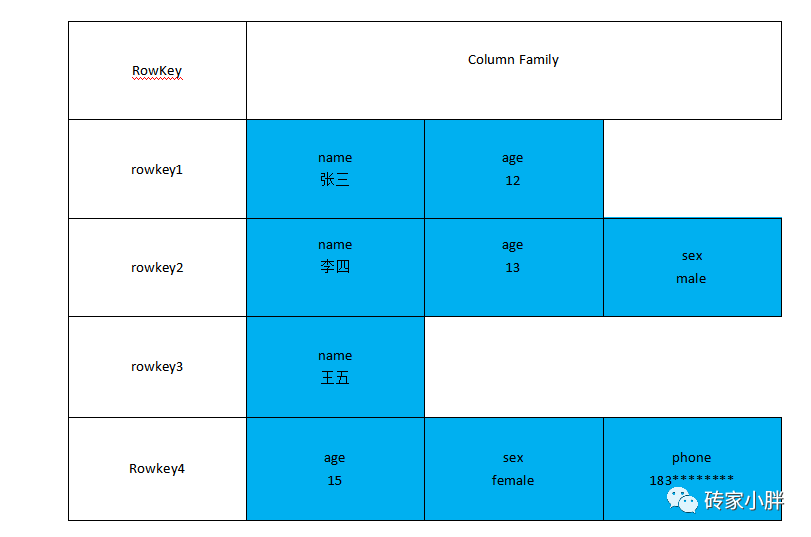
HBase适合存储半结构化或非结构化数据,表由“稀疏矩阵”组成,我们在建表之前,只需要设计好列族即可,列字段可作为数据进行动态插入,没有的数据并不占用存储空间。
可以看到列字段是灵活动态的,例如RowKey1行包含name和age两列,RowKey4行包含了age、sex、phone三个列字段,列字段数量不同且列字段限定符也并不一样。
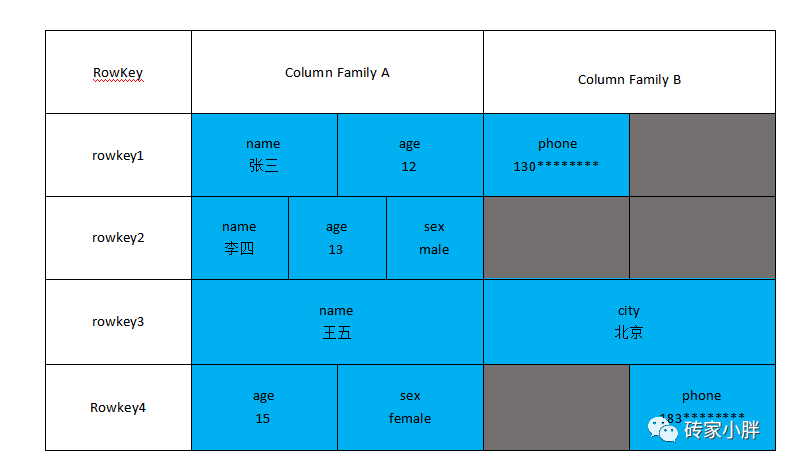
3.实际存储结构(Physical View)

上图以张三学生为例,展示了张三数据存储在HBase数据库表中实际的样子。
4.HBase表中的各组件
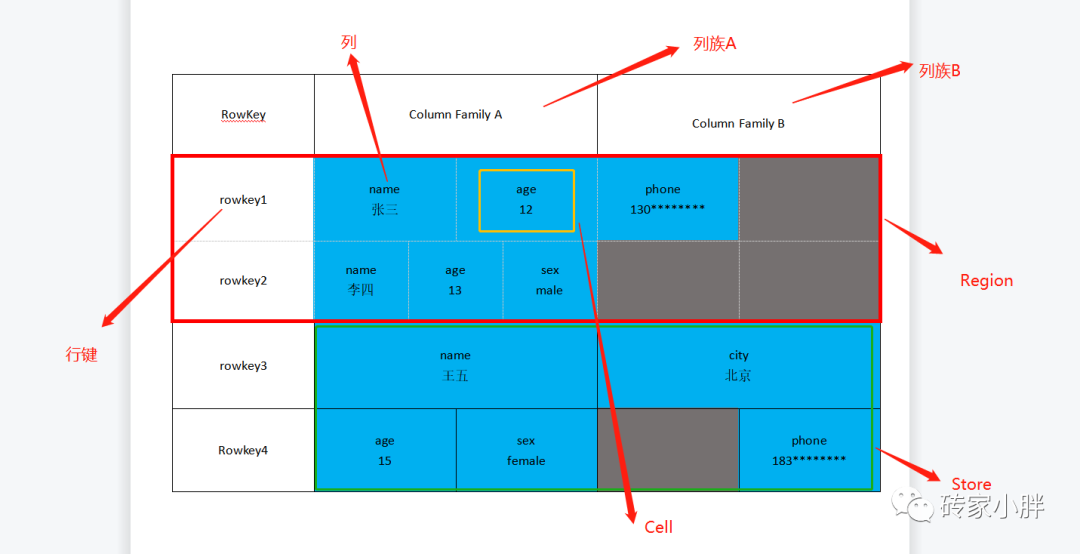
NameSpace: 命名空间,默认为default,系统表为hbase,相当于MySql里的database,如不指定命名空间,默认为default下。
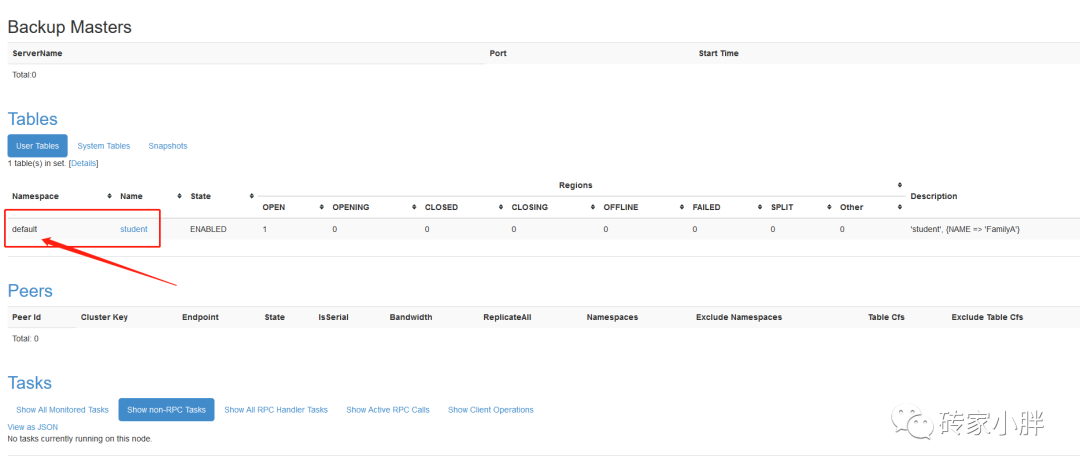
Row: 行,hbase表中,每行数据由一个RowKey和多个Column组成。
Column: 列,每个列由ColumnFamily和Column Qualifier组成,建表时仅需指定列族,列的限定符可动态插入。
RowKey: 行的键值,用于检索扫描数据,排列顺序为字典排序。
ColumnFamily:列族,建表时需要指定列族,hbase表可以包含多个列族,一个列族由多个列组成,列字段的限定符以数据的方式动态插入。类似于MySql中宽表拆分,由于列字段过多导致扫描效率降低,故引入列族,扫描不同的数据从不同的列族文件夹中扫描,从而提高扫描效率。
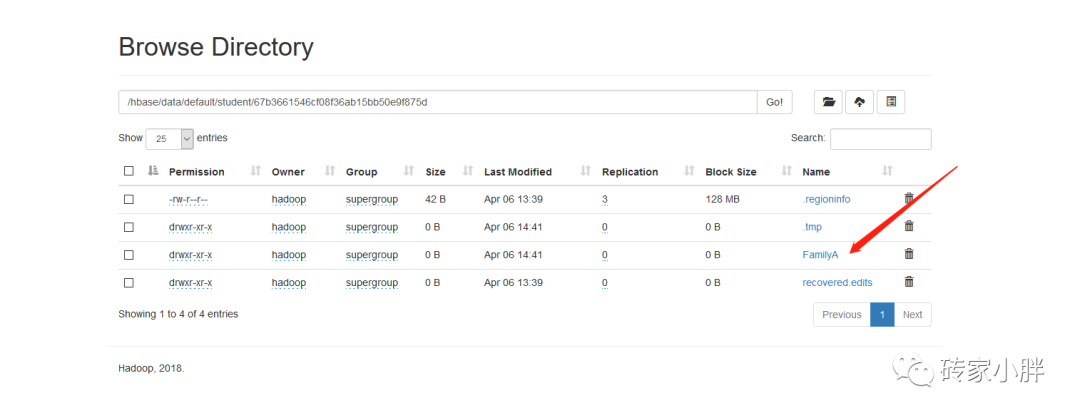
Region:表数据横向切片,hbase表可切分为多个Region,每个Region切片包含一部分行数据,类似于MySql中高表拆分,当数据量过大时,巨量的Row数据会被切成不同的Region存储在不同的文件夹中,以提高扫描效率。
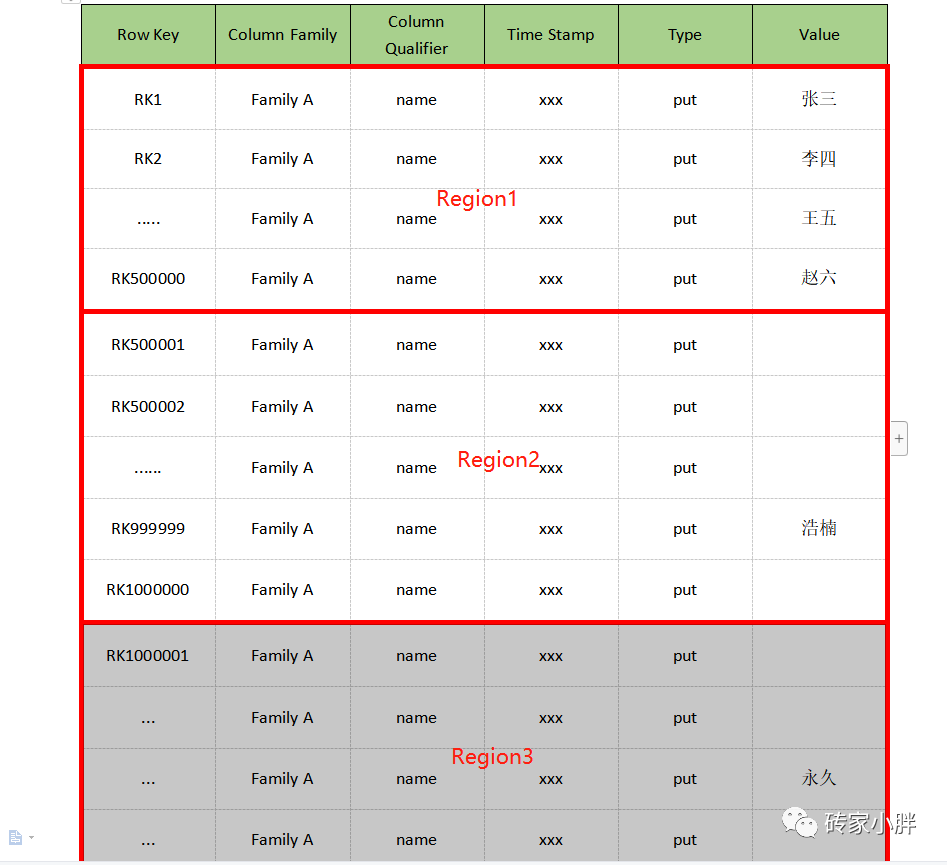
以上图为例,hbase表被分为三个Region切片,保存在不同的文件目录中,如果我们需要获取浩楠的相关数据,仅需要扫描Region切片2的表(文件)数据即可,即从第50万行---100万行RowKey之间扫描。
TimeStamp:插入数据的时间戳,用于数据版本。hbase表插入一行数据时,系统会自带时间戳一起插入。
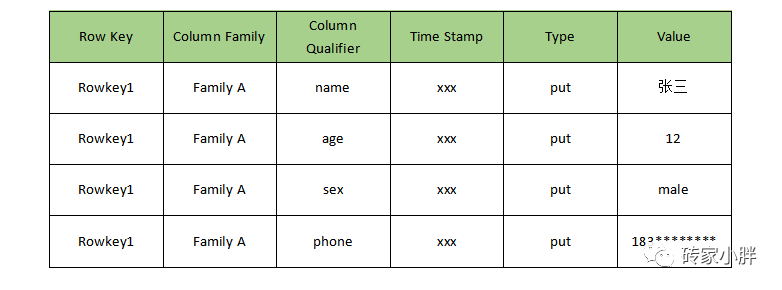
Cell:细胞值,一个单元格,以字节形式存储存储,行键+列族+列键+时间戳可以确定唯一一个Cell值。
比如: RowKey1+FamilyA+name+TimeStamp就可以确认该Cell值为张三
hbase在建表时可以控制保存的Cell版本数,保存为3个版本,就代表可以获取到Cell最近3次插入的值。
alter 'student',{NAME=>FamilyA,VERSIONS=>3}
5.HBase中的增删改查
在HBase当中,一切数据以时间戳为基准,前面我们说过,当每行数据被插入时,系统会附带一个TimeStamp时间戳。而HBase数据库中的增删该查,正是基于时间戳所完成的,即系统永远返回最大时间戳的数据(最新时间数据),所以在操作HBase数据库时,一定要保证操作机系统的时间和HBase集群中各机器的时间保持一致。
增:
输入RowKey+ColumnFamily+ColumnQualifier+Value

改:
HBase中没有改数据的操作,改数据的操作本质上是新插入一条数据,当新插入的数据RowKey相同,列族相同,列限定符相同、类型为Put,且TimeStamp时间戳大于原数据时间戳,此时系统返回最大时间戳的Cell数据,则代表数据修改成功。(系统会在适当时机删除旧时间戳的RowKey数据) 下图将RowKey1数据的name从张三修改为王五。
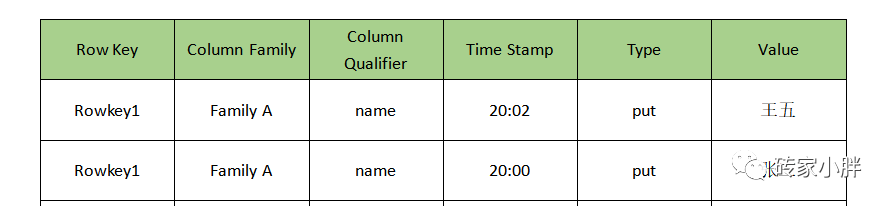
查:
通过RowKey+ColumnFamily+ColumnQualifier获取最大时间戳Cell值
删:
HBase中没有删数据的操作,删数据的操作本质上是新插入一条类型为delete的空值数据,新插入的空值数据RowKey相同,列族相同,列限定符相同、类型为Delete,且TimeStamp时间戳大于原数据时间戳,则代表数据删除成功。此时查数据时,系统获得到最新时间戳的Cell数据类型为Delete时,则返回空数据(系统会在适当时机删除旧时间戳的RowKey数据) 下图将RowKey1的name为王五的数据删除。
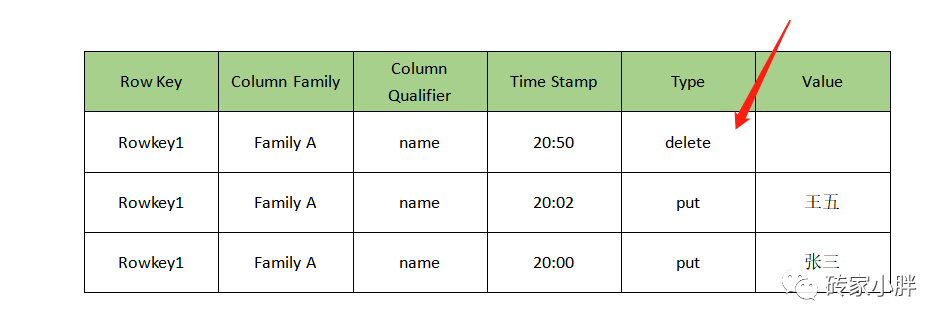
通过以上对HBase中增删改查的原理进行分析,我们可以发现,在HBase的DML操作当中,HBase本质仅支持增查功能,通过更改插入数据的类型实现了删操作,通过时间戳的机制实现了改操作,这些优化也为HBase的运行性能提供了极大的帮助。
6.HBase的架构及各组件
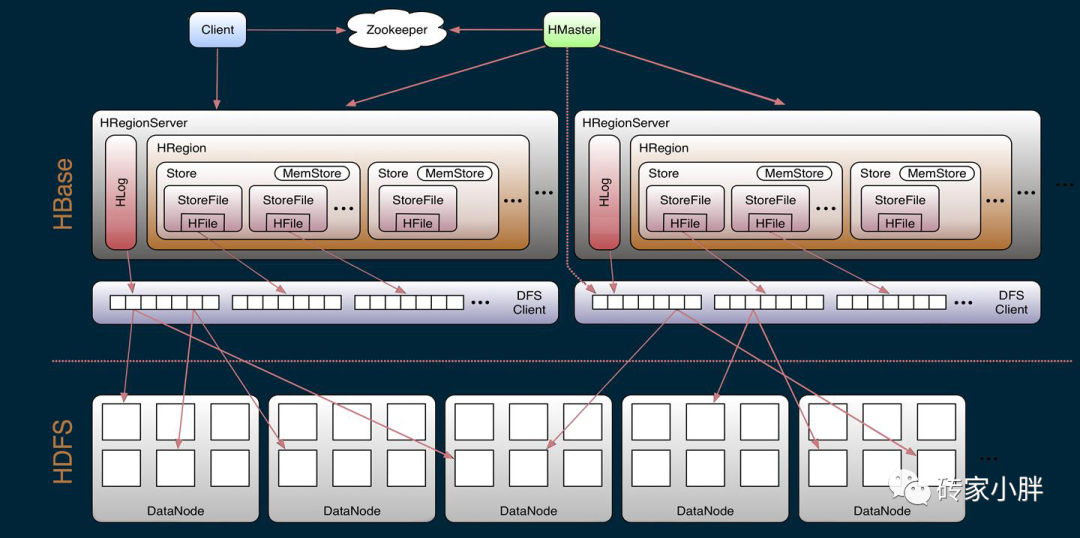
HMaster: RegionServer节点机器的老大(哪台机器上群起哪台就是HMaster),管理着HBase集群Region表的元数据信息,提供DDL操作,分配Region存放在哪台RegionServer上,并提供负载均衡,一旦RegionServer节点挂掉,重新分配Region到新的ReginServer上,这东西类似于ZooKeeper里的Leader节点或是HDFS的NameNode节点。
RegionServer: 实际管理Region的节点服务器进程,提供DML操作,负责Region的分裂与合并操作,表数据实际存储的节点机器,当Master节点挂掉后,并不影响客户端对实际表数据的读取与访问。
ZooKeeper :
搭建HBase集群,需要先搭建ZooKeeper集群,在HBase中,主要依赖ZooKeeper两个功能,一个是智能感知RegionServer机器上下线,将上下线节点机器汇报给Master,另一个就是查询HBase系统表META表,获得实际META表的存放的机器位置。
HRegion:表数据横向切片,hbase表可切分为多个Region,每个Region切片包含一部分行数据,相当于一个子表。
Store: 一个Region包含一个或多个Store,每个Store中存储着列族中的数据,即N列族对应N个Store。
MemStore: Store内存缓冲区,默认达到128MB时,将内存中的数据Flush到磁盘中。
StoreFile: MemStore刷新到磁盘的文件。
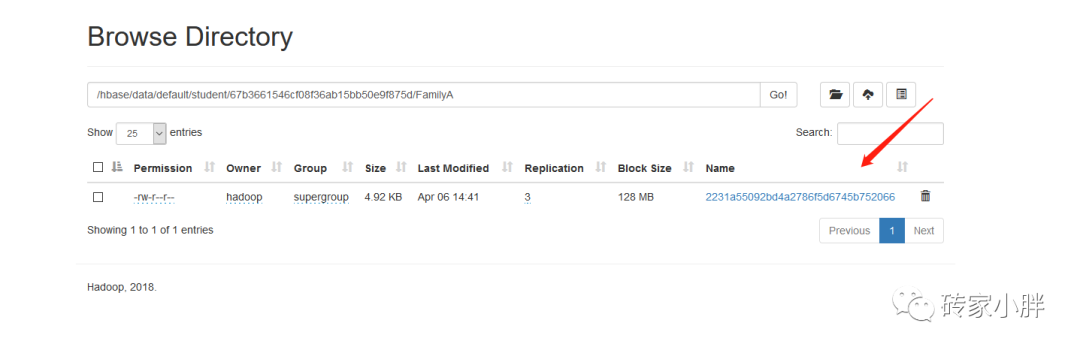
HFile: 一种Key-Value格式,StoreFile文件中以HFile格式存储。
HLog:WAL预写入日志,每个RegionServer维护一个HLog,写入操作顺序,用于防止MemStore数据丢失,类似于HDFS的IDS文件。
7.HBase写流程和读流程
写流程:
Client put student:FamilyA rowkey50000 name zhangsan
⬇
请求ZooKeeper,获取META表所在机器为A机器
⬇
在A机器的META表中查出student:FamilyA rowkey50000所属的Region表的位置存储在机器B
⬇
向B机器的WAL写入操作日志
⬇
RegionServer将数据写入到B机器的MemStore中
⬇
B机器RegionServer回传ack指令到Client
⬇
待B机器MemStore达到刷写条件时,将数据Flush到磁盘生成StoreFile文件
读流程:
Client get student:FamilyA rowkey50000 name
⬇
请求ZooKeeper,获取META表所在机器为A机器
⬇
在A机器的META表中查出student:FamilyA rowkey50000所属的Region表的位置存储在机器B
⬇
向B机器的WAL写入操作日志
⬇
B机器RegionServer读取MemStrore数据
⬇
B机器RegionServer读取磁盘StoreFile文件数据,并将数据缓存到Block Cache中
⬇
B机器将MemStore数据和StoreFile数据进行时间戳对比
⬇
B机器RegionServer回传时间戳最新的数据到Client
8.MemStore刷写时机
前面我们讲了,MemStore会将内存中的数据Flush到磁盘上,下面我们总结下何时会触发Flush条件。



当堆内存达到38%时,则开始触发RegionServer进程刷写数据到硬盘,此时会将RegionServer进程下的所有Region里的Store数据,即每个Store里的MemStore都进行刷写到硬盘中,当堆内存达到40%时,会触发阻塞刷写,同时阻塞HBase的读和写操作。当RegionServer最后一条数据写入后,默认一小时无操作,则触发RegionServer进程刷写。

当单个Region里的Store数据大小达到128MB时,触发单个Region的刷写。
MemStore刷新内存数据到磁盘时,过期版本的Cell值会被彻底删除,但不会删除delete类型的标记符。
9.StoreFile文件的合并(MajorCompact)
由于HBase底层是基于Hadoop的HDFS,当每个MemStore从内存刷写数据到磁盘时,可能会产生大量的小文件。而大量小文件不利于HDFS的性能,于是HBase会在适当时机,将小的StoreFile文件合并成大的StoreFile文件。


一般默认值为7天,且StoreFile文件大于等于3个时,将会触发合并文件操作,且该合并操作会占用大量IO资源,因为HBase进行随机读写操作本质上是重写该文件。该属性设置为0时则关闭系统自动合并线程,我们可以在集群空闲时间里进行手动合并。
触发合并StoreFile操作时,过期版本的Cell值会被彻底删除,包括删除delete类型的标记符。
10.Region的分裂
Region太大同样会影响HBase的读写性能,当一个Region下的任意一个Store的所有StoreFile总文件大小超过一定数值时,就会触发该Region的分裂,及一个Region分裂为两个Region。

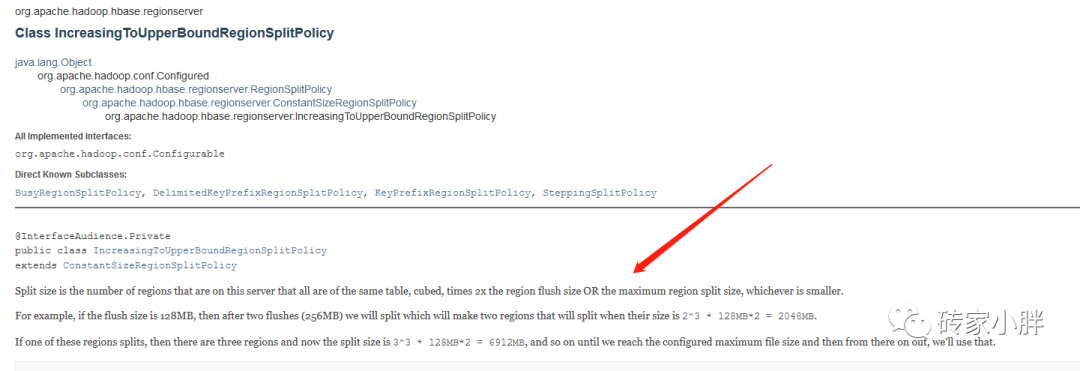
触发条件:在Region个数^2*hbase.hregion.memstore.flush.size和hbase.hregion.max.filesize之间选择最小的那个。即第一次Region分割大小为1^2*128MB=128MB,第二次为512MB.....最后每达到10G大小分割一次。
11.Region预分区
前面说了Region在适当条件下会进行分裂,第一次分裂总大小为128MB,分裂后的RegionA和RegionB可能由于RowKey设计问题,导致RegionA表数据量无限增大且无限分裂,诞生巨量的小型StoreFile文件。这时将会产生数据倾斜的问题。于是我们引入了预分区概念。
预分区:即通过目前的业务场景,提前规划好Region的总数量(一般每台机器放置2-3个Region最佳),预计好将来插入的数据总量,时刻保持每个Region任意Store下的总StoreFile文件大小不超过10G,及避免HBase触发Region自动分裂机制。
12.数据热点与RowKey设计原则
唯一性原则:RowKey唯一存在,不可重复。
长度原则:RowKey值越短,查询和扫描效率越高。
散列性原则:将数据分散的插入到不同的Region中,从而避免某个RegionServer出现数据热点问题。
13.散列性解决方案:
v1.将RowKey原始数据进行hash计算,及hash值作为RowKey。
v2.字符反转:如RowKey 001_1994 反转为4991_100作为RowKey
。
v3.加字符串前缀:如在RowKey前面加入UUID值,或有规律的字符串。
再见~~~
