




大家好,我是砖家小胖,上篇文章我们安装了Zookeeper3.6.1,并进行了一些Shell命令测试,今天我们来详细介绍下Zookeeper(下文简称ZK)。
1.概念
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等(摘自百度百科)。
接下来是官网介绍:

2.用途
概念上讲的这玩意是个分布式应用程序协调服务,其实这东西最核心的功能就是:以观察者模式提供监听机制+节点快速同步数据的小型数据共享和数据存储的文件系统。接下来的一些应用都是围绕这个核心功能实现的。
v1.感知服务器集群里机器的上下线(最常用)
原因:在服务器集群中,经常会由于硬件故障,软件故障、网络问题及其他未知问题导致节点服务器宕机挂掉。这时故障机器退出集群节点,新机器加入集群节点。其他正常运行的节点机器需要感知这些变化。
举例:比如在一个商城后台服务,A、B、C三台机器分别负责支付系统、订单系统、物流监控系统,不幸A机器宕机坏掉了,于是上线了搭载支付系统的D机器,此时负载均衡需将所有支付请求从A机器转移到D机器,不再向A机器请求支付服务,其余的B、C机器的业务交互也由A转到了D机器。
实现:各个服务器向ZK集群写入写入包含自己IP地址、Host等信息的临时节点,所有感知机器监听该临时节点的上级目录,如有子节点值发生变化,则通知所有感知机器:有节点机器掉线或上线。
v2.定制打造自己的负载均衡系统
小胖在2016年的时候,有个《智能服装检索》的项目,当时每台节点服务器的显卡只支持同时50个用户进行GPU算法检索服务,故主服务器可以通过访问ZK集群感知目前每台节点机器正在运行服务的个数,向资源占用率低的节点机器分配任务。
v3.队列管理
可以使用带序号的节点,进行排队,当个数足够时,提供相关服务。
v4.统一命名服务
打造一个属于自己的DNS服务,提供统一的入口节点,将不同的IP和域名映射信息保存起来。
v5.配置管理
多节点服务器配置统一管理,通过ZK一致性同步数据,既安全可靠又快速。
v6.分布式锁
同一时间一个服务只能被一个机器的一个线程执行,当这台服务出问题的时候锁释放,立刻换到另外的服务。
3.角色
Leader: ZK集群管理节点,在集群中通过选举算法产生,只存在一个,负责接收和协调所有写请求,并把写入的信息同步到Follower和Observer。一旦Leader节点宕机挂掉,将重新从其他Follower节点中选举出新的Leader节点。
Follower:ZK集群跟随节点,处理读请求,但接到写请求时,将把请求转到Leader节点。备用Leader节点,参与Leader选举,防止单点故障。
Observer:不参与Leader选举,处理读请求,但接到写请求时,将把请求转到Leader节点。
Client:客户端,可向ZK集群发送读请求、写请求。
4.架构特性
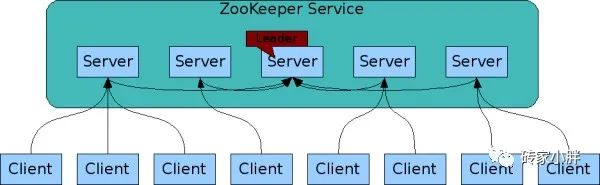
v1. 所有节点数据一致,无论是Leader还是Follower都保存一份相同的数据副本,无论客户端连接到哪个节点请求服务,获得的数据都是一致的。这个和HDFS不一样,HDFS是DataNode来保存副本数据,而NameNode保存元数据。
v2.ZK集群有N/2+1个节点存活,N为总节点,整个集群才能提供服务,这个有点类似于QJM(Quorum journal manager)集群。如果有 2N+1台ZK节点机器,那么根据大多数的原则,最多可以容忍有 N 台 ZK 节点挂掉。
v3.数据写入和更新为大多数原则,大多数指N/2+1,N为ZK节点数,假设有3台ZK节点,则有2台节点成功返回,就代表写入成功。
v4.数据的写入为原子性,一次写入要么成功,要么失败。
v5.写入更新顺序性,同一客户端写入请求按顺序执行。
v6.写入操作时,同步节点数据的过程中为阻塞状态,此状态无法服务客户端新的请求,当N/2+1台节点机器数据同步成功后,恢复对外服务能力。
v7.实时性,在特定情况下,客户端能读到最新数据(顺序一致性)
以下摘自Zookeeper官网:
Guarantees
ZooKeeper is very fast and very simple. Since its goal, though, is to be a basis for the construction of more complicated services, such as synchronization, it provides a set of guarantees. These are:
Sequential Consistency - Updates from a client will be applied in the order that they were sent.
Atomicity - Updates either succeed or fail. No partial results.
Single System Image - A client will see the same view of the service regardless of the server that it connects to. i.e., a client will never see an older view of the system even if the client fails over to a different server with the same session.
Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.
5.数据模型
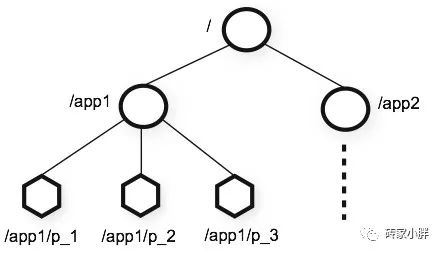
Zookeeper的数据模型结构和Linux的文件系统差不太多,都是树形结构,以/为根节点,下面每个树杈被成为Znode,例如/app1,每个Znode为路径唯一标识且Znode节点存储的数据非常小,仅为千字节左右。
6.节点类型
持久化节点(PERSISTENT):创建永久节点,客户端与ZK集群断开连接后,创建的节点不删除。
短暂化节点(EPHEMERAL):创建临时节点,客户端与ZK集群断开连接后,创建的节点删除。
持久化顺序编号节点(PERSISTENT_SEQUENTIAL):创建永久序号节点,每次创建新的节点,名字自动增加序号,客户端与ZK集群断开连接后,创建的节点不删除。
短暂化顺序编号节点(EPHEMERAL_SEQUENTIAL):创建临时序号节点,每次创建新的节点,名字自动增加序号,客户端与ZK集群断开连接后,创建的节点删除。
7.监听机制与监听原理
ZK集群提供监听Znode节点功能,可以监听其节点值是否发生变化或节点是否发生了变化,我们可以在监听的回调函数里开发定制自己的功能,这种监听机制实际上是服务器端反向推送通知的一种方式。
监听原理:
客户端创建----->开启通信线程和监听阻塞线程----->通信线程发送数据,在ZK集群注册监听器----->ZKServer端将监听节点/test、监听者的IP地址、端口号等保存到监听列表中----->节点发生变化时----->向监听阻塞线程发送节点变化数据---->从监听列表移除该监听器
8.写和读数据
写:写只能有Leader节点协调完成,一旦客户端连接Follower节点发起写请求,则该Follower将该写请求转发给Leader节点。写的同步过程中,当N/2+1节点同步成功,则代表写入成功。
读:任何节点都可以服务于读请求,客户端读取该节点副本数据。
9.选举机制
ZK集群节点机器需要一个一个启动,其节点初始启动时,会根据算法选举出一个Leader成为老大,当机器初始启动时,每个节点机器都会先投票给自己,一旦发现投票无法选取Leader时,第二次投票将把票投给当前运行机器中ServerId较大的值,也就是我们上一篇配置ZK中myID配置文件中的编号。
ZK集群能对外服务最少配置的机器为3台,也就是说,当ServerId分别为1、2、3时,初始投票的Leader为3号机器,但当Leader宕机时,二次或多次投票时,机制则为另一种机制。(扩展部分需自行研究ZAP协议)
10.ZK数据一致性
v1. 弱一致性
当数据更新后,后续对该数据读取可能是更新后的值,也可能是更新前旧值。
v2. 强一致性
当数据更新后,在任何时刻获取到的值都是最新更新的值。(参考关系型数据库)
v3. 最终一致性
某一时刻获取到的值可能为旧值,但最终所有节点数据会同步到一致状态。
v4. 顺序一致性
任何一次读都能读到某个节点数据的最近一次写的数据。
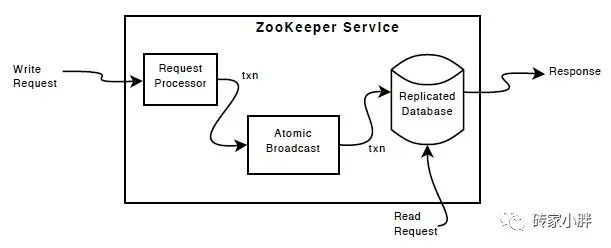
ZooKeeper集群存在数据一致性的问题,我们来看下ZK集群的同步过程。
当客户端向ZK集群发起写请求时,如不是Leader,则将请求转向Leader,然后Leader向所有节点机器发送建议写的消息,所有节点开始写入数据到磁盘,任何一个节点写入成功后,将发回一个ack消息回到Leader节点,Leader节点收到大多数节点发回的ack消息后,说明此时已经有N/2+1节点数据同步成功,故向所有节点发送集群已可以对外提供服务的消息。
我们在以上的流程上,可以发现3台节点机器的话,只需2台同步成功及可以对外提供服务。但有个问题,如果另外一个客户端再次访问的正好是还没同步完的最后那台机器,那获取的则为旧的数据。当最后一台机器同步完,则访问的为新的数据。
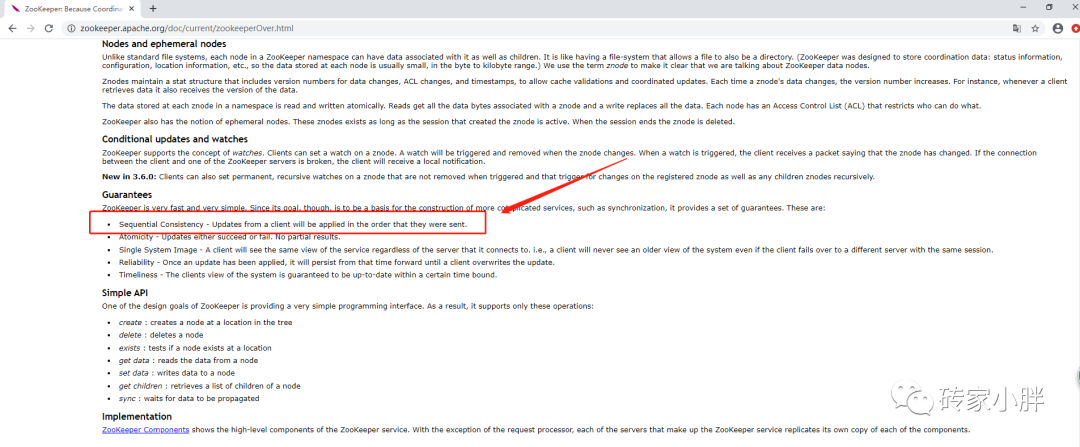
虽然ZK集群Znode节点存储的数据量非常小,同步速度极为迅速(毫秒级),但遇到大规模线程并发访问的极端情况时,还是会出现读取到旧数据的这种问题。通过官网阅读文档后,发现Zookeeper为了保证集群高可用性(总不能数据同步中一直阻塞吧,那岂不是慢死),只保证当前客户端读取的数据为该节点的最新数据,所以ZK集群的数据一致性为:顺序一致性。
再见~~~
