




"Graviton is a bad guy in S.H.I.E.L.D. Season 5."

泰语字符(http://www.unicode.org/charts/PDF/U0E00.pdf),范围是\u0E00~\u0E7F。

于是我们可以通过这种形式来反查,某个字符是什么语言。
埋点:前端展示的字符内容都会按照事先约定的规范格式记录,并传输存储到HDFS上。最基本的字段包括语言站点(比如en-US),以及内容类型(比如name),内容文本(比如Graviton Weng)。
查询:正则表达式可以很简单地匹配Unicode字符范围,我曾经在之前的这篇文章《利用HDFS生态做复杂离线数据处理》中提到过。
报表:把找到的有问题的记录做成T+1报表,同步给相关运营同学。
修复:运营同学按照报表内容修复。
监控:我们聚合每天类似问题出现的数量,并观察趋势。
通过上面的几步,我们可以把这个问题的处理形成闭环。
select *from one_tablewhere (name regexp'[\u0E00-\u0E7F\u30A0-\u30FF\u3040-\u309F\uAC00-\uD7AF\u4E00-\u9FFF]')and locale like 'en-%';
英语站点
name字段包含泰语字符(\u0E00-\u0E7F)
或者日语片假名(Katakana)字符(\u30A0-\u30FF)
或者日语平假名(Hiragana)字符(\u3040-\u309F)
或者韩语字符(\uAC00-\uD7AF)
或者所有汉语字符(\u4E00-\u9FFF)
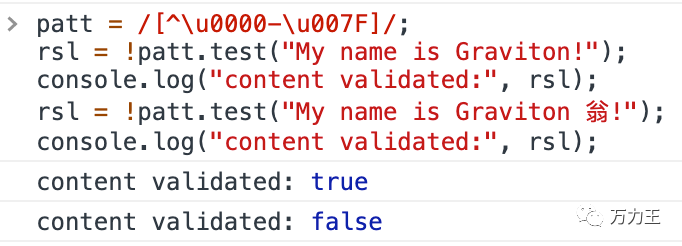
patt = [^\u0000-\u007F]/;rsl = !patt.test("My name is Graviton!");console.log("content validated:", rsl);rsl = !patt.test("My name is Graviton 翁!");console.log("content validated:", rsl);
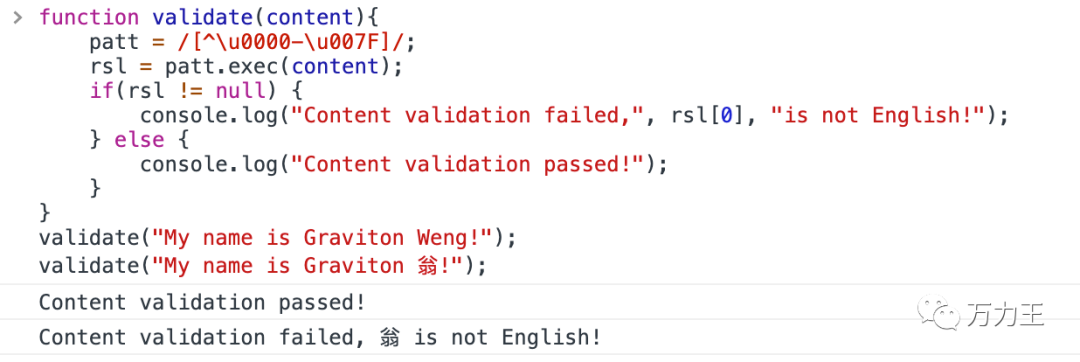
再高端点,我们可以直接告诉用户那个字符不是英语。
function validate(content){patt = /[^\u0000-\u007F]/;rsl = patt.exec(content);if(rsl != null) {console.log("Content validation failed, ", rsl[0], "is not English!");} else {console.log("Content validation passed!");}}validate("My name is Graviton Weng!");validate("My name is Graviton 翁!");
接下来泼点冷水,假如有个输入框限定输入日语呢?我们刚才有提到,日语里也是会用到汉字的,比如有一家酒店的名字叫“東横INN福岡天神”,这里没有标志性的平假名和片假名,却有汉字和英文字符,像这种场景,由于文字上的混用,技术上,我们就没有办法严格禁止输入这样的文字,只能允许或者给一定提示。

下面这张图是另外例子,如果日语站下显示下面的这个内容,并不是一个错误,因为它本身就是这么用的。所以绝对限定后台的输入,并不是一个通用彻底的从根源上解决多语言问题的解决方案。当然,从产品设计层面上,我们也可以有所取舍(比如日语站上放弃下面类型的信息输出),从而可以解决主要问题(比如保证要有日文)。

上一段有提到,各种语言的字符会混合在一起,那我们其实可以统计出每种语言字符的占比,从而给出一个的各语言占比分布,给后续处理提供概率上的建议。比如下面这段话:
浦安の舞浜にあるヒルトン 東京ベイは、東京湾まで歩いてすぐ、東京ディズニーランド®まで車で 3 分です。
我们可以统计出,汉字有 14个,英文(包括数字和空格)4个,平假名和片假名一个有30个,其他特殊符号5个。所以我们可以得到这么一个分布数据:纯日文字符占比57%,纯汉字占比26%,英文(包括数字和空格)占比8%,于是我们可以推测出,这段话是日文的概率有83%(中文字符也可能用在日文里),中文的概率有26%(纯日文字符不会用在中文里),最终我们可以推定这段话是日文。
我们可以用下面这段稍微复杂点的hsql在hive中计算得到这样的结果。
with dx as (// 替换成存储多语言内容的表或者字段select "浦安の舞浜にあるヒルトン 東京ベイは、東京湾まで歩いてすぐ、東京ディズニーランド®まで車で 3 分です。" as content)select// 内容字段content// 每种语言的占比,合成一个用逗号分隔的字符串, concat_ws(",", collect_set(concat_ws(":", lang, ratio))) as ratio_listfrom (selectcontent, lang, round(total/(sum(total) over (partition by content)),2) as ratiofrom (selectcontent, lang, count(1) as totalfrom (selectcontent, tf.c, casewhen tf.c regexp '[\u30A0-\u30FF\u3040-\u309F]' then 'jp'when tf.c regexp '[\u4E00-\u9FFF]' then 'cn'when tf.c regexp '[\u0000-\u007F]' then 'en'when tf.c regexp '[\u0E00-\u0E7F]' then 'tai'when tf.c regexp '[\uAC00-\uD7AF]' then 'kr'else 'other'end as langfrom dxlateral view explode(split(dx.content,"")) tf as c) lxgroup by content, lang) gx) fxgroup by content
浦安の......3 分です。en:0.08,other:0.09,jp:0.57,cn:0.26
上面讨论的其实都是围绕字符集展开的方法,相对比较简单,但是需要了解某种语言对应的字符集范围,在不熟悉某种语言的情况下容易产生遗漏,而且多种语言混合的场景判断比较复杂。
所以,如果家里有矿(因为要收费),推荐可以使用Google Cloud API的Translation API中的detect_language()方法,这里是python版的文档地址https://googleapis.dev/python/translation/latest/index.html:

https://googleapis.dev/python/translation/latest/client.html#google.cloud.translate_v2.client.Client.detect_language
综上,我们讨论完了语言识别的基本方法,这些简单的解决方案,相信能够解决大家绝大多数的问题。如有相关特殊问题,欢迎来私信留言。

