




Timer wheel 是目前 Linux 中基于 tick 粒度(也叫 jiffies)的时间管理机制。作为中断的一种,以现在通用的 1000 HZ 计,tick 发生的频率还是比较高的。之所以采用 timer wheel 这样一种数据结构来实现(而不是其他),是值得探究一番的问题。
单一结构
可用来实现 timer 机制最简单的数据结构应该是数组, 插入、删除和查找的复杂度都是 O(1),但如果直接采用一级纯数组的形式,要么无法兼顾时间的精度和范围,要么就需要耗费大量的内存空间。
这本质上是由于 timer 的稀疏特性,即在一条时间线上,需要触发 timeout 的时间点是比较少的。那么哪些数据结构可以解决「稀疏性」的问题呢?linked list 和 binary tree。
先来看纯链表的形式,早期的 Linux,以及 RT-Thread 都是这么做的,查找的复杂度为 O(n),在系统整体 timer 数量不太多时,完全可行。
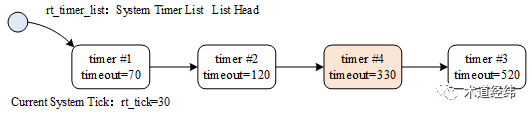
那纯树形结构呢?Linux 中最为广泛采用的一种二叉树恐怕就是 rbtree 了,从进程内存管理的 VMA,到 CPU 调度的 CFS,再到文件事件监听的 epoll,都有它的身影。同样地,rbtree 的结构也被 Linux 中以 nanosecond 为单位的 high-resolution timer (简称 hrtimer)所采用,其查找的复杂度为 O(log n) 。
hrtimer 以 per-CPU 的形式组织,并且区分了CLOCK_MONOTONIC 和 CLOCK_REALTIME,可以在一定程度上控制 rbtree 的深度。
如果以 timeout 的数值为 key,始终把数值最小的保持在 rbtree 的最左侧,那么很容易找到最近一个触发的 timer,这在 tickless 模式中颇为有用(因为进入休眠态前,需要计算下一个确定到来的时钟,以便被唤醒),当然付出的代价是需要适时地进行二叉树的平衡。
组合结构
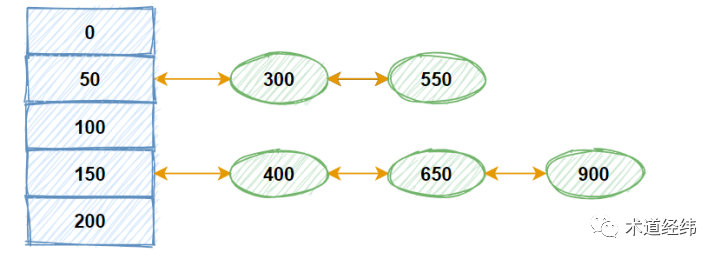
接下来我们稍微组合一下,数组 + 链表,算是 hash table 吧,比如 50ms, 300ms, 550ms 的 timer 挂在同一个 bucket entry 上,这将有助于应对 timer 数量过多导致链表超长的问题。
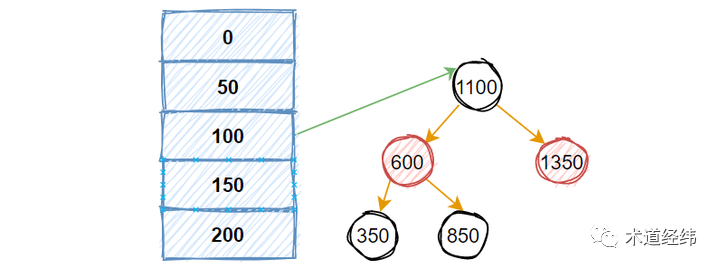
数组 + rbtree 呢,也不失为一种分而治之的思路。
当然还可以是 数组 + 数组(或者说 数组 * 数组) 的方式,这种最接近日常生活所使用的时钟模式,正是 timer wheel 的雏形。
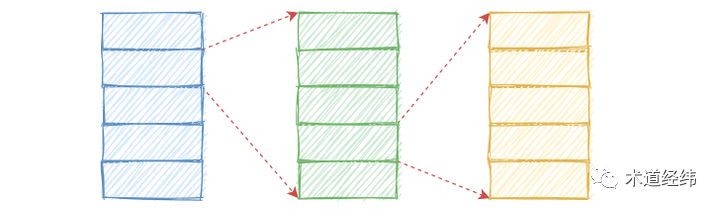
假设一个 timeout 是当前时间开始后的 2 小时 30 分 45 秒,那么先插入到以 hour 为单位的第一级数组里(2 小时的 entry),2 小时之后,再移动到以 second 为单位的第二级数组里(30 分钟的 entry),以此类推。插入、删除和查找的复杂度还是 O(1),实现上也没有特别的复杂。
数组间的迁移是存在开销的,但 timeout 作为时间上限,用于超时等待的场景,属于 fail 的情况,通常会提前解除,所以这种跨越多级的,大概率在第一级就已经被移除。
时间和空间
说起多级数组,有没有想到 page table 或者 radix tree,它们都是用一个 word 里的若干 bits 索引一级,都用于解决稀疏性的问题,不过存在的一个区别是:page table 和 radix tree 的子级数组是多个,呈真正的树形结构,而 timer wheel 的每级数组都是单个。
前面两者作为地址,代表空间,而 timeout 代表时间。对于 timer wheel 的每一级,其实也可视作是多个叠加成了单个。时间本来应该是单调递增的,但由于人为的划分,它成了可以回滚和递进的,因此可以重叠。
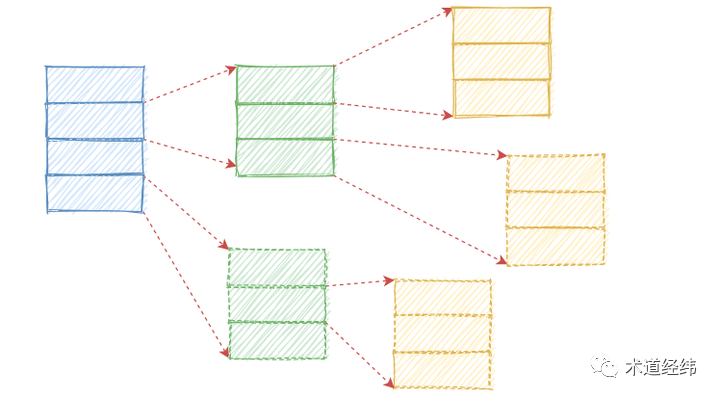
那你说地址可不可以也这样叠加呢?不太适合,空间是静态的,而时间是动态的,过去的时间已消失,而空间一直在。
