




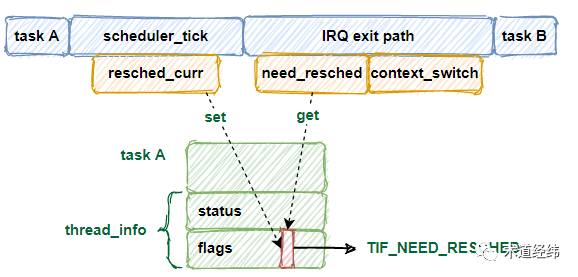
上文介绍了「调度标志位」的设定,当调度的时机到来,除了因等待 I/O 资源需要 block 时可以直接调用 schedule() ,其他情况大多需要对该标志位进行检查。
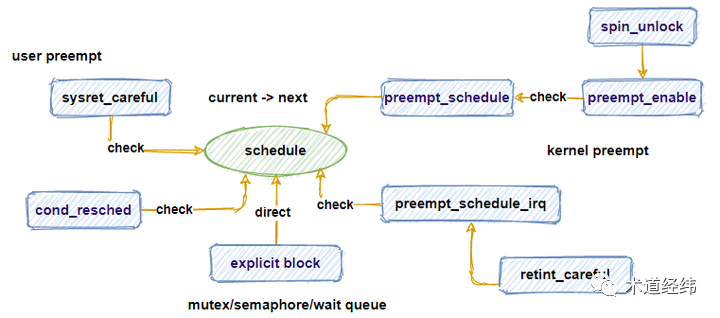
说起这个「执行调度」的时机,在 Linux 内核的 2.4 时代,除非显示 block,否则通常只允许从 system call 或者 interrupt 返回用户态的时候发生抢占(即产生中断前,也在用户态),这可称之为 "User Preemption"。

到了 2.6 内核,开始允许从 interrupt 返回内核态时也进行抢占(即产生中断前,是在内核态)。既然允许任务在内核态抢占,那么在执行一些不能睡眠的操作时(比如持有 spinlock),就需要通过 preempt_disable() 暂时关闭抢占。当调用 preempt_enable() 开闸时,又成为一个新的抢占点。

对应地,这可称之为 "Kernel Preemption",由内核配置项 "CONFIG_PREEMPT" 使能。相比 user preemption 所对应的配置项 "CONFIG_PREEMPT_NONE",它增加了抢占的机会,有利于降低系统的延迟。
为什么要支持抢占?是为了公平吗?那只是表象,降低延迟才是其真正的目的。
再激进一点,使用 "CONFIG_PREEMPT_RT",那就是 Real-Time Linux 了(不过一直以 patch 形式维护,未能合入 mainline)。
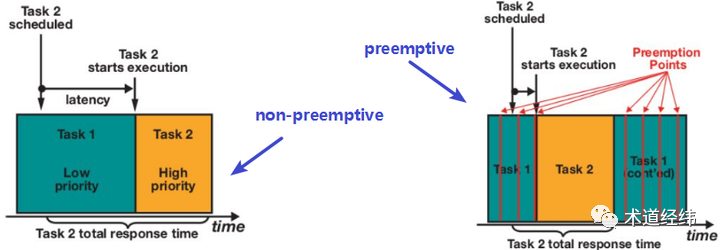
但 latency 和 throughput 往往难以兼顾。响应迅速,适合桌面这种交互式应用,而对于服务器应用,更看重的往往是吞吐量。因此,在 CentOS-7/8 上,你会看到它默认的配置是 "CONFIG_PREEMPT_VOLUNTARY"。
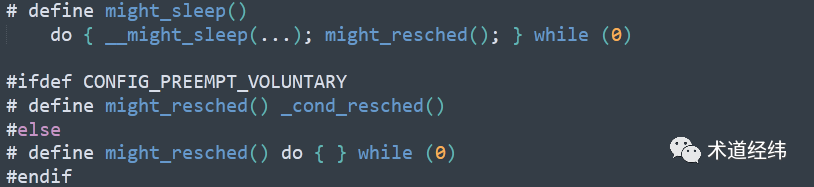
这个 voluntary 其实是一种折衷的策略(注-1)。在内核代码中,我们经常可以看到 might_sleep() 的身影。这个宏本来是用于辅助调试的,当它在 atomic 上下文被调用时,会给出错误提示。但同时,它出现的位置也是一个潜在的调度点,因此它被 voluntary 配置所利用,成为了一个检查 "need schedule" 标志位的时机(也就是这个 "cond" 所代表的 "condition")。
"need schedule" 标志位被“消费”后,需通过 clear_tsk_need_resched() 清除。如果调度条件全部满足,那么当前运行的任务 dequeue(由 "prev" 表示),抢占成功的任务 enqueue(由 "next" 表示),然后进行必要的「上下文切换」。
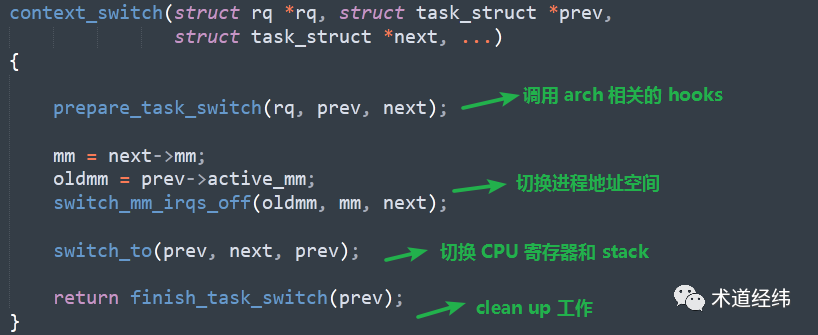
至此,从标记调度,到真正执行调度,以 tick 时钟中断为例,一个简略的流程示意图大致如下:
【注-1】
不过,也不乏拥护者。抢占点越丰富,设计需要考虑的因素也越多,理论上出问题的概率也会越大。当 kernel preemption 这个新生事物出现时,本着 "make-the-bugs-less-probable" 的保守原则,有些人更愿意退而求其次,使用 voluntary 这种中间路线,既可以尝到一点「低延迟」的甜头,也不至于太冒进。
