




说明:本文的立意主要来自https://lwn.net/Articles/843326/
在没有MMU的系统上,伴随内存分配,存在着「内存碎片」的问题。那像Linux这种支持虚拟内存地址的系统,有没有类似的问题呢?
如果不要求分配的内存在物理上连续,那就没有,如果要求,可以说还是有的,但在一定程度上可以通过compaction解决。
一般讲到必须「物理连续」,大家可能会想到DMA设备,但随着虚拟化技术的盛行,现在出现了一种新的场景。我们常说什么支持CPU热插拔、内存热插拔,但实际使用下来你会发现,可能很多的hypervisor都支持虚拟机(VM)内存的动态添加,但是不支持内存的动态减少,吃进去容易吐出来难。原因何在?
如果要减少VM的内存(相当于拔掉VM的一块内存条),那么从host的角度,就需要从这台VM上剥离出一整块物理地址连续的huge page。即便VM空余的内存大小满足要求,要凑出这样一块huge page,也往往涉及到大量page的迁移。
但不是所有的page都可以移动,如果在一片可移动的page中散落着几个不能移动的page,那么这一整块内存都会受到影响。
假设下图所示的包含32个page的内存区域,绿色和红色分别代表movable和unmovable的页面,通过compaction操作都至多规整出8个物理连续的page,做不到16个。
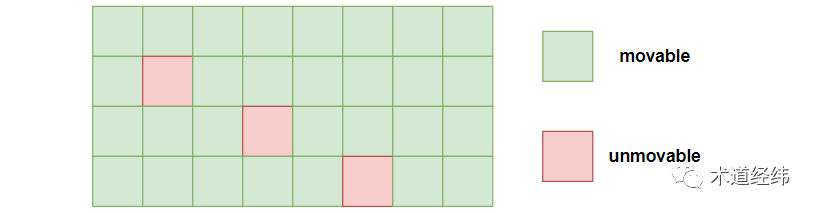
这些unmovable的page啊,真是像路障一样,拖累了无辜的可移动page。于是这些可移动的page经过上诉,为自己赢得了一片专属的区域(ZONE_MOVABLE),在这个区域内,原则上只允许movable的page进来。
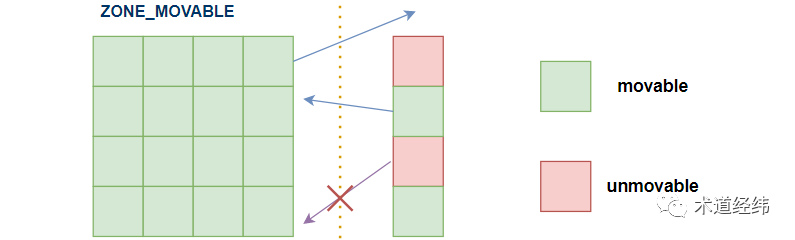
这算是在compaction的基础上,为防止内存fragmentation的进一步举措,可以帮助实现对VM内存的hot remove。
可是好死不死,如果一个"ZONE_MOVABLE"内的页面被pin住了,就不能被迁移到内存的其他地方去了,更不能换出到磁盘,此时整个内存区域就不能被hot remove。这个patch(https://lore.kernel.org/lkml/CA+CK2bBffHBxjmb9jmSKacm0fJMinyt3Nhk8Nx6iudcQSj80_w@mail.gmail.com/)的作者Pavel Tatashin就遇到了类似的问题,他为此想出的解决办法是这样的:
如果要pin的页面还没有被分配,就在"pin_user_pages_*" 函数族中,增加一个flag,以指示page fault的处理函数从non-movable的区域分配。

如果要pin的页面已经存在于"ZONE_MOVABLE",就先将其移动到其他区域(离开偶们这片纯洁的movable zone),要是移动失败,哼,那pin就别想成功。迁移无疑会增加pin操作本身的开销,但减少了系统潜在的「内存碎片」,同时增加了内存hot remove成功的概率。
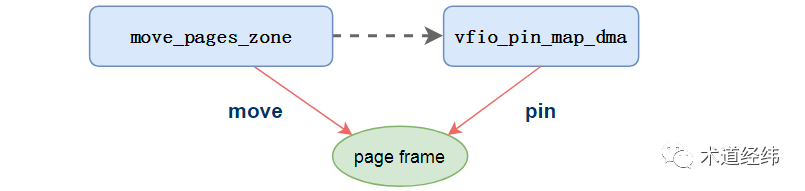
前面介绍CMA的时候曾经提到,CMA类型的页面要求比普通"MIGRATE_MOVABLE"类型的更加严苛,以保证其特定区域内的页面始终为movable的状态。在此patch具体的实现中,就是借鉴了CMA的设计法则,并将其具有的一些特性通用化。
如果应用程序事先知道一个页面是需要长期pin住的(比如属于用户态DMA映射的页面),更好的做法是在分配页面的时候,就通过madvise()函数,告知内核从不参与热插拔的内存区域分配,省去之后migration的开销。
