




本系列文章是以docker为主题展开的,但讲到现在,还没有说明docker的具体使用方法。这是因为要理解docker的使用,还缺了一项关键技术的介绍,即union filesystem。
假设有三个文件系统,它们的目录和文件布局如下图所示:
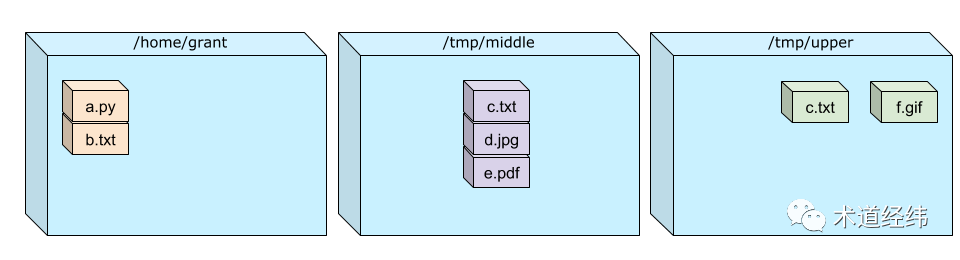
现在将它们按照从左到右的顺序,层层堆叠起来:
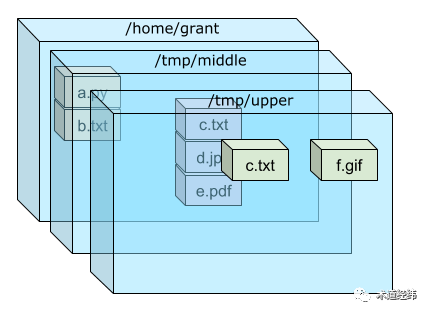
这实际上是做了一个合并,其结果就是:如果底层在某个目录下有文件而顶层没有,那么合并后你还可以看到它,而如果顶层的文件系统在这个位置上也有文件,那么底层对应位置的文件就被无情的覆盖了。

如果你看过前面介绍文件系统mount的文章,应该发现这其实利用的就是"union mount"的方式。想象你用画图软件(比如笔者常用的draw.io)先后画两个方框,如果这两个方框在图纸上的位置有重叠的部分,那么先画的那个框在重叠的部分就看不到了。
在类Unix系统中(比如Plan 9),union mount/filesystem的概念其实由来已久,即便是相对年轻的Linux,也早在93年就开始了对它的探索,但很多年过去了,它却一直没能进入Linux的mainline。
2010年的时候,Valerie Aurora曾在LWN上撰文说:如果你是和Linux中union mount的第一版实现同时出生的话,那么现在应该已经开始准备大学入学的申请了(整整17年啊)。而且Valerie还表示自己要转行了,不做程序员了,他的一位朋友给他发email说:
看到你要转行的消息,最开始是觉得很遗憾的,我们又少了一位hacker,但是我突然想起你在blog里曾经说过:在转行之前要让union mount进入mainline。看来,这至少还得好几年呢,你呀,一时半会儿转不了行了,我们还可以一起hack啊。
可见,union mount/filesystem进入mainline的过程,真是「路漫漫其修远兮」啊。
一方面原因是union fs可能涉及到VFS层的改动,牵涉面较广,另一方面是因为Linux支持的文件系统千差万别,除了基于磁盘的文件系统(像ext4, xfs),还有基于网络的文件系统(比如NFS),甚至还有内存文件系统(proc, sys等),要将这些存在巨大差异的文件系统都和union filesystem融合起来,难度着实不小。
横空出世 - OverlayFS
直到我们的主角docker的出现,才推动并完成了这一场马拉松。一个名为OverlayFS的union文件系统的实现被docker所采用,并最终于3.18版本正式merge进内核。而OverlayFS之所以能够成功突围,很大程度上是因为它的简洁性。
OverlayFS是一种抽象的文件系统,它并不直接参与存储,而是建立在其他文件系统之上(比如xfs),其主要功能是合并底层文件系统,然后提供统一的文件视图供上层使用。
OverlayFS最开始使用的驱动是overlay,而后升级为overlay2,使用overlay2需要4.0内核(或者redhat/centos7.3对应的3.10.0.514)之后的版本。
那OverlayFS到底是如何在docker中发挥作用的呢?实践出真知,当你接下来扎扎实实地使用一下docker,应该就能理解个八九不离十了。
【安装docker】
以CentOS 7作为host(宿主机)为例,直接使用以下命令安装docker服务:
# yum install docker
如果不能成功(可能由于CentOS版本或者镜像源的不同),请参考官方文档进行安装。安装后默认是没有启动docker服务的,需手动启动:
# systemctl enable --now docker
【获取images】
然后,可以通过"pull"命令(和git一样)从docker的远端仓库(称为registry)拉取所需的镜像。比如下载和host一样的CentOS 7.7的docker版本的镜像:
# docker pull centos:7.7.1908
如果不指定具体的版本号,那么将默认下载最新的CentOS版本。在下载的过程中,你会发现镜像大小只有几十MB,extracting解压后也只有200多MB,远小于一个标准的CentOS镜像的大小。

来看下此时docker的layer分布,只有一层"Image layer":

【启动container】
一个ELF可执行文件,启动后形成一个进程。同样地,基于这个下载的image启动的,就是一个container。
ID是用来识别不同的images和containers的,所以这里只需用前面两个数字"08",docker就知道你指定的是哪一个image。
# docker run -it 08 bin/bash
先退出docker的bash(用"ctrl+p"加上"ctrl+q"),在host上使用"ps"命令(和查看进程的命令一样)查看系统中运行的所有containers的信息。目前有一个正在运行的container,它是基于ID为"08"的image创建的。

再来看下docker layer的变化,新增的这一部分就是这个container对应的layer(称为"Container layer"):

【修改container】
现在,通过"attach"的方式重新进入这个ID为"8e"开头的container的bash。
# docker attach 8e
进入container后,先做一些目录的查看,以便之后的实验对比(红框部分是接下来准备操作的文件):

对一个文件的写操作包括修改、新建、重命名和删除,下面就在container的根目录下分别执行这4种操作:

对于修改操作,会触发copy on write(简称COW),从"Image layer"中找到这个文件,复制一份到"Container layer"中(如下面图 1中的file2)。因为是向上层layer复制,所以这个过程被称为"copy up"。
OverlayFS因为是工作在文件系统层,而不是block层,对于一个较大的文件,即便只修改了一小部分,也需要整体复制,这会对性能造成一定的影响(好在只需要第一次修改的时候进行copy up操作)。
对于新建操作,新生成的文件(如图 1中的file4)只存在于"Container layer"中。
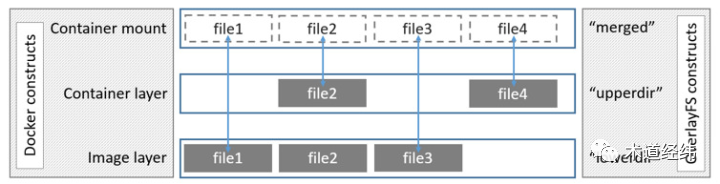
真正麻烦一些的是删除操作,因为"Image layer"是只读的,container不能、也不应该去删除"Image layer"中的东西,所以OverlayFS采用的办法是:在"upperdir"创建一个whiteout文件,"lowerdir"对应的文件依然存在,但whiteout文件可以阻止对"lowerdir"的这个文件的访问,从container的用户视角,就是删除了。
上面说的这个「container的用户视角」,在docker的层次里,就是"Container mount",对应OverlayFS的"merged"层。
对于没有被修改的文件(如图 1中的file1和file3),"merged"层中的文件直接link到"Image layer"中(link关系由蓝色箭头表示)。
对于修改过和新增的文件,"merged"层中的文件link到"Container layer"中。
删除的文件,在"merged"层中不再存在。
【查看变化】
接下来再次退出docker,进入host中表示"Container layer"的目录:

"diff"目录存储的是"Container layer"相对于"Image layer"差异的部分,不过现在里面的内容好像并没有反映出我们之前在container中的修改(原因将在之后给出):

"merged"目录存放的是图 1所示的"Container mount/merged"层,嗯,结果符合预期。

如果想把之前container所做的修改保存下来,那么就用"commit"提交一下:
# docker commit -m "commit-test" 8e docker.io/centos:7.7.commit
不光命令的名称,连添加comment的参数都和git一样。git执行commit后会形成一个新的节点,docker同样如此:

从输出结果的"SIZE"来看,大小和原来的image差不多,难道是整体复制了一份?git可不是这样玩的啊,每commit一次,只会多一个diff。还是先来看下此时docker的layer又有哪些变化吧:

又多了一个目录,通过对比,可以知道这就是commit后新生成的image对应的layer。进入这个目录:

重点是这个diff文件夹:
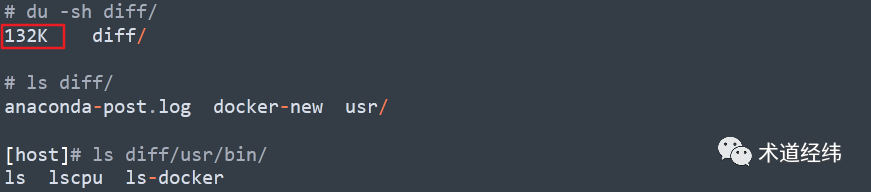
不就是我们之前动过的那些文件么。所以啊,要commit之后才能生成diff。讲到这里,来一张git的flow图示:
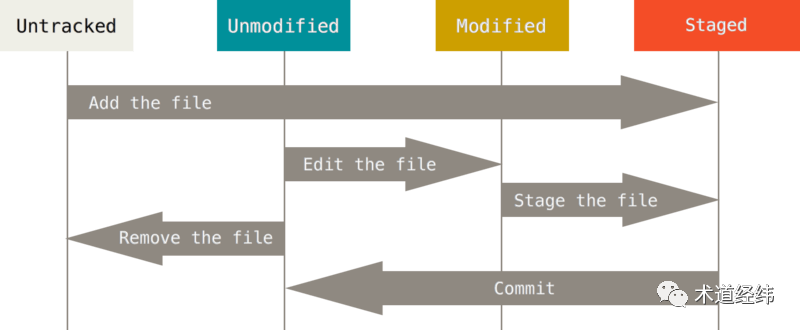
拿着这张图,套到docker身上,"Unmodified"就是只在"Image layer"中的,如果在container中被修改了,就变成"Modified"状态了,需要commit,将修改保存下来。在新生成的"Image layer"中,它又是"Unmodified"的,可以基于这个新的"Image layer"再运行container,进行新的修改。
对于container中删除的文件,新的"Image layer"中不会含有,但如果像git一样,checkout到删除之前的某个commit节点(对应更底层的"Image layer"),还是可以找到这个文件。
就像可以基于任何一个git的commit节点来checkout一个branch一样,你也可以基于任何一层"Image layer"来运行一个container。
如果checkout了branch不进行修改,那么只是增加了一个对原节点的link,如果修改后不commit就删除了这个branch(对应container),那么不会新增任何内容,就好像什么都没有发生过一样。
copy on write技术还用在父进程fork子进程的实现中,所以从某种程度上,"Container layer"也理解为是fork了"Image layer"。
【多个containers】
基于一个ELF镜像文件,可以启动多个进程,同样地,基于一个docker的image可运行多个container,每个container都是这个image的一个instance。
【存在的问题】
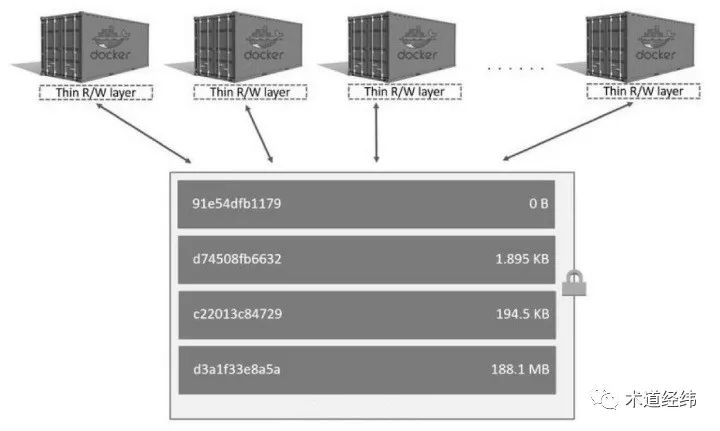
要判断一个"merged"层中的文件是不是基于"Image layer"修改过的,可通过"ls -i"命令查看其inode编号,再对比"Image layer"中对应文件的inode编号。
如果两者的inode编号相同,说明是同一个文件,即便有多个container中的"merged"层都指向这个文件,它们也是共享该inode对应的adress_space的,或者说共享page cache的,因而没有额外的内存开销。
而如果inode编号不同(比如上面示例中的file2),那么就是修改过的,对应两个不同的文件实体。因此,即便它们只有微小的差异,也不能共享page cache。比如这个文件在page cache中包含10个page,"Container layer"只修改了这个文件对应的1个page的内容,那么它们在page cache中总共也是占20个pages。
那如何让它们在page cache中共享内容相同的那9个pages呢?在容器技术出现之前,它的先驱(即传统的虚拟机技术),也遇到过同样的问题,采用的办法是KSM,即通过hash比对,合并相同的pages。
多个inodes带来的问题还不止于此,比如"Image layer"的一个文件是被lock的,那你copy up到"Container layer"是不是也要复制这个lock状态呢?再比如fanotify,当你设定了对"Image layer"中的某个文件的notify,而之后它在"Container layer"中被修改了,那能得到通知吗?
小结与展望
容器技术还没有发展到完美的程度,但它确实在伴随着Linux内核技术不断地完善,比如之前container可以看到过多的procfs信息这一饱受诟病的缺陷,就正在通过proc中支持多个private instance的特性来解决。
docker自2013年出道以来,仅过了1-2年的时间就红透了半边天,在业界几乎无人不知,无人不晓。就笔者自身的使用体验来看,可能因为它真的太好用了吧,比如用来搭建适用于不同发行版的package的编译环境,可以共享host上的文件(减少磁盘空间占用),同步代码修改,不“污染”host上的环境,安装便捷,启动快速,还方便迁移……
最后,来思考一个问题:"container"对Linux来说到底是什么?Cgroup, Namespace, OverlayFS,这都只是一些utilites,它们被container利用起来,在user space构建了一个个运行时环境。而在内核中,并没有像task_struct, file_struct这样一个对container进行描述和抽象的数据结构。也就是说,container它并不是一个kernel object,从内核的角度,它并不知道"container"是什么。
