




networkpolicy是k8s对于pod的网络安全的一种抽象描述,社区很多开源网络方案都支持networkpolicy,如calico、openshift-sdn。网易数帆的K8s平台对calico/felix进行改造,设计实现了一套即插即用、高兼容性的networkpolicy addons,并应用到网易内部的多种k8s网络中。本文分上下篇,本文为上篇,解析networkpolicy以及calico/felix的设计实现,下篇将介绍通用的felix插件设计面临的问题及对应的解决方案。
Networkpolicy的含义与现状
networkpolicy 是k8s在很早就提出的一个抽象概念。它用一个对象来描述一类pod的网络出入站规则。
networkpolicy的作用对象是pod,作用效果包括出站、入站,作用效果拓扑包括IP段、namespace、pod、端口、协议。
与以往IaaS服务场景下,针对虚拟机、网卡对象的安全组规则不同, networkpolicy是k8s原语 。因此,在k8s场景下,进行网络安全规则的规划时, 用networkpolicy能做到更加的灵活和自动化 。举个例子:
有一套工作负载A是做类似数据库代理一类的工作,它只允许代理服务B访问,不允许其他业务访问。
在k8s场景下,如果不使用networkpolicy,我们需要规划好A类pod的部署节点,配置相应的ACL规则,将B类pod的IP予以放行,一旦A/B类pod做了扩缩容,可能要在重新配置一份甚至多份ACL规则。
在k8s场景下,我们会给A和B类分别配置label,创建好networkpolicy后限制A只放行B类pod,每当A或B扩缩容时,无需做任何额外操作。
网易数帆的networkpolicy支持
网易数帆的外部用户中,基于交付的openshift-sdn方案或calico方案,这些方案都可以原生地支持networkpolicy(下文会介绍)。
但网易内部用户(使用vpc或bgp CNI)大多是由PE规划管理IP白名单,限制某些网络访问,除此之外没有做任何跨业务的网络限制(比如说:离线转码业务与支付业务是互不相干的,但是两种业务的pod彼此网络是可通信的)。因此一直没有networkpolicy的需求,而vpc、bgp等内部使用的CNI也还一直没有实现相关功能。
未来随着业务规模的扩大,类似的网络安全策略是必不可少的,因此我们会在接下来逐步将networkpolicy enable。
业界的networkpolicy实现
当前社区对于k8s的networkpolicy的实现,不外乎三种方案:
| 方案 | 依赖 | 案例 | 支持的CNI |
|---|---|---|---|
| 基于iptables+ipset实现规则 | 容器流量需要经过宿主机的协议栈 | calico felix | calico、flannel、terway |
| 基于ovs流表实现规则 | 使用openvswitch | openshift-sdn | openshift-sdn |
| 基于ebpf hook实现规则 | 需要较高版本内核 | cilium | cilium、flannel、terway |
从上面的表格可以看出:
基于ovs流表实现的方案,典型的就是 openshift-sdn ,此前我们分享过一篇 openshift-sdn的详解 ,介绍了里面对ovs table的设计,其中有一个专门的table(tableid=21)就是用来实现networkpolicy的规则。该方案是直接内建于openshift-sdn项目,基本无法移植。而openshift-sdn虽然代码开源,但设计上、代码逻辑上与openshift平台耦合还是比较紧密的。比如说:
公开的openshift-sdn部署方案需要依赖openshift-network-operator
openshift-sdn代码中硬编码了要访问的容器运行时为crio,不支持dockershim
cilium 是最先使用ebpf技术实现网络数据面的CNI,它力图实现大而全的容器网络,封装、加密、全面、高性能等特点应有尽有,它对于networkpolicy的支持也已经十分完善。但ebpf hook的实现方式,依赖较高的内核版本,且在数据面排障时比较吃力。ebpf技术对于网络性能的提升很大,未来势必会越来越流行,所以值得关注。
基于iptables+ipset技术实现的方案,其实在几年前就比较成熟了calico-felix、romana、kube-router等开源的网络方案都是基于此实现了支持networkpolicy。其中, felix 是calico网络方案中的一个组件,官方支持在calico中enable networkpolicy,且能够与flannel配合使用。阿里云的terway便是直接套用felix实现了对networkpolicy的支持(最近还套用了cilium)。这套方案要求容器流量要进过宿主机协议栈,否则包就不会进入内核的netfilter模块,iptables规则就无法生效。
目标
基于上述现状,我们希望基于现有的开源实现方案,进行兼容性调研或改造,适配网易数帆的各种网络方案,如:
netease-vpc
netease-bgp
flannel
...
因为这些网络方案都满足felix的要求,同时felix有较为活跃的社区和较多的适配案例,因此我们决定基于felix,实现一套即插即用的networkpolicy addon。本文接下来将会着重介绍该方案的实现。
calico/felix的设计实现
架构
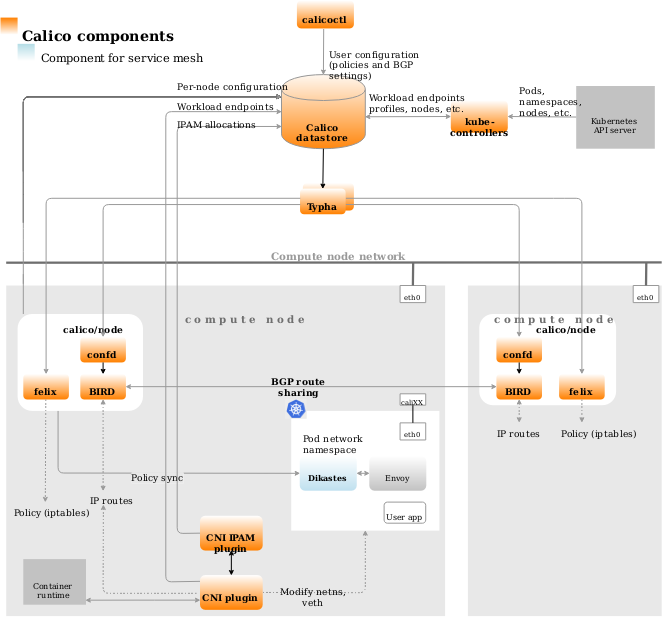
calico在部署架构上做了多次演进,本文以v3.17.1为准。calico的完整架构包括了若干组件:
calico/kube-controllers:calico控制器,用于监听一些k8s资源的变更,从而进行相应的calico资源的变更。例如根据networkpolicy对象的变更,变更相应的calicopolicy对象
pod2daemon:一个initcontainer,用于构建一个Unix Domain Socket,来让Felix程序与
Dikastes
(calico中支持istio的一种sidecar,详见 calico的istio集成 )进行加密通信.cni plugin ipam plugin:标准的CNI插件,用于配置/解除网络;分配/回收网络配置
calico-node calico-node其实是一个数据面工具总成,包括了:
felix:管理节点上的容器网卡、路由、ACL规则;并上报节点状态
bird/bird6:用来建立bgp连接, 并根据felix配置的路由,在不同节点间分发
confd:根据当前集群数据生成本地brid的配置
calicoctl:calico的CLI工具。
datastore plugin:即calico的数据库,可以是独立的etcd,也可以以crd方式记录于所在集群的k8s中
typha:类似于数据库代理,可以尽量少避免有大量的连接建立到apiserver。适用于超过100个node的集群。
官网 给出了calico整体的组件架构图:
原理
在网络连通性(Networking)方面:calico的数据面是非常简单的三层路由转发。路由的学习和分发由bgp协议完成。如果k8s的下层是VPC之类的三层网络环境,则需要进行overlay,calico支持ipip封装实现overlay。
在网络安全性方面:calico考虑到其Networking是依赖宿主机协议栈进行路由转发实现的,因此可以基于iptables+ipset进行流量标记、地址集规划、流量处理(放行或DROP),并且基于这些操作可以实现:
networkpolicy的抽象概念
calico自定义的networkpolicy,为了在openstack场景下应用而设计
calico自定义的profile,已废弃。
这里所有的iptables规则都作用在:
pod在宿主机namespace中的veth网卡(calico中将之称为workload)
宿主机nodeIP所在网卡(calico中将之称为host-endpoint,实际上这部分规则不属于k8s的networkpolicy范畴)。
主要包括如下几类规则:
iptables的INPUT链规则中,会先跳入
cali-INPUT
链,在cali-INPUT
链中,会判断和处理两种方向的流量:pod访问node(
cali-wl-to-host
)实际上这个链中只走了cali-from-wl-dispatch
链,如果是应用在openstack中,该链还会允许访问metaserver;如果使用ipv6,该链中还会允许发出icmpv6的一系列包来自node的流量(
cali-from-host-endpoint
)iptables的OUTPUT链中,会首先跳入
cali-OUTPUT
链,在cali-OUTPUT
链中,主要会处理:访问node的流量(
cali-to-host-endpoint
)的流量iptables的FORWARD链中,会首先跳入
cali-FORWARD
链,在cali-FORWARD
链中会处理如下几种流量:cali-from-hep-forward
cali-from-wl-dispatch
cali-to-wl-dispatch
cali-to-hep-forward
cali-cidr-block
k8s的networkpolicy只需要关注上述流量中与pod相关的流量,因此只需要关心:
cali-from-wl-dispatch
cali-to-wl-dispatch
这两个链的规则,对应到pod的egress和ingress networkpolicy。
1.除了nat表,在raw和mangle表中还有对calico关注的网卡上的收发包进行初始标记的规则,和最终的判断规则。
2.在https://github.com/projectcalico/felix/blob/master/rules/static.go中可以看到完整的静态iptables表项的设计
接着,iptables规则中还会在 cali-from-wl-dispatch
和 cali-to-wl-dispatch
两个链中根据收包/发包的网卡判断这是哪个pod,走到该pod的egress或ingress链中。每个pod的链中则又设置了对应networkpolicy实例规则的链,以此递归调用。
这样,pod的流量经过INPUT/OUTPUT/FORWARD等链后,递归地走了多个链,每个链都会Drop或者Return,如果把链表走一遍下来一直Return,会Return到INPUT/OUTPUT/FORWARD, 然后执行ACCEPT,也就是说这个流量满足了某个networkpolicy的规则限制。如果过程中被Drop了,就表示受某些规则限制,这个链路不通。
我们通过一个简单的例子来描述iptables这块的链路顺序。
felix实现networkpolicy的案例
假设有如下一个networkpolicy:
spec:
egress:
-{}
ingress:
-from:
- podSelector:
matchLabels:
hyapp: client1
-from:
- ipBlock:
cidr:10.16.2.0/24
except:
-10.16.2.122/32
ports:
- port:3456
protocol: TCP
podSelector:
matchLabels:
hyapp: server
他作用于有
hyapp=server
的label的pod这类pod出方向不限制
这类pod的入站规则中只允许如下几种流量:
hyapp=client1
我们使用 iptables -L
或 iptables-save
命令来分析机器上的iptables规则。
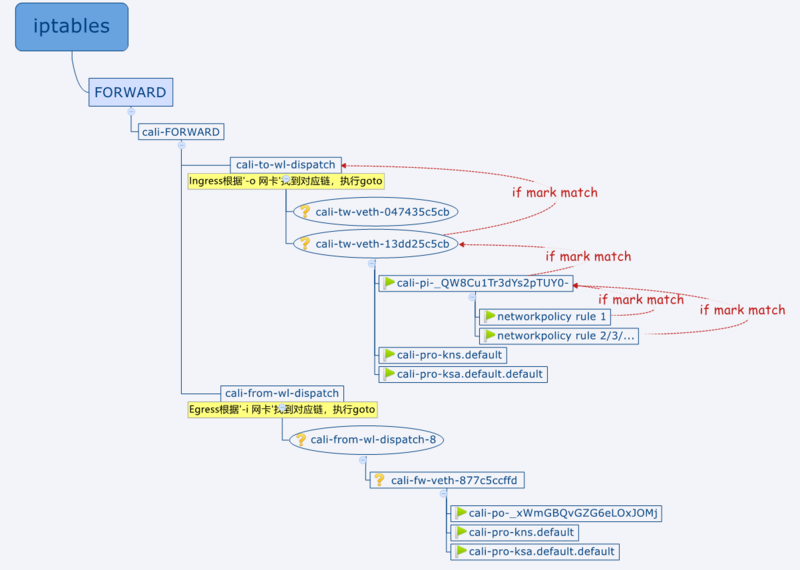
因为是入站规则,所以我们可以观察iptables表中的 cali-to-wl-dispatch
链。另外,该networkpolicy的作用pod只有一个,它的host侧网卡是 veth-13dd25c5cb
。我们可以看到如下的几条规则:
Chain cali-to-wl-dispatch (1 references)
target prot opt source destination
cali-to-wl-dispatch-0 all -- anywhere anywhere [goto]/* cali:Ok_j0t6AwtLyoFYU */
cali-tw-veth-13dd25c5cb all -- anywhere anywhere [goto]/* cali:909gC5dwdBI3E96S */
DROP all -- anywhere anywhere /* cali:4M4uUxEEGrRKj1PR *//* Unknown interface */
注意,这里有一个 cali-to-wl-dispatch-0
的链,是用来做前缀映射的, 该链的规则下包含所有 cali-tw-veth-0
这个前缀的链:
Chain cali-to-wl-dispatch-0(1 references)
target prot opt source destinationcali-tw-veth-086099497f all -- anywhere anywhere [goto]/* cali:Vt4xxuTYlCRFq62M */
cali-tw-veth-0ddbc02656 all -- anywhere anywhere [goto]/* cali:7FDgBEq4y7PN7kMf */
DROP all -- anywhere anywhere /* cali:up42FFMQCctN8FcW *//* Unknown interface */
这是felix设计上用于减少iptables规则遍历次数的一个优化手段。
我们通过 iptables-save |grep cali-to-wl-dispatch
命令,可以发现如下的规则:
cali-to-wl-dispatch -o veth-13dd25c5cb-m comment --comment "cali:909gC5dwdBI3E96S"-g cali-tw-veth-13dd25c5cb
意思就是:在 cali-to-wl-dispatch
链中,根据pod在host侧网卡的名字,会执行 cali-tw-veth-13dd25c5cb
链, 我们再看这条链:
Chain cali-tw-veth-13dd25c5cb(1 references)
target prot opt source destination
1 ACCEPT all -- anywhere anywhere /* cali:RvljGbJwZ8z9q-Ee */ ctstate RELATED,ESTABLISHED
2 DROP all -- anywhere anywhere /* cali:krH_zVU1BetG5Q5_ */ ctstate INVALID3 MARK all -- anywhere anywhere /* cali:Zr20J0-I__oX_Y2w */ MARK and0xfffeffff
4 MARK all -- anywhere anywhere /* cali:lxQlOdcUUS4hyf-h *//* Start of policies */ MARK and0xfffdffff
5 cali-pi-_QW8Cu1Tr3dYs2pTUY0- all -- anywhere anywhere /* cali:d2UTZGk8zG6ol0ME */ mark match 0x0/0x20000
6 RETURN all -- anywhere anywhere /* cali:zyuuqgEt28kbSlc_ *//* Return if policy accepted */ mark match 0x10000/0x10000
7 DROP all -- anywhere anywhere /* cali:DTh9dO0o6NsmIQSx *//* Drop if no policies passed packet */ mark match 0x0/0x20000
8 cali-pri-kns.default all -- anywhere anywhere /* cali:krKqEtFijSLu5oTz */
9 RETURN all -- anywhere anywhere /* cali:dgRtRf38hD2ZVmC7 *//* Return if profile accepted */ mark match 0x10000/0x10000
10 cali-pri-ksa.default.default all -- anywhere anywhere /* cali:NxmrZYbhCNLKgL6O */
11 RETURN all -- anywhere anywhere /* cali:zDbjbrN6JPMZx9S1 *//* Return if profile accepted */ mark match 0x10000/0x10000
12 DROP all -- anywhere anywhere /* cali:d-mHGbHkL0VRl6I6 *//* Drop if no profiles matched */
第1、2条:如果ct表中能检索到该连接的状态,我们直接根据状态来确定这个流量的处理方式,这样可以省略很大一部分工作。
第3条:先对包进行标记(将第17位置0),在本链的规则执行完毕后,会判断标记是否match(判断第17位是否有被置1),不匹配(没有被置1)就DROP;
第4条:如果该网卡对应的pod有相关的networkpolicy,要再打一次mark,与之前的mark做与计算后目前mark应该是0xfffcffff(17、18位为0);
第5条:如果包mark match 0x0/0x20000(第18位为0), 执行
cali-pi-_QW8Cu1Tr3dYs2pTUY0-
链进入networkpolicy的判断。第6、7条:如果networkpolicy检查通过,会对包进行mark修改, 所以检查是否mark match 0x10000/0x10000, 匹配说明通过,直接RETURN,不再检查其他的规则;如果mark没有修改,与原先一致,视为没有任何一个networkpolicy允许该包通过,直接DROP
第8、9、10、11条:当没有任何相关的networkpolicy时(即第4~7条不存在)才会被执行,执行calico的 profile 策略,分成namespace维度和serviceaccount维度,如果在这两个策略里没有对包的mark做任何修改,就表示通过。这两个策略是calico的概念,且为了不与networkpolicy混淆,已经被弃用了。因此此处都是空的。
第12条:如果包没有进入 上述两个profile链,DROP。
接着看networkpolicy的链 cali-pi-_QW8Cu1Tr3dYs2pTUY0-
,只要在这个链里执行Return前有将包打上mark使其match 0x10000/0x10000,就表示匹配了某个networkpolicy规则,包允许放行:
Chain cali-pi-_QW8Cu1Tr3dYs2pTUY0-(1 references)
target prot opt source destination
MARK all -- anywhere anywhere /* cali:fdm8p72wShIcZesY */ match-set cali40s:9WLohU2k-3hMTr5j-HlIcA0 src MARK or0x10000
RETURN all -- anywhere anywhere /* cali:63L9N_r1RGeYN8er */ mark match 0x10000/0x10000
MARK all -- anywhere anywhere /* cali:xLfB_tIU4esDK000 */ MARK xset 0x40000/0xc0000
MARK all --10.16.2.122 anywhere /* cali:lUSV425ikXY6zWDE */ MARK and0xfffbffff
MARK tcp --10.16.2.0/24 anywhere /* cali:8-qnPNq_KdC2jrNT */ multiport dports 3456 mark match 0x40000/0x40000 MARK or0x10000
RETURN all -- anywhere anywhere /* cali:dr-rzJrx0I6Vqfkl */ mark match 0x10000/0x10000
第1、2条:如果src ip match ipset:
cali40s:9WLohU2k-3hMTr5j-HlIcA0
,将包 mark or 0x10000, 并检查是否match,match就RETUR。我们可以在机器上执行ipset list cali40s:9WLohU2k-3hMTr5j-HlIcA0
, 可以看到这个ipset里包含的就是networkpolicy中指明的、带有hyapp=client1
这个label的两个pod的ip。第3、4、5、6条则是针对networkpolicy中的第二部分规则,先对包设置正向标记,然后将要隔离的src IP/IP段进行判断并做反向标记,接着判断src段是否在准入范围,如果在,并且目的端口匹配,并且标记为正向,就再对包进行MARK or 0x10000 , 这样,最终判断match了就会Return。
实际上我们可以看到,这里就算不match,这个链执行完了也还是会RETURN的,所以这个链执行的结果是通过mark返回给上一级的,这就是为什么调用该链的上一级,会在调用完毕后要判断mark并确认是否ACCEPT。
至此,一个完整的networkpolicy的实现链路就完成了。
egress规则与上述ingress规则类似。可以参考下图:
未完待续
本文作者:黄扬,网易数帆轻舟事业部工程师
活动预告:3月26日 19:00-20:30,Istio社区成员、网易数帆轻舟事业部架构师于禁,网易数帆轻舟事业部系统开发专家虎啸,两位专家将分别带来《Slime:让Istio服务网格更加高效与智能》和《轻舟微服务网络数据面进阶之路》的直播分享,欢迎点击左下角阅读原文获取直播链接。
