01
Collect阶段
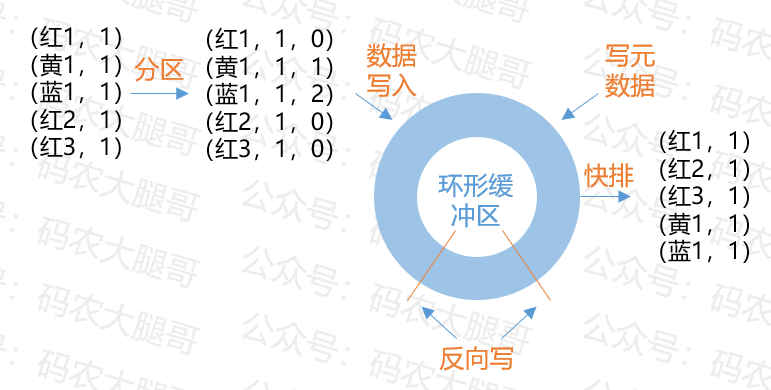
map()方法将数据处理成了(key,value)形式,然后输入到环形缓冲区,在这个过程中经历了以下几步

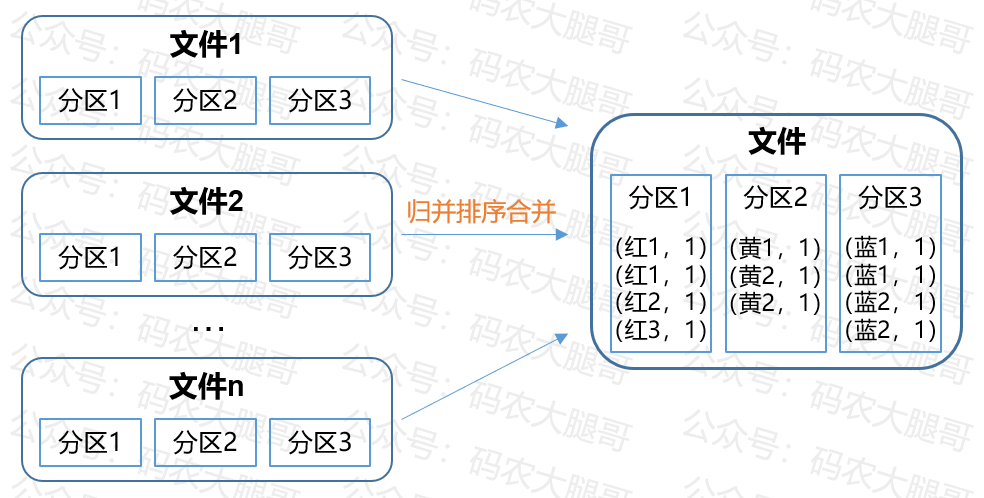
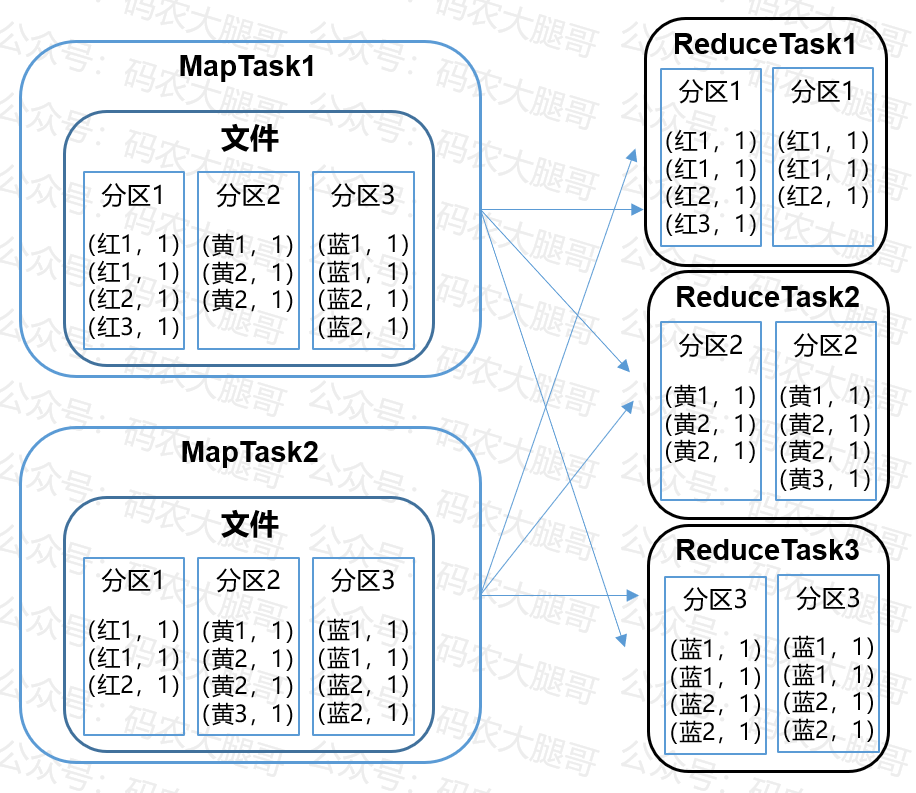
ReduceTask将拉取过来的所有文件进行合并,采用归并排序进行排序,得到最终的同一分区的排好序的数据

合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程
文章转载自码农大腿哥,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





01
Collect阶段
map()方法将数据处理成了(key,value)形式,然后输入到环形缓冲区,在这个过程中经历了以下几步
合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程
