近年来关于大数据的话题越来越火热,那么什么是大数据?
大数据(Big Data),就是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
在大数据技术中大数据平台的搭建是必不可少的,从今天开始小编就手把手带大家搭建大数据平台。但在搭建平台之前首先要准备主机(简单说就是电脑),在实际的生产环境中不可能是一台主机的,但是考虑是学习的情况下我们需要准备一台配置为8代CPU、8GB内存、256GB硬盘或更高配置的电脑来搭建一个伪分布式大数据平台。
VMware Workstation Pro 15VMware Workstation(中文名“威睿工作站”)是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案。VMware Workstation可在一部实体机器上模拟完整的网络环境,以及可便于携带的虚拟机器,其更好的灵活性与先进的技术胜过了市面上其他的虚拟计算机软件。对于企业的 IT开发人员和系统管理员而言, VMware在虚拟网路,实时快照,拖曳共享文件夹,支持 PXE 等方面的特点使它成为必不可少的工具。[1]首先要安装好虚拟机软件VMware Workstation Pro 15,具体安装过程这里就不详细说明,安装完成后打开VMware Workstation Pro,依次点击菜单栏中 编辑-虚拟网络编辑器 配置虚拟机网卡,具体步骤如下点击图片上方网卡名称中的VMnet8并配置下方的子网IP和子网掩码,子网IP更改为192.168.100.0 ,子网掩码更改为255.255.255.0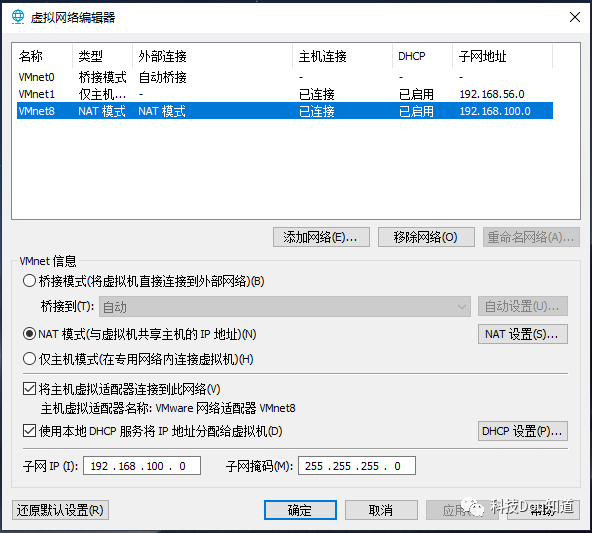
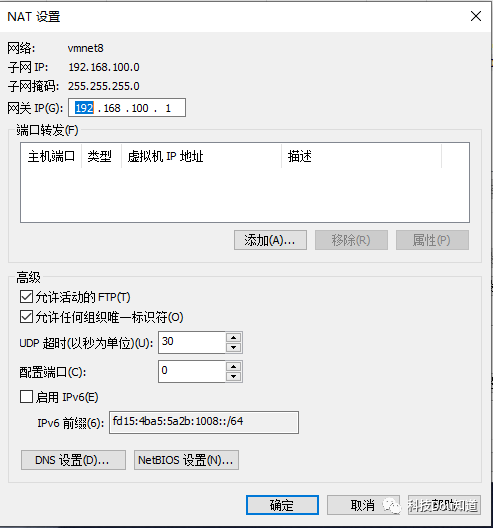
点击上一个图片中部的NAT设置,并配置网关为192.168.100.1,之后点击确定
接着点击第一张图片下方的DHCP设置,并配置起始IP地址和结束IP地址,分别为192.168.100.50和192.168.100.254,然后点击确定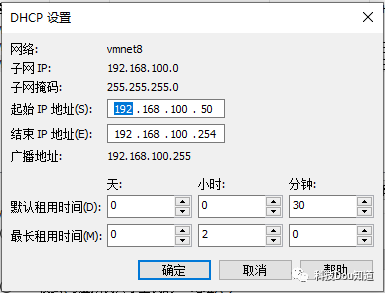
最后点击确定,这样虚拟机网卡就配置好了,接下来安装系统,依次点击菜单栏中 文件-新建虚拟机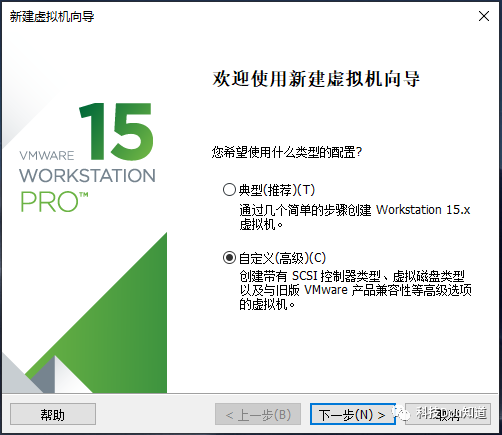
修改虚拟机名称为master并指定一个位置(默认位置就可以),然后点击下一步
配置I/O控制器类型,这个默认就可以,然后点击下一步
配置虚拟磁盘类型,这个选择默认配置,然后点击下一步
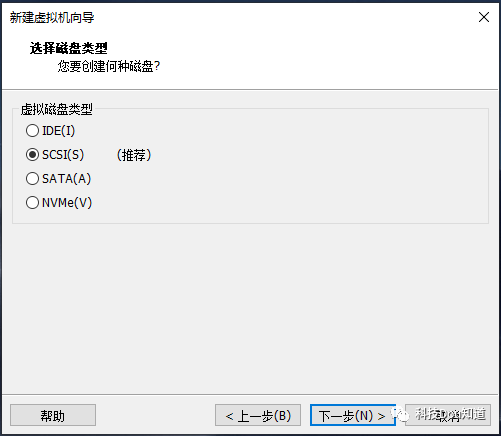
选择磁盘,选择第一个创建新虚拟磁盘,然后点击下一步
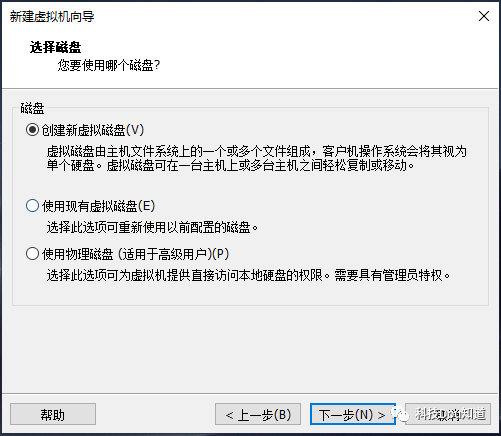
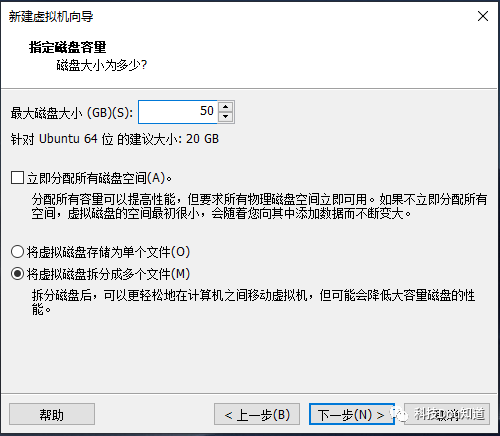
配置磁盘容量为50GB并将虚拟磁盘拆分为多个文件,然后点击下一步
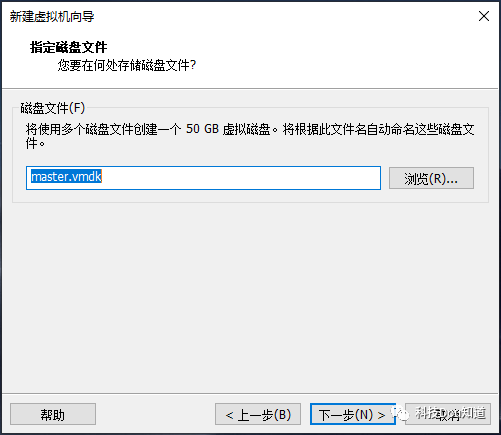
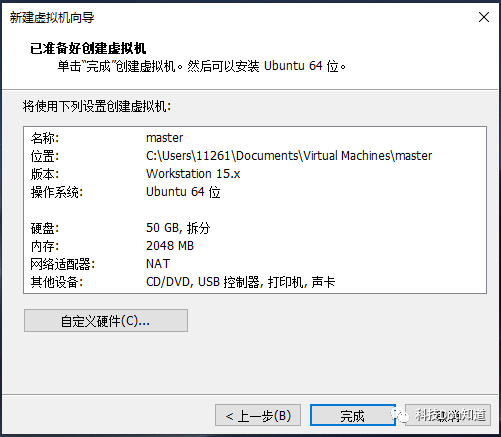
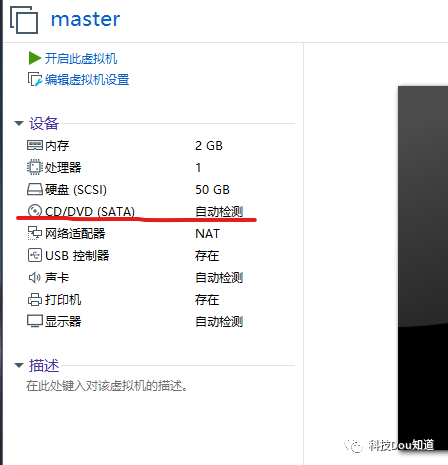
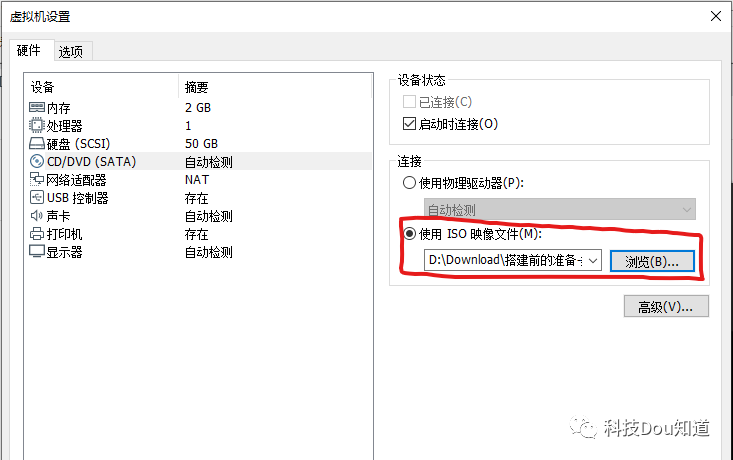
点击左侧开启此虚拟机进入系统安装界面,选择English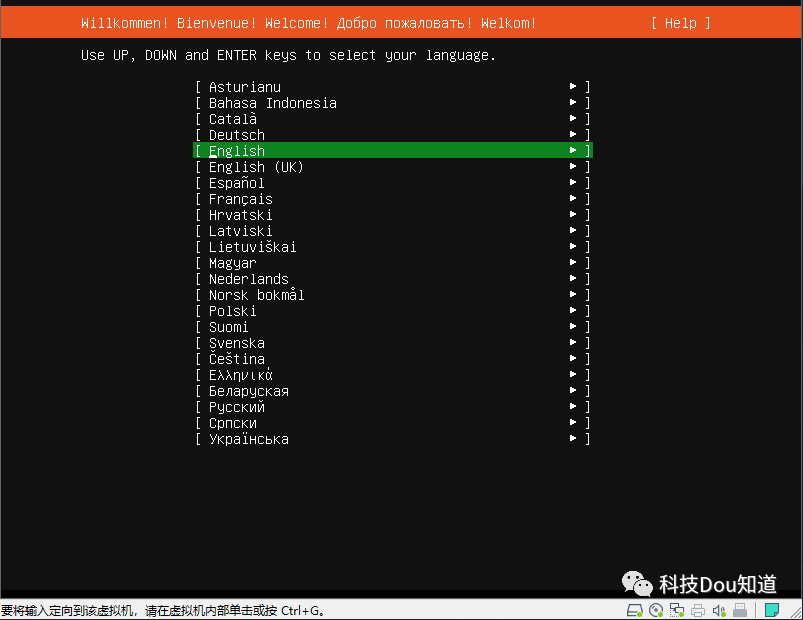
网卡配置,这里直接点击Done,在系统安装好后我们再进行配置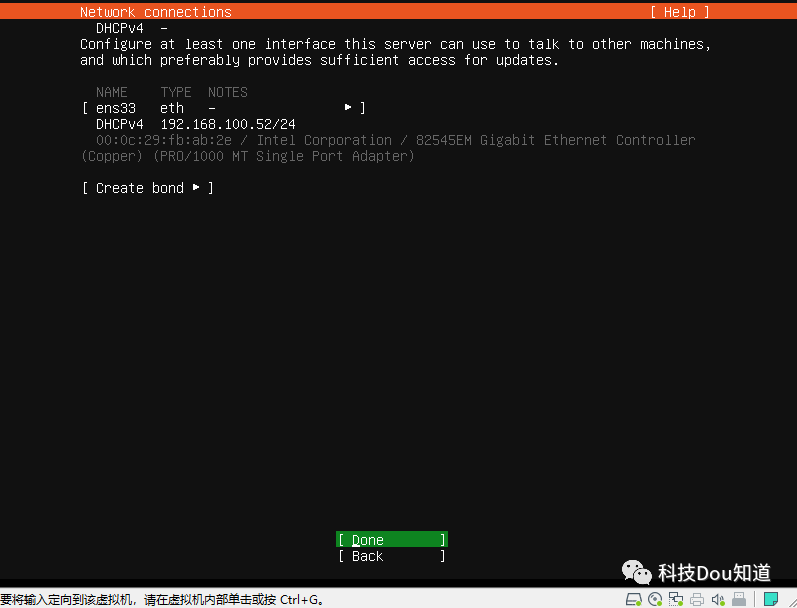
这里设置镜像源,采用阿里云提供的镜像源 http://mirrors.aliyun.com/ubuntu ,然后点击Done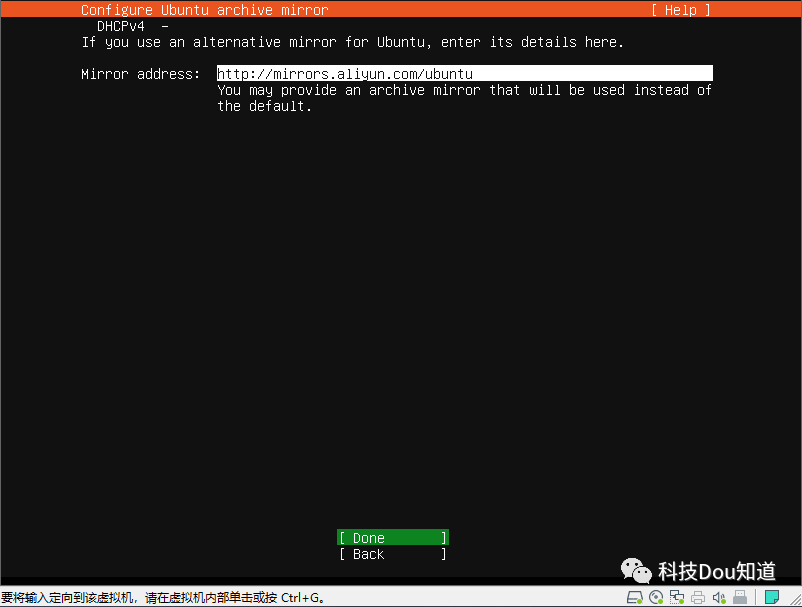
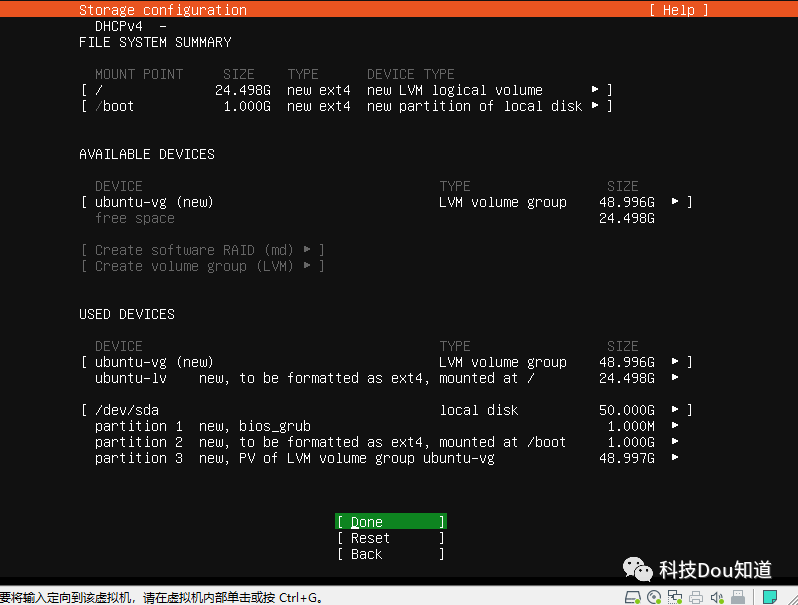
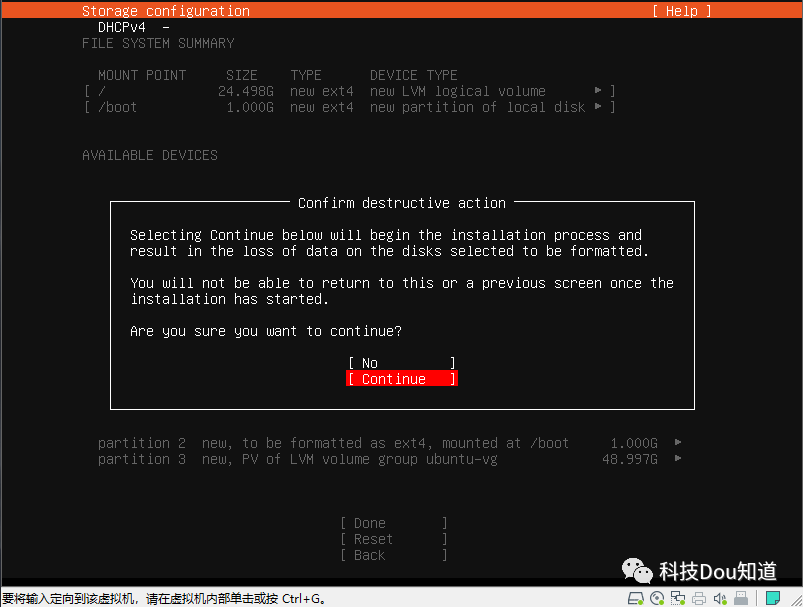
接下来是选择硬盘,一路点击Done并Continue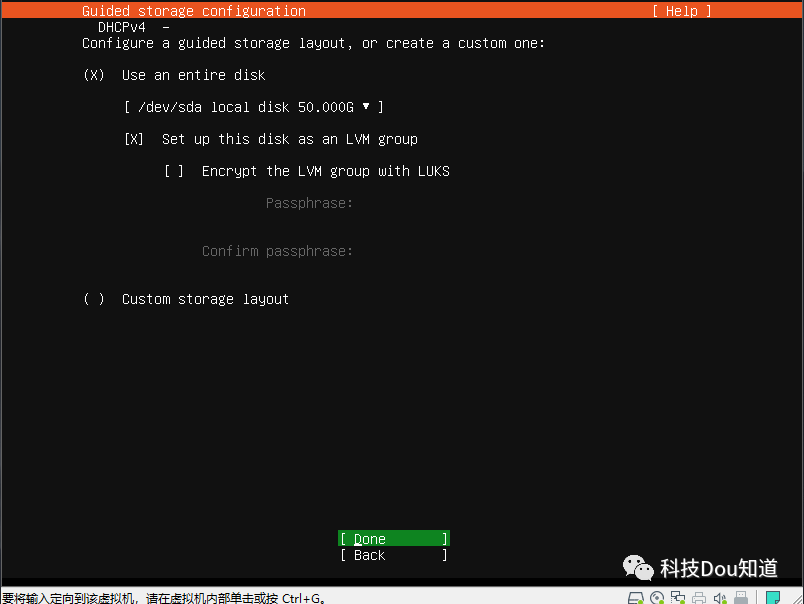
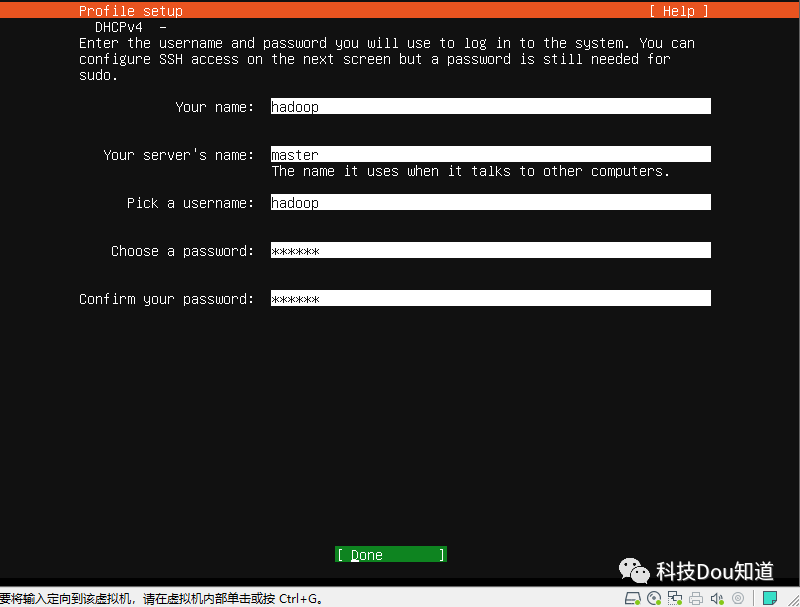
设置用户名、主机名及用户密码,下面图片中从上往下依次填写 hadoop ;master ;hadoop ;123456 ;123456 ,然后点击Done
选中 Install OpenSSH server 并点击Done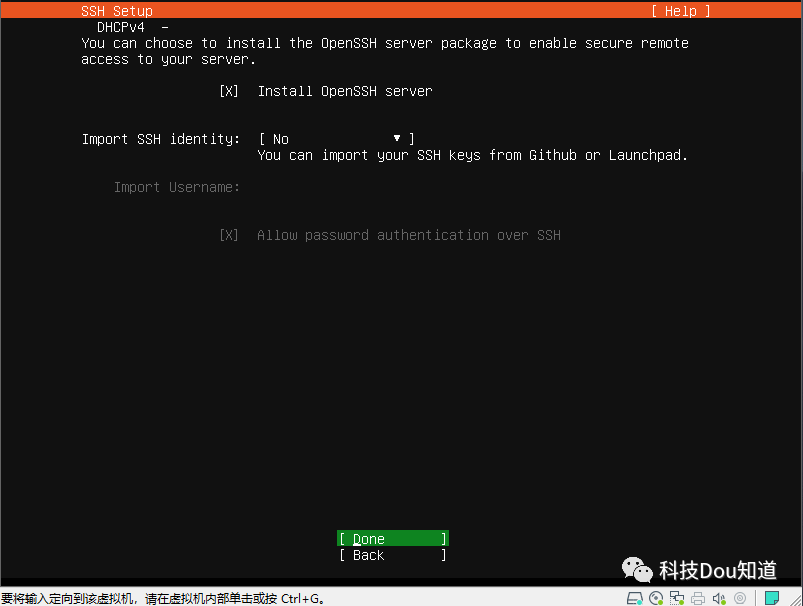
当下方出现 Cancel update and reboot 时立即点击它,取消系统更新并重新启动
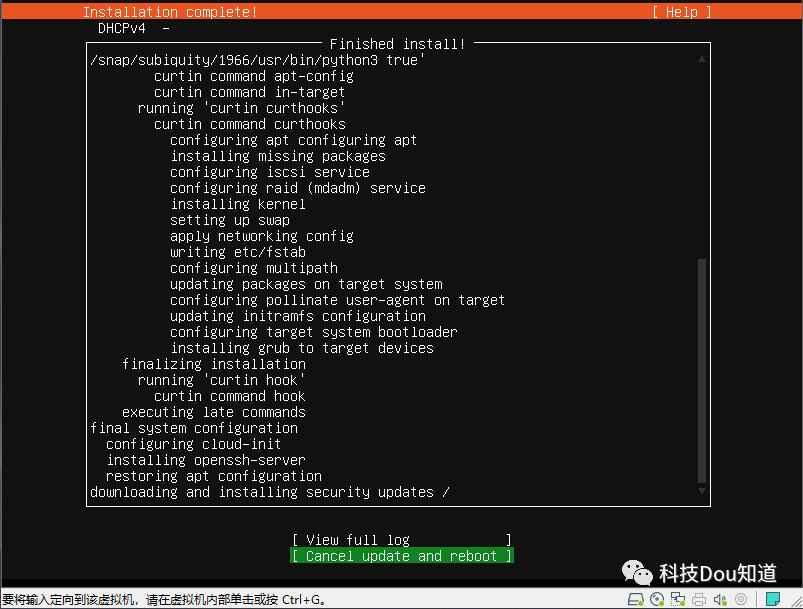
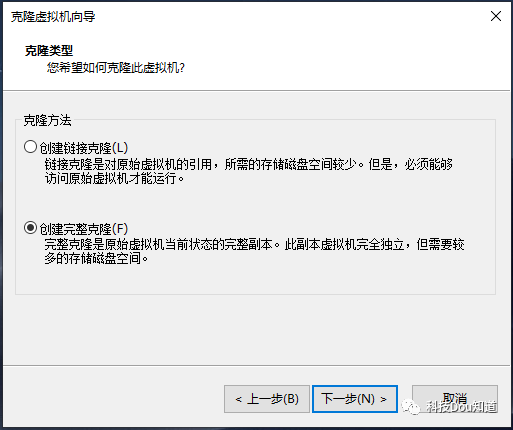
这时系统已经安装完毕了,之后会提示你推出安装盘并点击ENTER,这时直接点击ENTER即可,系统就会自动重启,等待进入系统后输入用户名hadoop和密码123456,并请执行 $ sudo poweroff 命令来关机,这时会让你输入用户密码123456,输入后即可关闭。我们知道部署大数据平台不只是一台主机,然而现在我们只安装好了一台,接下来就要重复我们刚才的操作,再次安装2台主机,毫无疑问这是很繁琐的,因此我们使用虚拟机中特有的功能-克隆虚拟机,根据master主机直接克隆出2台就好了,详细操作步骤如下。依次点击菜单栏中 虚拟机-管理-克隆 ,出现克隆向导后点击下一步
更改虚拟机名称为slave1并设置位置(默认就可以),然后点击完成
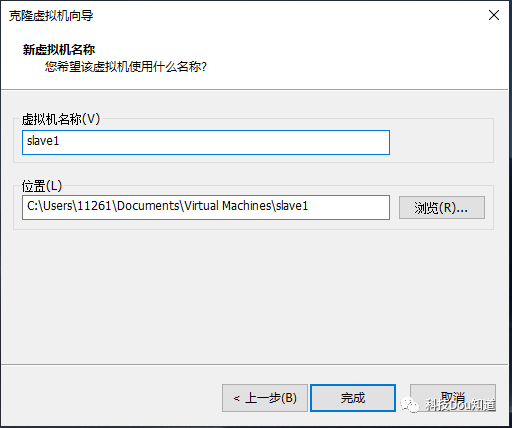
这样我们就根据master主机克隆出了一台名称为slave1的主机,同样地,我们使用相同的操作再次克隆出一个名称为slave2的主机,这里重复的操作就不再展示。
启动3台主机并使用hadoop用户名登录,首先配置master主机,执行
$ sudo vim etc/netplan/00-installer-config.yaml
修改为以下配置
# This is the network config written by 'subiquity'
network:
ethernets:
ens33:
dhcp4: false
addresses: [192.168.100.101/24]
gateway4: 192.168.100.1
nameservers:
addresses: [114.114.114.114]
version: 2
接下来使网卡配置生效
同样地,配置slave1主机和slave2主机,唯一不同的是配置文件中addresses参数分别为[192.168.100.102/24]和[192.168.100.103/24]。为什么要设置主机名呢?这是因为在根据master主机克隆的同时把主机名也克隆了,这就导致slave1主机和slave2主机的主机名也为master,因此要进行配置,在slave1上执行以下命令并修改master为slave1同样地,在slave2主机上要修改为slave2,为了生效配置我们要执行 sudo reboot 命令重启slave1主机和slave2主机。127.0.0.1 localhost
192.168.100.101 master
192.168.100.102 slave1
192.168.100.103 slave2
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
$ ssh-keygen
$ ssh-copy-id master
其中执行 $ ssh-keygen 命令后一路按ENTER即可,执行$ ssh-copy-id master 命令时要输入master主机hadoop用户的密码。$ scp ~/.ssh/authorized_keys slave1:~/.ssh/
$ scp ~/.ssh/authorized_keys slave2:~/.ssh/
与此同时系统会让输入slave1主机和slave2主机hadoop用户的密码,这样ssh免密功能就配置好啦,可以在master上尝试 $ ssh slave1 命令 和 $ ssh slave2 命令进行验证是否为免密登录。做完以上操作后系统的准备工作就做好了,但实际在操作主机时是不会真的在主机上操作,而通常是通过一个远程连接软件来操作主机的,那么我们就来使用XShell软件实现远程登录。
为了以后操作方便,我们首先为宿主系统配置主机名映射,使用文本编辑器打开 C:\Windows\System32\drivers\etc\host 文件并在文件末尾添加以下配置并保存退出192.168.100.101 master
192.168.100.102 slave1
192.168.100.103 slave2
接下来打开XShell软件,依次点击菜单栏 文件-新建 ,弹出一个对话框后设置名称和主机都为master,然后直接点击连接,最后输入用户名和密码即可成功连接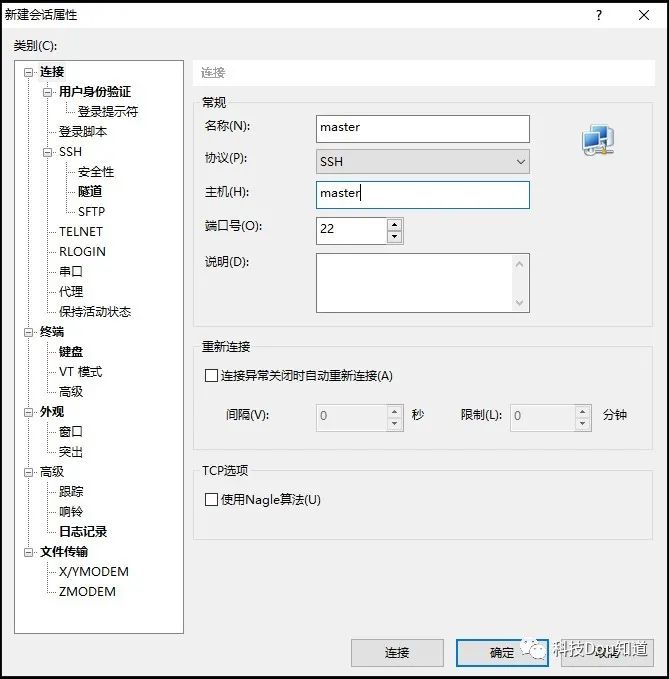
salve1主机和slave2主机同样进行连接,以后搭建集群直接开启虚拟机然后使用XShell远程连接操作即可。为了使搭建逻辑更清晰我们分别在3台主机上的~目录(/home/hadoop目录)下建立 software 和 servers 两个文件夹,software目录用于存放软件包,servers目录用于存放服务安装位置。到这里,部署集群前的准备就已经完成了,若想要获得本页中所用到的软件及系统请在公众号后台回复关键词 准备 最后别忘了关注一下公众号哦
参考:
[1] https://baike.baidu.com/item/VMware%20Workstation
编辑:蔡猛
声明:
1.本公众号所转载文章均来自公开网络,仅供学习交流使用,不会用于任何商业用途。
2.如果出处标注有误或侵犯到原著作者权益,请联系 @caimeng99526 删除,谢谢。
3.转载本公众号中的文章请注明原文链接和作者,否则产生的任何版权纠纷均与本公众号无关。






