




Apache Kylin™是一个开源的、分布式的分析型数据仓库系统,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
定义数据集上的一个星形或雪花型模型
在定义上的数据表上构建cube
使用标准SQL通过ODBC、JDBC或RESTFUL API进行查询,仅需亚秒级响应时间即可获得查询结果 (由此能感受到麒麟的牛逼吗)
Kylin架构
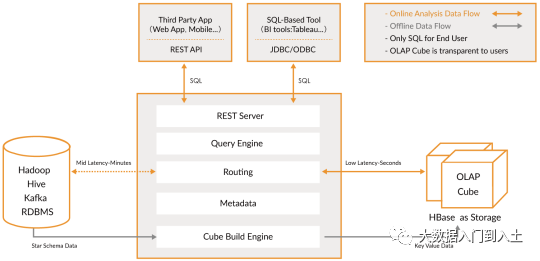
RestServer:负责对外提供http请求接口
QueryEngine:解析query sql语法
Routing:路由选择(低延迟路径:从cube中取现成结果;中延迟路径:MapReduce临时计算)
Metadata:kylin自身的元数据管理模块
Cube Build Engine:cube引擎
Kylin安装
kylin的安装机器上,必须有如下软件包及环境变量
vi /ect/profileexport JAVA_HOME=export HADOOP_HOME=export HIVE_HOME=export HBASE_HOME=export KYLIN_HOME=export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin##至于SPARKSPARK_HOME和FLINK_HOME可以不配置,看自己用啥执行计算引擎
修改hbase-site.xml,将zookeeper地址中端口号去掉
<property><name>hbase.zookeeper.quorum></name><value>bigdata01,bigdata02,bigdata03</value></property>
检查运行环境
${KYLIN_HOME}/bin/check-env.sh
最后就是启动kylin
${KYLIN}/bin/kylin.sh start
功能总览:
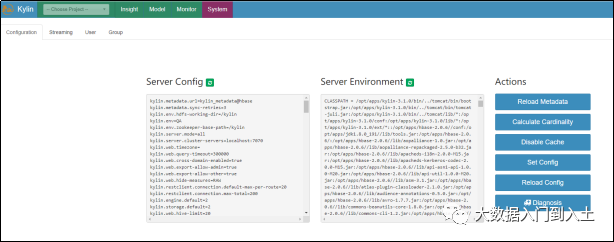
Insight:查询平台
Model:模型定义管理平台
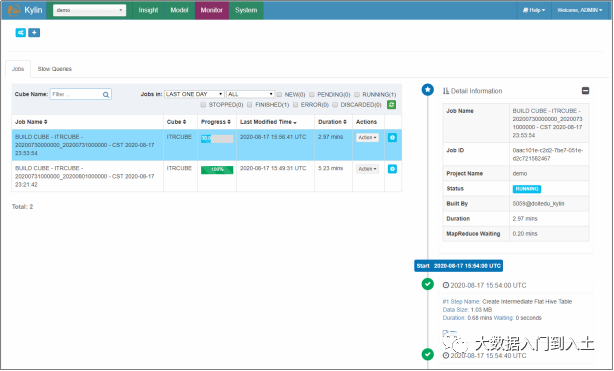
Monitor:构建任务监控平台
System:系统管理(参数配置,缓存禁用,维度基数计算等)
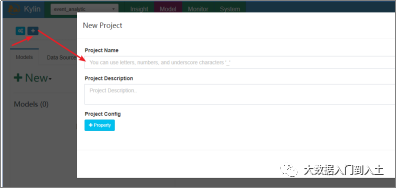
1.1.1 创建工程
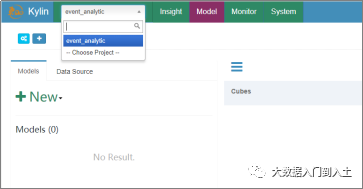
然后选择你要操作的工程
1.1.2 导入数据源
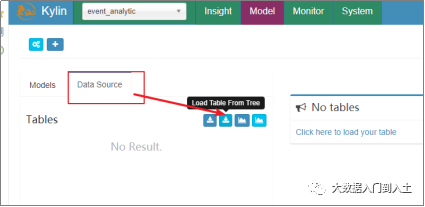

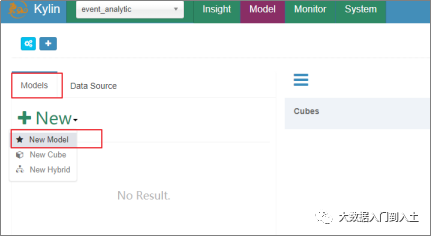
1.1.3 设计模型
定义一个星型或者雪花模型(指定事实表,指定维度表)
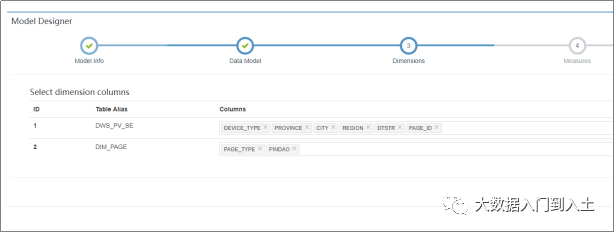
选择维度
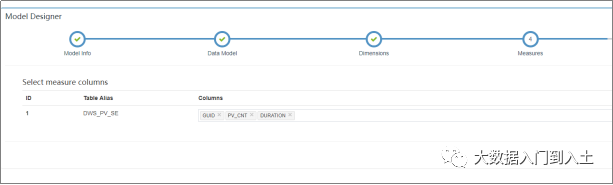
选择度量
1.1.4 Cube构建
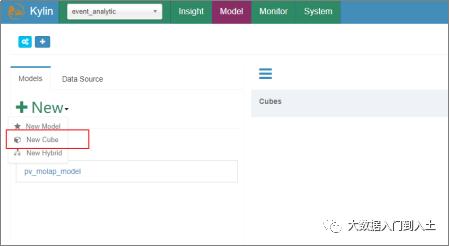
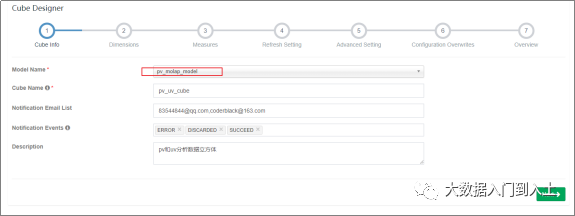
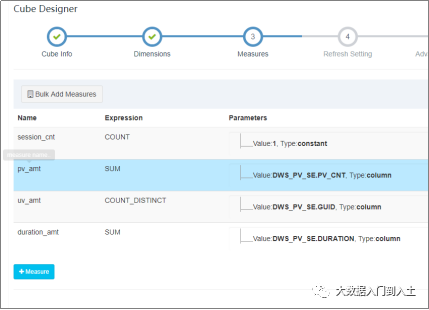
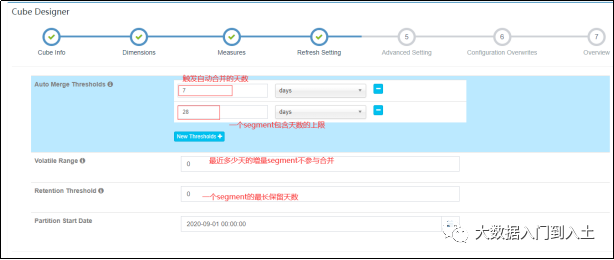
设计聚合指标
文章转载自大数据入门到入土,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
