




点击蓝色字 免费订阅,每天收到这样的好信息
免费订阅,每天收到这样的好信息
前面一段时间已经学完了HDFS,这个阶段我们开始深入学习MapReduce。上一篇文章小编主要讲了一下InputFormat数据输入。今天,我们继续学习MapReduce框架原理,这篇文章讲解的内容是:MapReduce工作流程,下面就开始今天的内容吧。
1. 流程示意图,如下面2幅图所示
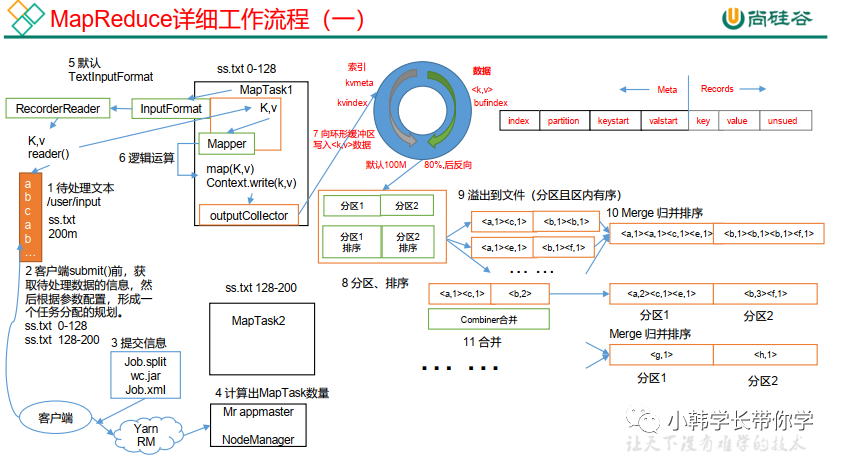 MapReduce详细工作流程(一)
MapReduce详细工作流程(一)
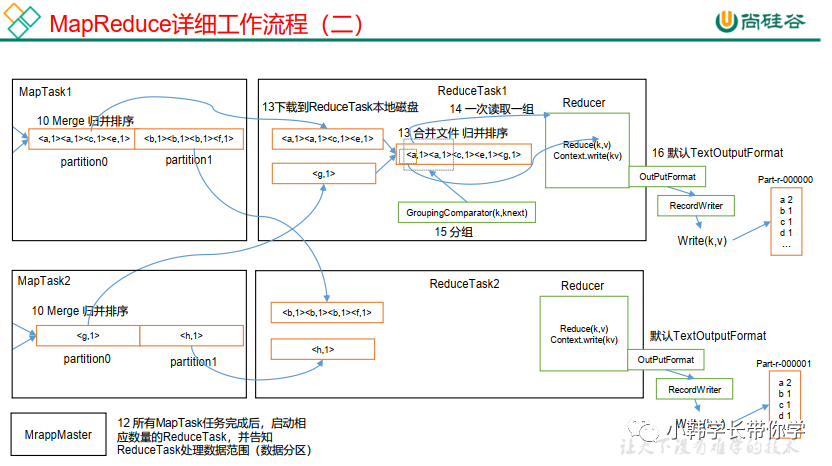
MapReduce详细工作流程(二)

context.write(k, NullWritable.get());output.write(key, value);collector.collect(key,value,partitioner.getPartition(key, value, partitions));HashPartitioner();collect()close()collect.flush()sortAndSpill()sort() QuickSortmergeParts();collector.close();

▲ 公众号:小韩学长带你学,带你学习更多知识

▲ 小韩学长店铺,好货带你来购

点个在看你最好看
文章转载自小韩学长带你学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
