




业务发生中断或者低效
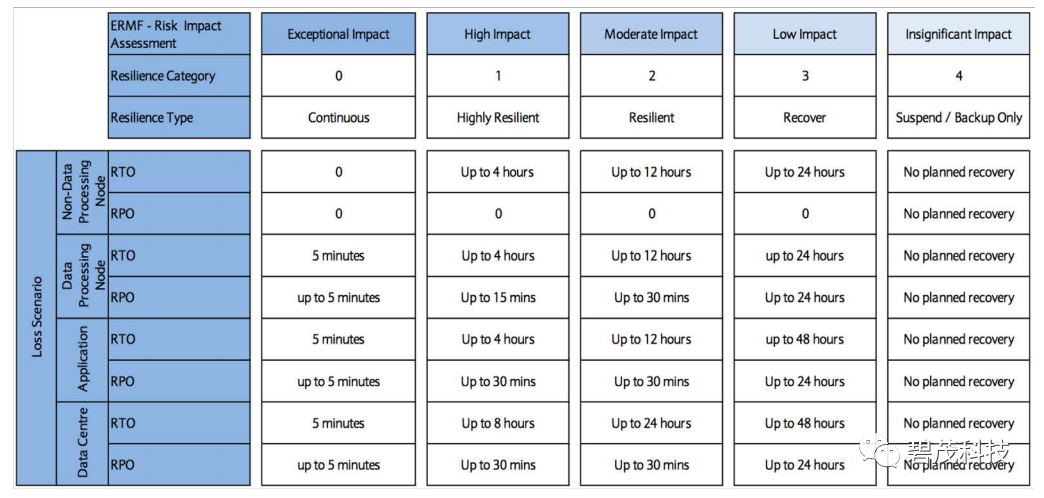
灾容指标
RTO复原时间目标:是指灾难发生后,从系统宕机导致业务停顿之刻开始,到系统恢复至可以支持业务部门运作、业务恢复运营之时,此两点之间的时间,也就是能够容忍的服务中断时间。
RPO复原点目标:是指灾难发生后,容灾系统能把数据恢复到灾难发生前时间点的数据,它是衡量企业在灾难发生后会丢失多少生产数据的指标,也就是在一次服务失败之后,能够容忍的数据丢失量。
灾容级别
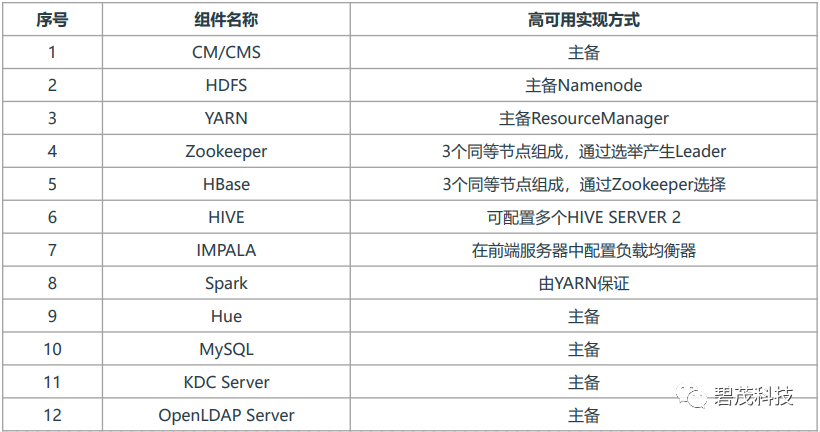
级别3~4
方案:建议启用Hadoop组件高可用
级别1~2
方案:建议使用Cloudera BDR
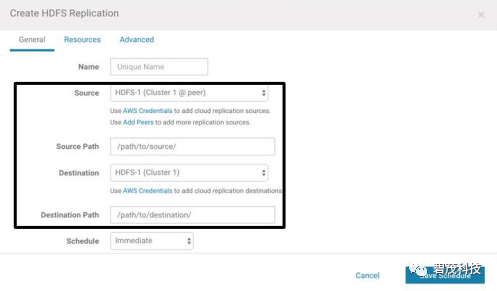
Cloudera Manager使用管理员能够选择需要复制的关键数据集,创建数据复制的计划,监控活动复制作业的进度以及在复制作业失败时发出警报
Cloudera建议设置复制计划以满足应用程序的RPO
Cloudera建议同时考虑复制作业所需的数据量和时间
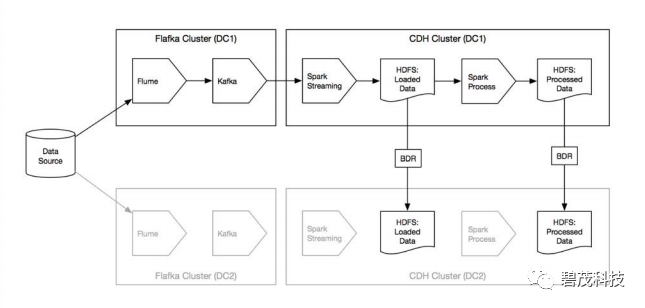
级别0
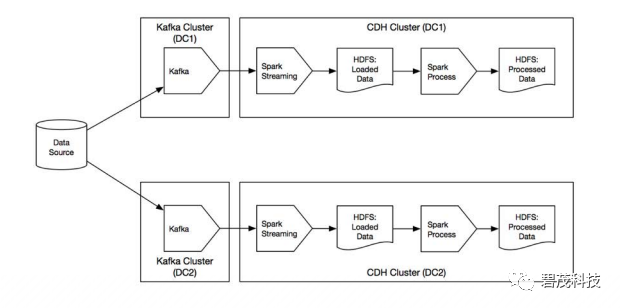
方案1:双加载:向多个集群并行导入数据
源系统可以向多个站点发送数据
如果数据流向发生分歧,有调节作业进行干预
使用单独的Kafka和Flume实例将数据流式传输到多个集群(也即,每个站点有一个Kafka群集,但没有跨站点topic复制)
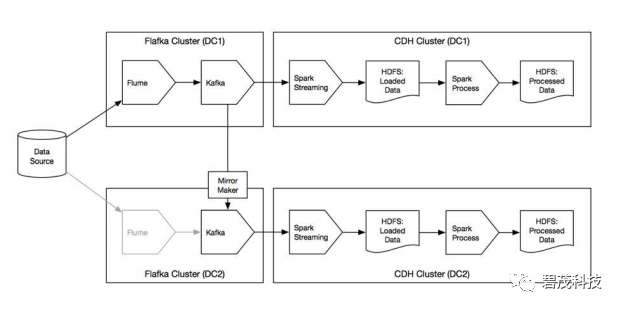
方案2:流复制:使用Kafka MirrorMaker进行跨站点topic复制
源数据发布后写入活跃站点的Kafka,MirrorMaker用于将这些数据(几乎实时)复制到第二个站点中的单独Kafka集群。每个站点中的Hadoop集群都使用来自其本地Kafka topic的数据
上游源系统必须在任何给定时间检测活动站点,如果发生故障,将触发故障转移到第二个站点,一旦故障站点恢复,MirrorMaker将转向两一个方向复制数据。
下游客户也必须能够在任何给定时间检测哪个站点处于活动状态。
集群元数据备份策略
| 元数据类型 | 作用 | 存储方式 | 备份方式 | 备份周期 |
| HDFS文件元数据 | 记录HDFS文件分布、目录结构等,是平台上最重要的数据 | namenode节点本地磁盘 | 自身高可用同步到备节点 | 秒级 |
| 备份文件夹 | 一天 | |||
| 用户认证数据 | 记录平台上允许登录的用户信息 | Kerberos+LDAP自动文件存储 | Kerberos主备同步 | 秒级 |
| LDAP主备同步 | 秒级 | |||
| 备份数据文件 | 一天 | |||
| Cloudera Manager配置数据 | 记录平台上的所有配置,包括服装分布、节点信息和所有组件的配置 | 外部数据库 | 数据库主备同步 | 秒级 |
| 数据库导出 | 一天 | |||
| Hive/Impala元数据 | 记录表结构信息 | 外部数据库 | 数据库主备同步 | 秒级 |
| 数据库导出 | 一天 |
数据复制
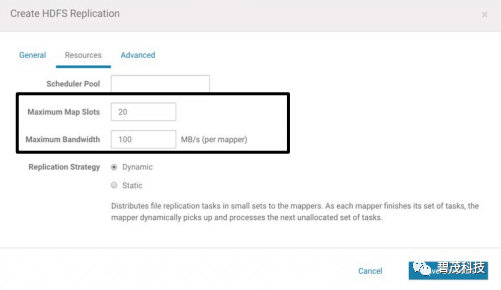
HDFS复制
复制对象为HDFS目录
通过启动多个MR作业实现并发
Pull模式
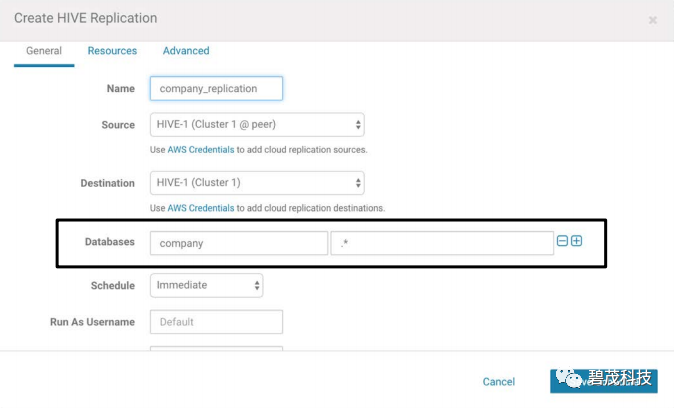
Hive复制
复制对象为Hive表
包括HDFS数据和元数据
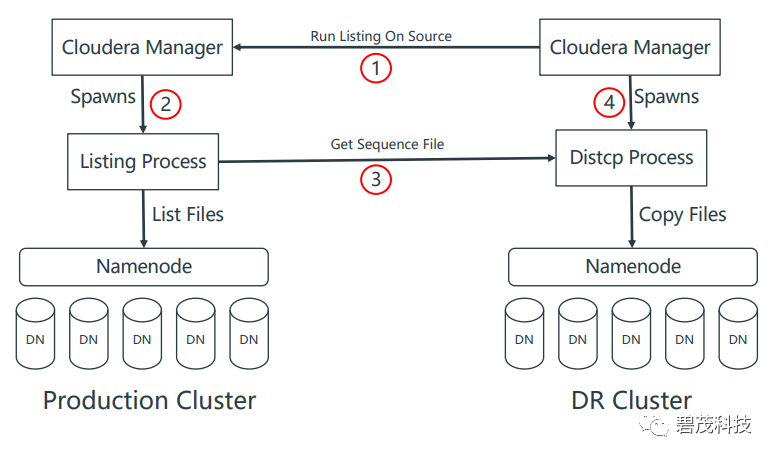
亮点1 文件清单获取
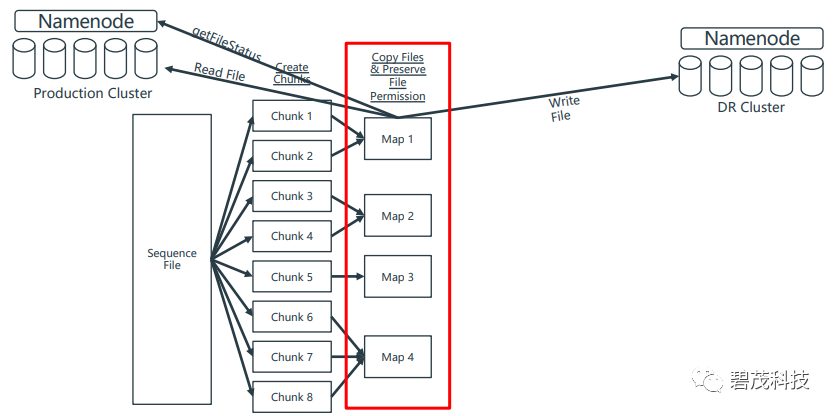
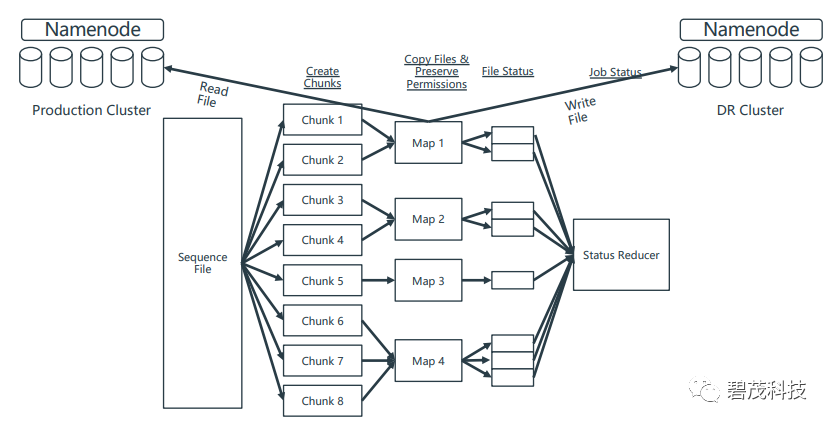
亮点2 MAPPER分工
亮点3 减少CRC校验
亮点4 保留目录权限
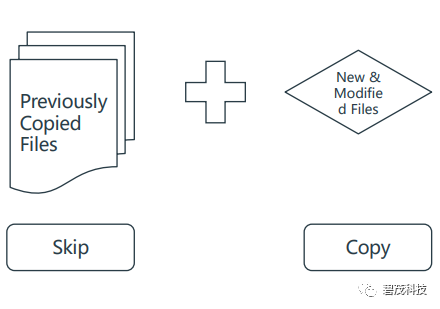
亮点5 通过SNAPSHOTDIFF实现增量复制
SnapshotDiff仅报告修改的文件
以前复制/未更改的文件不会被检查
重命名的文件不会被复制
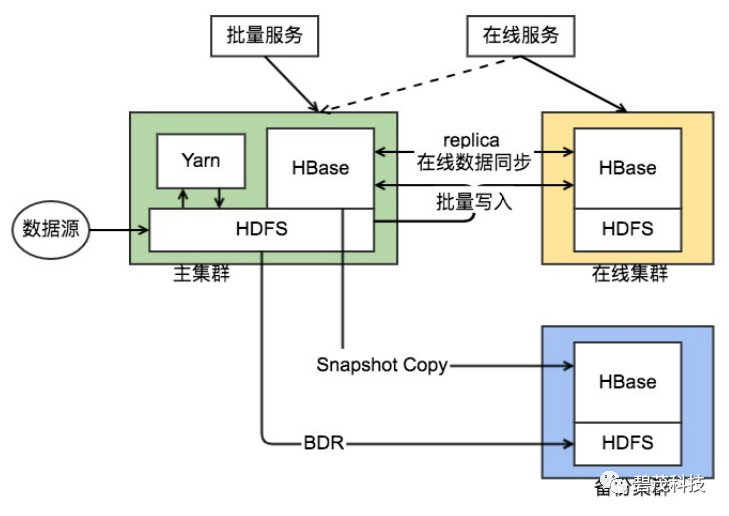
光大银行数据备份架构
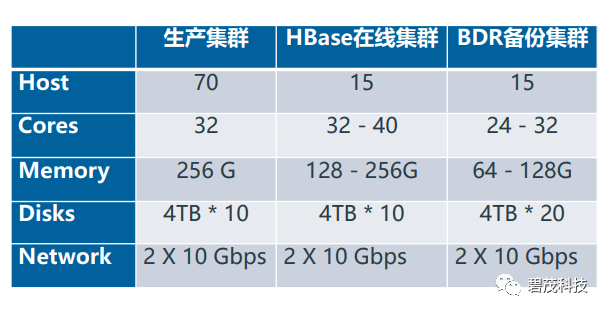
集群用途描述
集群配置说明
对于BDR集群,需要大容量的机器但是可以适当减少计算能力
对于Hbase在线集群,主要需要使用Hbase上的查询服务而不需要进行批量任务,节点可以适当减少内存,但是依旧需要保证IO以提供足够的查询性能
何时切换到BDR备份集群?

BDR备份集群切换过程
确认之前任务的时间点:
查看任务的运行日志,成功任务的完成时间点
从上一次备份时间点开始,到上一次任务完成的时间,重新接入这部分数据
将重要的新数据临时接入到备份集群
对外提供较为重要的服务
停止剩下的主集群服务:
在由备份集群提供服务之前,需要保证目前不会有应用依旧在当前的主集群,防止获取错误的数据
启用备份集群上的服务:
启用业务服务,并且启动在新集群上的任务
何时切换到HBASE在线集群
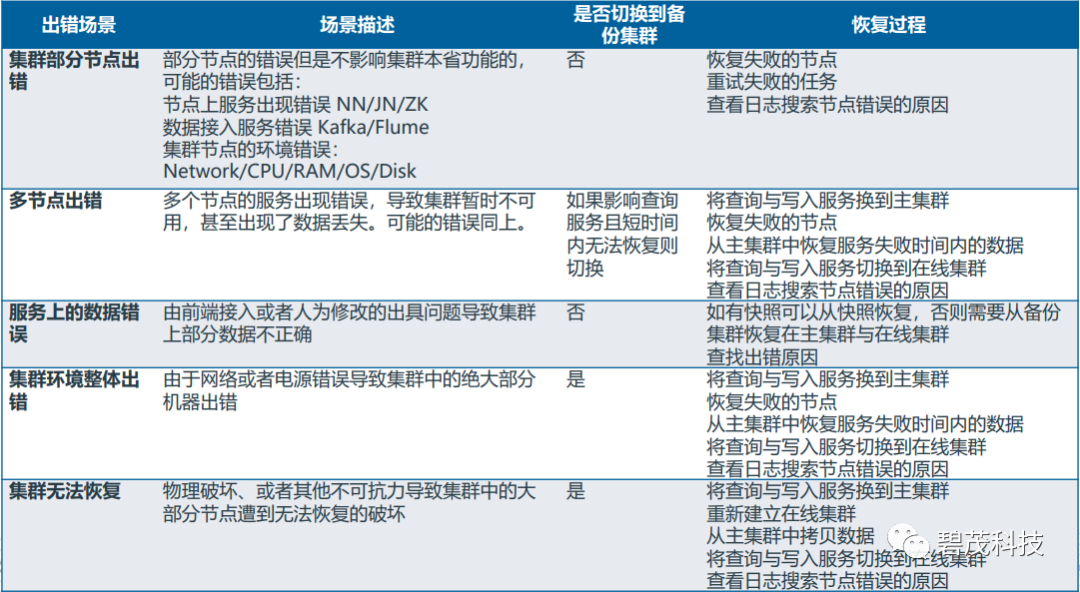
HBASE在线集群切换过程
为了能够保证查询服务:
将查询服务的目标集群放置到主机群的Hbase,如果同步配置正确主集群应该有几秒之前的完整数据
确认并且记录出错时间点
如果能确认在线写入的未完成数据:
确认在线写入的数据时间点,如果可以再主机群中尝试重新写入;否则,在出错时出现的记录在在线集群会付钱可能会处于丢失状态
在线集群恢复后:
记录恢复时间点
在主集群上建立快照,通过读取快照文件将位于出错时间点与恢复时间点之间的增量数据导出然后导入到在线集群
确认在线集群数据正确,将读写服务切换到在线集群

